Zero-Shot Relational Learning for Multimodal Knowledge Graphs
2404.06220
0
0

Abstract
Relational learning is an essential task in the domain of knowledge representation, particularly in knowledge graph completion (KGC).While relational learning in traditional single-modal settings has been extensively studied, exploring it within a multimodal KGC context presents distinct challenges and opportunities. One of the major challenges is inference on newly discovered relations without any associated training data. This zero-shot relational learning scenario poses unique requirements for multimodal KGC, i.e., utilizing multimodality to facilitate relational learning. However, existing works fail to support the leverage of multimodal information and leave the problem unexplored. In this paper, we propose a novel end-to-end framework, consisting of three components, i.e., multimodal learner, structure consolidator, and relation embedding generator, to integrate diverse multimodal information and knowledge graph structures to facilitate the zero-shot relational learning. Evaluation results on two multimodal knowledge graphs demonstrate the superior performance of our proposed method.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a novel approach to zero-shot relational learning for multimodal knowledge graphs.
- The proposed method leverages both textual and visual information to extrapolate new relations between entities, even for those that have not been observed during training.
- The research aims to address the challenges of knowledge graph completion and relation extrapolation, which are important tasks in fields like question answering and recommender systems.
Plain English Explanation
Knowledge graphs are like digital maps that connect different pieces of information, such as people, places, and events, through relationships. However, these graphs often have gaps, with missing connections between entities. The authors of this paper present a new way to fill in these gaps by using both text and visual data.
Typically, methods for completing knowledge graphs rely on the information that is already available in the graph. But this can be limiting, as it's not always possible to find the missing connections just from the existing data. The researchers' approach is different - it can learn to predict new relationships even for entities that were not seen during the training process.
The key idea is to combine textual information, like the descriptions of entities, with visual data, such as images associated with those entities. By using both text and visuals, the model can better understand the underlying relationships and extrapolate new connections that were not present in the original knowledge graph.
This type of zero-shot relational learning, where the model can generalize to new entities and relations, is an important advancement in the field. It could lead to more comprehensive and accurate knowledge graphs, which in turn could improve applications like question answering and recommender systems.
Technical Explanation
The paper proposes a novel approach for zero-shot relational learning in multimodal knowledge graphs. The key components of the method are:
-
Multimodal Entity Encoding: The model encodes both textual and visual information about entities, using pre-trained language and vision models to capture semantic and visual features.
-
Relation Prediction: A relation prediction module takes the encoded entity representations and learns to predict the relationships between them, even for entity pairs that were not observed during training.
-
Zero-Shot Relation Extrapolation: The model can extrapolate to new relations by leveraging the learned representations and relational patterns, without requiring any training examples for the new relations.
The authors evaluate their approach on several benchmark datasets for knowledge graph completion and relation extrapolation. They demonstrate that the multimodal model outperforms text-only and graph-based baselines, highlighting the benefits of integrating visual information for this task.
Additionally, the paper provides insights into the model's ability to generalize to unseen relations, as well as the importance of different components, such as the visual encoder, in the overall performance.
Critical Analysis
The paper presents a promising approach for zero-shot relational learning in multimodal knowledge graphs. The key strength is the ability to leverage both textual and visual information to extrapolate new relationships, which is an important advancement compared to methods that rely solely on the existing graph structure.
However, the authors acknowledge several limitations and areas for future research:
-
Scalability: The proposed model may face challenges in scaling to very large knowledge graphs, as the relation prediction module needs to consider all possible entity pairs.
-
Interpretability: While the multimodal approach improves performance, the internal workings of the model may be less interpretable compared to purely graph-based methods.
-
Robustness: The paper does not extensively explore the model's robustness to noisy or incomplete input data, which is an important consideration for real-world applications.
-
Generalization: Further research is needed to understand the model's ability to generalize to more diverse datasets and relation types beyond the specific benchmarks used in this study.
Additionally, one could question the reliance on pre-trained language and vision models, which may introduce biases or limitations that could impact the overall performance of the zero-shot relational learning system.
Conclusion
This paper presents a novel approach to zero-shot relational learning for multimodal knowledge graphs, which leverages both textual and visual information to extrapolate new relationships between entities. The proposed method outperforms text-only and graph-based baselines, demonstrating the benefits of integrating multimodal data for this task.
The research contributes to the ongoing efforts to address the challenges of knowledge graph completion and relation extrapolation, which are crucial for advancing applications like question answering, referring expression comprehension, and few-shot relation extraction. While the paper highlights several limitations and areas for future research, the overall approach demonstrates the potential of multimodal learning for bridging the gaps in knowledge graphs and improving our understanding of the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LGMRec: Local and Global Graph Learning for Multimodal Recommendation
Zhiqiang Guo, Jianjun Li, Guohui Li, Chaoyang Wang, Si Shi, Bin Ruan
0
0
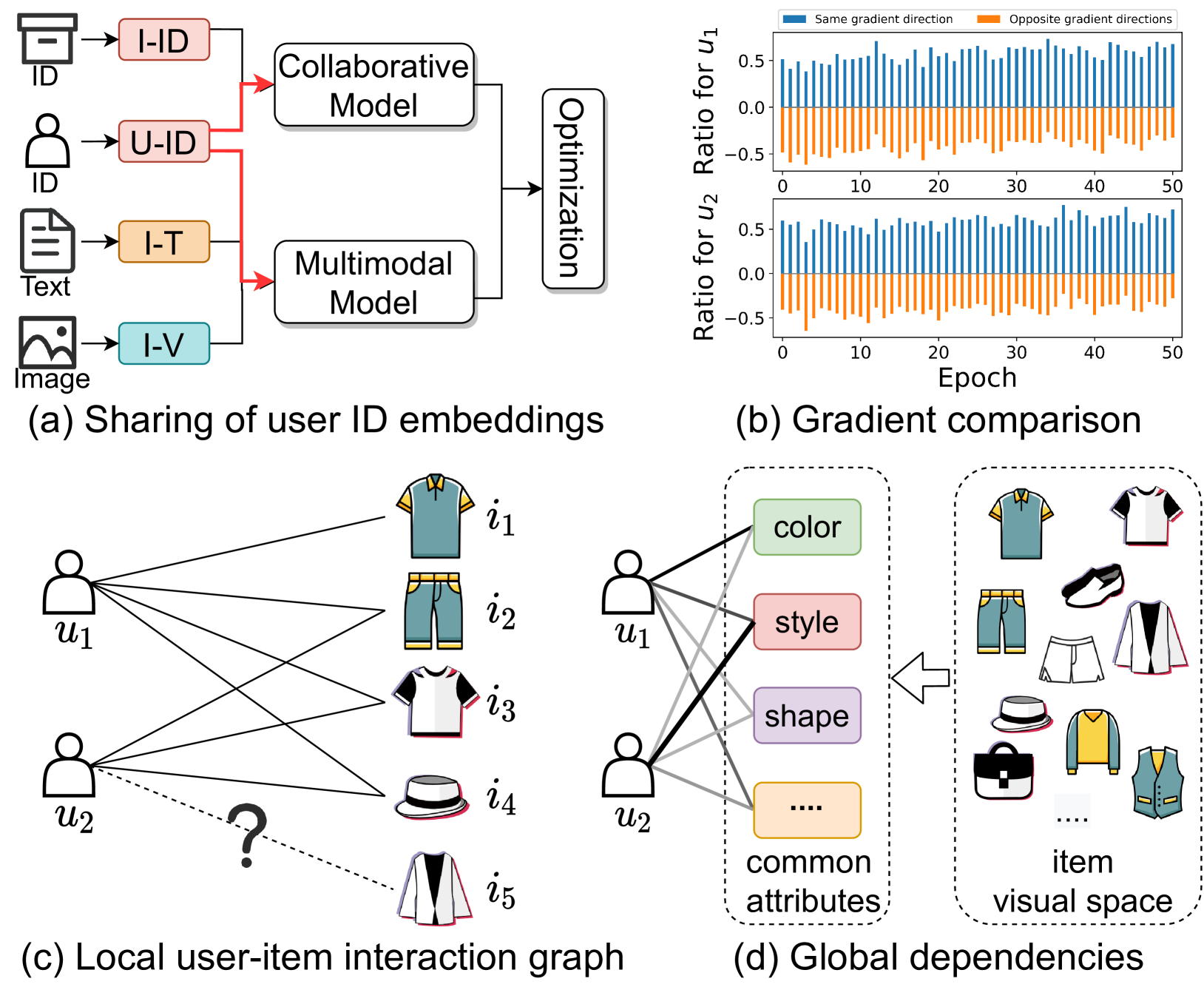
The multimodal recommendation has gradually become the infrastructure of online media platforms, enabling them to provide personalized service to users through a joint modeling of user historical behaviors (e.g., purchases, clicks) and item various modalities (e.g., visual and textual). The majority of existing studies typically focus on utilizing modal features or modal-related graph structure to learn user local interests. Nevertheless, these approaches encounter two limitations: (1) Shared updates of user ID embeddings result in the consequential coupling between collaboration and multimodal signals; (2) Lack of exploration into robust global user interests to alleviate the sparse interaction problems faced by local interest modeling. To address these issues, we propose a novel Local and Global Graph Learning-guided Multimodal Recommender (LGMRec), which jointly models local and global user interests. Specifically, we present a local graph embedding module to independently learn collaborative-related and modality-related embeddings of users and items with local topological relations. Moreover, a global hypergraph embedding module is designed to capture global user and item embeddings by modeling insightful global dependency relations. The global embeddings acquired within the hypergraph embedding space can then be combined with two decoupled local embeddings to improve the accuracy and robustness of recommendations. Extensive experiments conducted on three benchmark datasets demonstrate the superiority of our LGMRec over various state-of-the-art recommendation baselines, showcasing its effectiveness in modeling both local and global user interests.
4/19/2024
Zero-Shot Character Identification and Speaker Prediction in Comics via Iterative Multimodal Fusion
Yingxuan Li, Ryota Hinami, Kiyoharu Aizawa, Yusuke Matsui
0
0
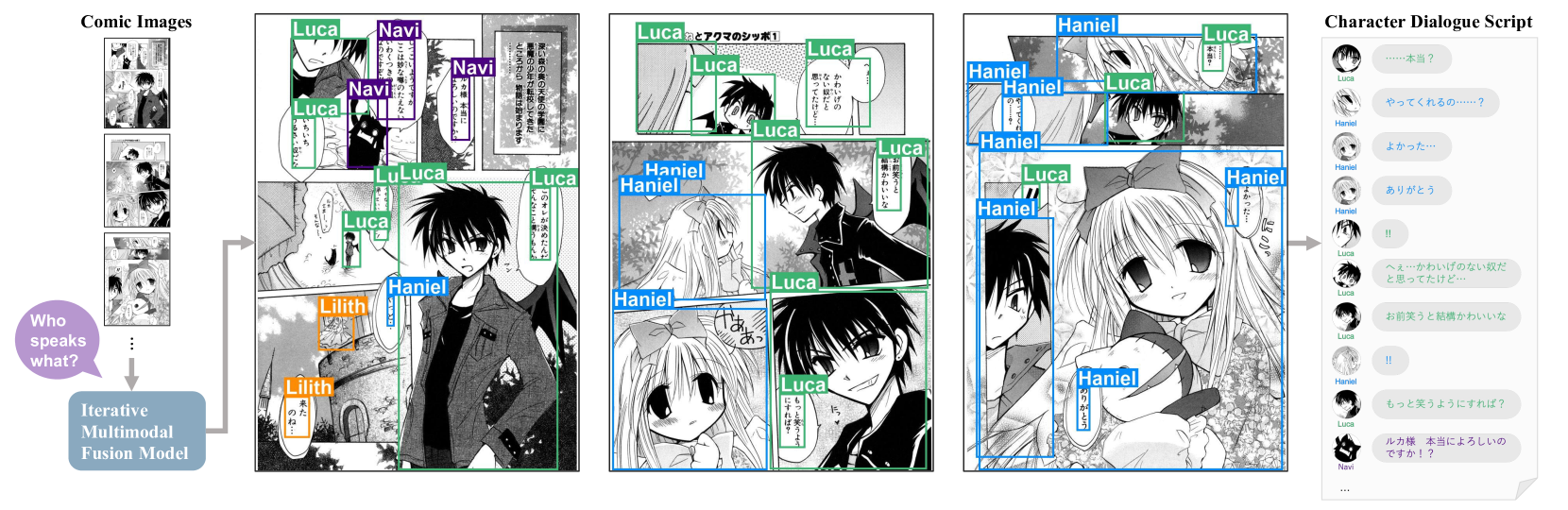
Recognizing characters and predicting speakers of dialogue are critical for comic processing tasks, such as voice generation or translation. However, because characters vary by comic title, supervised learning approaches like training character classifiers which require specific annotations for each comic title are infeasible. This motivates us to propose a novel zero-shot approach, allowing machines to identify characters and predict speaker names based solely on unannotated comic images. In spite of their importance in real-world applications, these task have largely remained unexplored due to challenges in story comprehension and multimodal integration. Recent large language models (LLMs) have shown great capability for text understanding and reasoning, while their application to multimodal content analysis is still an open problem. To address this problem, we propose an iterative multimodal framework, the first to employ multimodal information for both character identification and speaker prediction tasks. Our experiments demonstrate the effectiveness of the proposed framework, establishing a robust baseline for these tasks. Furthermore, since our method requires no training data or annotations, it can be used as-is on any comic series.
4/23/2024
💬
MM-InstructEval: Zero-Shot Evaluation of (Multimodal) Large Language Models on Multimodal Reasoning Tasks
Xiaocui Yang, Wenfang Wu, Shi Feng, Ming Wang, Daling Wang, Yang Li, Qi Sun, Yifei Zhang, Xiaoming Fu, Soujanya Poria
0
0
The rising popularity of multimodal large language models (MLLMs) has sparked a significant increase in research dedicated to evaluating these models. However, current evaluation studies predominantly concentrate on the ability of models to comprehend and reason within a unimodal (vision-only) context, overlooking critical performance evaluations in complex multimodal reasoning tasks that integrate both visual and text contexts. Furthermore, tasks that demand reasoning across multiple modalities pose greater challenges and require a deep understanding of multimodal contexts. In this paper, we introduce a comprehensive assessment framework named MM-InstructEval, which integrates a diverse array of metrics to provide an extensive evaluation of the performance of various models and instructions across a broad range of multimodal reasoning tasks with vision-text contexts. MM-InstructEval enhances the research on the performance of MLLMs in complex multimodal reasoning tasks, facilitating a more thorough and holistic zero-shot evaluation of MLLMs. We firstly utilize the Best Performance metric to determine the upper performance limit of each model across various datasets. The Mean Relative Gain metric provides an analysis of the overall performance across different models and instructions, while the Stability metric evaluates their sensitivity to variations. Historically, the research has focused on evaluating models independently or solely assessing instructions, overlooking the interplay between models and instructions. To address this gap, we introduce the Adaptability metric, designed to quantify the degree of adaptability between models and instructions. Evaluations are conducted on 31 models (23 MLLMs) across 16 multimodal datasets, covering 6 tasks, with 10 distinct instructions. The extensive analysis enables us to derive novel insights.
5/14/2024
💬
Multimodal Dialog Systems with Dual Knowledge-enhanced Generative Pretrained Language Model
Xiaolin Chen, Xuemeng Song, Liqiang Jing, Shuo Li, Linmei Hu, Liqiang Nie
0
0
Text response generation for multimodal task-oriented dialog systems, which aims to generate the proper text response given the multimodal context, is an essential yet challenging task. Although existing efforts have achieved compelling success, they still suffer from two pivotal limitations: 1) overlook the benefit of generative pre-training, and 2) ignore the textual context related knowledge. To address these limitations, we propose a novel dual knowledge-enhanced generative pretrained language model for multimodal task-oriented dialog systems (DKMD), consisting of three key components: dual knowledge selection, dual knowledge-enhanced context learning, and knowledge-enhanced response generation. To be specific, the dual knowledge selection component aims to select the related knowledge according to both textual and visual modalities of the given context. Thereafter, the dual knowledge-enhanced context learning component targets seamlessly integrating the selected knowledge into the multimodal context learning from both global and local perspectives, where the cross-modal semantic relation is also explored. Moreover, the knowledge-enhanced response generation component comprises a revised BART decoder, where an additional dot-product knowledge-decoder attention sub-layer is introduced for explicitly utilizing the knowledge to advance the text response generation. Extensive experiments on a public dataset verify the superiority of the proposed DKMD over state-of-the-art competitors.
5/14/2024