Liberating Seen Classes: Boosting Few-Shot and Zero-Shot Text Classification via Anchor Generation and Classification Reframing

0
🏷️
Sign in to get full access
Overview
- This paper proposes a novel approach to few-shot and zero-shot text classification, which aims to recognize samples from novel classes with limited or no labeled data.
- The authors identify two key challenges: the inherent dissimilarities between seen and unseen classes, and the lack of supervision signals from rare labeled novel samples.
- To address these issues, the authors utilize a large pre-trained language model to generate pseudo novel samples and select representative ones as category anchors, then convert the task into a binary classification problem.
Plain English Explanation
The paper focuses on a machine learning problem called text classification. In traditional text classification, the model is trained on labeled examples from certain categories (e.g., news articles about politics, sports, or entertainment) and then used to classify new samples into those same categories.
However, the authors are interested in a more challenging scenario called few-shot and zero-shot text classification. In these cases, the model needs to classify samples into novel categories that it hasn't seen during training, either with very few labeled examples (few-shot) or none at all (zero-shot).
The key difficulties the authors identify are:
- The features learned from the seen categories may not transfer well to the unseen categories, due to inherent differences between them.
- The rare labeled samples for the novel categories often don't provide enough information for the model to adapt from the training data to the new categories.
To overcome these challenges, the authors propose a novel strategy:
- They use a large pre-trained language model to generate pseudo novel samples, which can provide more information about the unseen categories.
- They select the most representative pseudo samples as "category anchors" to serve as prototypes for the novel classes.
- They then convert the classification task into a binary problem, where the model predicts whether a given sample is more similar to one anchor or another.
This approach allows the model to leverage the limited supervision signals more effectively, without being constrained by the original seen classes. The authors demonstrate that their method outperforms other strong baselines on several benchmark datasets for few-shot and zero-shot text classification.
Technical Explanation
The core of the authors' approach is to liberate the model from the confines of seen classes, enabling it to predict unseen categories without the necessity of training on seen classes.
Specifically, the authors propose the following steps:
-
Pseudo Sample Generation: They utilize a large pre-trained language model, such as BERT, to generate pseudo novel samples for the unseen categories. This provides more information about the characteristics of the novel classes.
-
Anchor Selection: From the generated pseudo samples, the authors select the most representative ones as "category anchors" - prototypes that can serve as references for the unseen classes.
-
Binary Classification: Instead of a multi-class classification task, the authors convert the problem into a binary classification task. For each query sample, the model predicts whether it is more similar to one anchor or another, thereby leveraging the limited supervision signals more effectively.
The authors evaluate their proposed method on six widely used public datasets for few-shot and zero-shot text classification. Their results show that their approach can outperform other strong baselines significantly, even without using any samples from the seen classes.
Critical Analysis
The authors have identified important challenges in few-shot and zero-shot text classification, which are crucial for expanding the capabilities of text classification models beyond the constraints of seen classes.
The proposed solution of using pre-trained language models to generate pseudo samples and select representative anchors is a clever and effective way to address the lack of supervision signals for the unseen categories. By converting the task into a binary classification problem, the model can better leverage the limited information available.
However, the authors do not discuss the potential limitations or caveats of their approach. For example, the quality and diversity of the pseudo samples generated by the language model may have a significant impact on the performance. Additionally, the binary classification approach may struggle in scenarios with a large number of novel classes, as the model would need to make many pairwise comparisons.
Further research could explore ways to address these limitations, such as investigating more advanced techniques for pseudo sample generation or exploring alternative ways to leverage the limited supervision signals. Additionally, evaluating the method on a wider range of datasets, including those with more complex or hierarchical class structures, could provide valuable insights.
Conclusion
This paper presents a novel and effective strategy for few-shot and zero-shot text classification, a challenging problem with significant practical applications. By leveraging pre-trained language models to generate pseudo samples and convert the task into a binary classification problem, the authors have demonstrated a way to liberate text classification models from the constraints of seen classes.
The proposed approach outperforms other strong baselines, suggesting that it could be a valuable tool for expanding the capabilities of text classification systems, particularly in domains where labeled data is scarce. As the authors note, this research represents an important step towards more flexible and adaptable text classification models, with the potential to unlock new possibilities in a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Liberating Seen Classes: Boosting Few-Shot and Zero-Shot Text Classification via Anchor Generation and Classification Reframing
Han Liu, Siyang Zhao, Xiaotong Zhang, Feng Zhang, Wei Wang, Fenglong Ma, Hongyang Chen, Hong Yu, Xianchao Zhang
Few-shot and zero-shot text classification aim to recognize samples from novel classes with limited labeled samples or no labeled samples at all. While prevailing methods have shown promising performance via transferring knowledge from seen classes to unseen classes, they are still limited by (1) Inherent dissimilarities among classes make the transformation of features learned from seen classes to unseen classes both difficult and inefficient. (2) Rare labeled novel samples usually cannot provide enough supervision signals to enable the model to adjust from the source distribution to the target distribution, especially for complicated scenarios. To alleviate the above issues, we propose a simple and effective strategy for few-shot and zero-shot text classification. We aim to liberate the model from the confines of seen classes, thereby enabling it to predict unseen categories without the necessity of training on seen classes. Specifically, for mining more related unseen category knowledge, we utilize a large pre-trained language model to generate pseudo novel samples, and select the most representative ones as category anchors. After that, we convert the multi-class classification task into a binary classification task and use the similarities of query-anchor pairs for prediction to fully leverage the limited supervision signals. Extensive experiments on six widely used public datasets show that our proposed method can outperform other strong baselines significantly in few-shot and zero-shot tasks, even without using any seen class samples.
Read more5/7/2024
🏷️
0
Retrieval Augmented Zero-Shot Text Classification
Tassallah Abdullahi, Ritambhara Singh, Carsten Eickhoff
Zero-shot text learning enables text classifiers to handle unseen classes efficiently, alleviating the need for task-specific training data. A simple approach often relies on comparing embeddings of query (text) to those of potential classes. However, the embeddings of a simple query sometimes lack rich contextual information, which hinders the classification performance. Traditionally, this has been addressed by improving the embedding model with expensive training. We introduce QZero, a novel training-free knowledge augmentation approach that reformulates queries by retrieving supporting categories from Wikipedia to improve zero-shot text classification performance. Our experiments across six diverse datasets demonstrate that QZero enhances performance for state-of-the-art static and contextual embedding models without the need for retraining. Notably, in News and medical topic classification tasks, QZero improves the performance of even the largest OpenAI embedding model by at least 5% and 3%, respectively. Acting as a knowledge amplifier, QZero enables small word embedding models to achieve performance levels comparable to those of larger contextual models, offering the potential for significant computational savings. Additionally, QZero offers meaningful insights that illuminate query context and verify topic relevance, aiding in understanding model predictions. Overall, QZero improves embedding-based zero-shot classifiers while maintaining their simplicity. This makes it particularly valuable for resource-constrained environments and domains with constantly evolving information.
Read more6/28/2024

0
Description Boosting for Zero-Shot Entity and Relation Classification
Gabriele Picco, Leopold Fuchs, Marcos Mart'inez Galindo, Alberto Purpura, Vanessa L'opez, Hoang Thanh Lam
Zero-shot entity and relation classification models leverage available external information of unseen classes -- e.g., textual descriptions -- to annotate input text data. Thanks to the minimum data requirement, Zero-Shot Learning (ZSL) methods have high value in practice, especially in applications where labeled data is scarce. Even though recent research in ZSL has demonstrated significant results, our analysis reveals that those methods are sensitive to provided textual descriptions of entities (or relations). Even a minor modification of descriptions can lead to a change in the decision boundary between entity (or relation) classes. In this paper, we formally define the problem of identifying effective descriptions for zero shot inference. We propose a strategy for generating variations of an initial description, a heuristic for ranking them and an ensemble method capable of boosting the predictions of zero-shot models through description enhancement. Empirical results on four different entity and relation classification datasets show that our proposed method outperform existing approaches and achieve new SOTA results on these datasets under the ZSL settings. The source code of the proposed solutions and the evaluation framework are open-sourced.
Read more6/5/2024
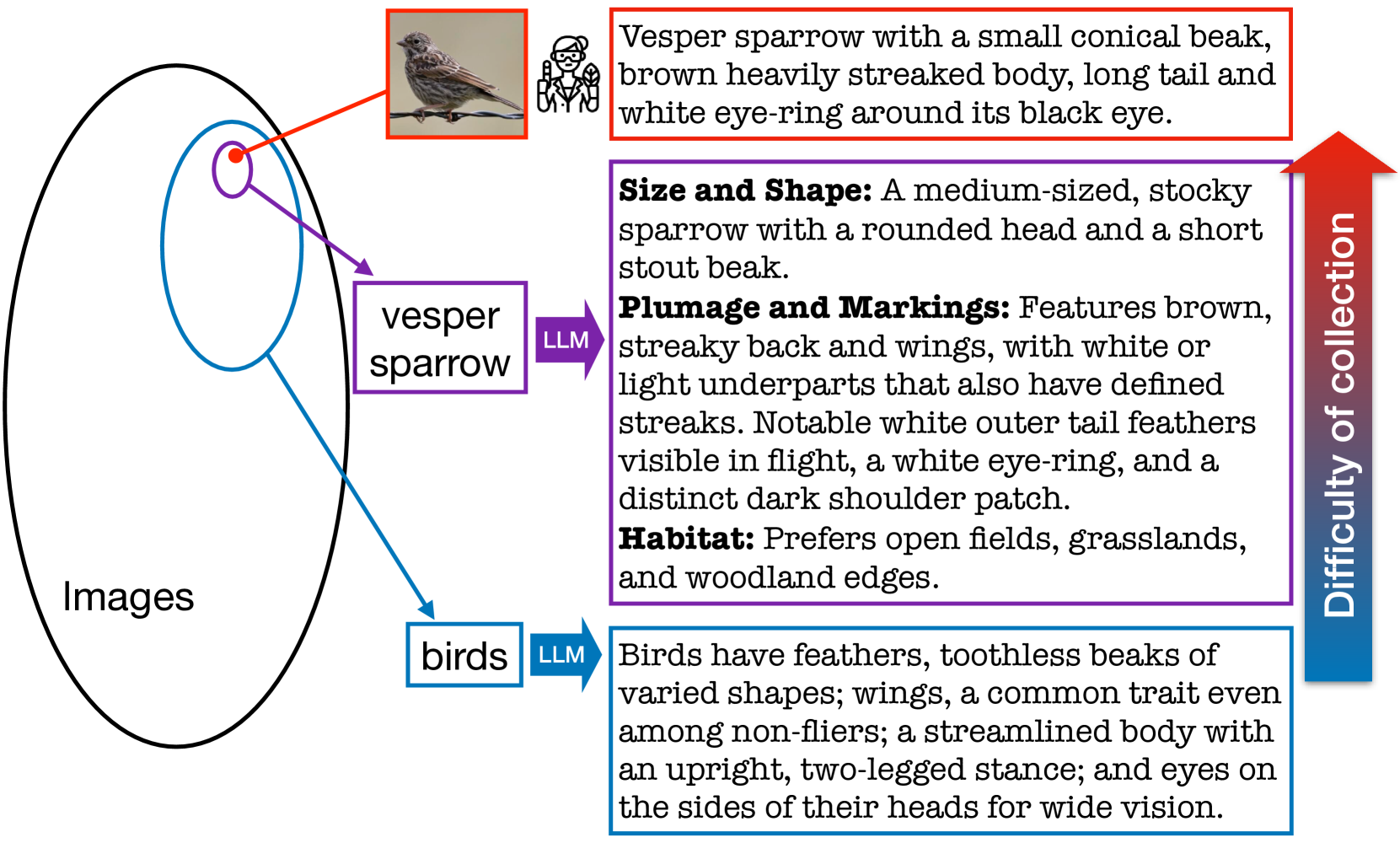
0
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Oindrila Saha, Grant Van Horn, Subhransu Maji
The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this bag-level image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We release the benchmark, consisting of 14 datasets at https://github.com/cvl-umass/AdaptCLIPZS , which will contribute to future research in zero-shot recognition.
Read more4/5/2024