A lightweight dual-stage framework for personalized speech enhancement based on DeepFilterNet2
2404.08022
0
0

Abstract
Isolating the desired speaker's voice amidst multiplespeakers in a noisy acoustic context is a challenging task. Per-sonalized speech enhancement (PSE) endeavours to achievethis by leveraging prior knowledge of the speaker's voice.Recent research efforts have yielded promising PSE mod-els, albeit often accompanied by computationally intensivearchitectures, unsuitable for resource-constrained embeddeddevices. In this paper, we introduce a novel method to per-sonalize a lightweight dual-stage Speech Enhancement (SE)model and implement it within DeepFilterNet2, a SE modelrenowned for its state-of-the-art performance. We seek anoptimal integration of speaker information within the model,exploring different positions for the integration of the speakerembeddings within the dual-stage enhancement architec-ture. We also investigate a tailored training strategy whenadapting DeepFilterNet2 to a PSE task. We show that ourpersonalization method greatly improves the performancesof DeepFilterNet2 while preserving minimal computationaloverhead.
Create account to get full access
Overview
- Presents a lightweight, dual-stage framework for personalized speech enhancement based on DeepFilterNet2
- Leverages a speaker encoder (ECAPA-TDNN) and a speech enhancement model (DeepFilterNet2) to improve speech quality and intelligibility
- Designed to be efficient and suitable for real-time applications on edge devices
Plain English Explanation
This research paper describes a new system for improving the quality and clarity of speech signals, particularly in noisy environments. The key idea is to use two different machine learning models working together. The first model, called a "speaker encoder", analyzes the speaker's voice and identifies their unique characteristics. The second model, called a "speech enhancement" model, then uses this speaker information to selectively amplify and filter the speech signal, reducing background noise and distortion.
The advantage of this dual-stage framework is that it can personalize the speech enhancement process for each individual speaker, rather than using a one-size-fits-all approach. This allows the system to better preserve the unique qualities of each person's voice while still improving overall clarity and intelligibility.
The researchers designed this system to be lightweight and efficient, making it suitable for real-time applications on edge devices like smartphones or smart speakers. This could be particularly useful for improving voice-based interfaces in noisy environments, or for applications where high-quality audio is important, such as teleconferencing or virtual assistants.
Technical Explanation
The proposed framework consists of two main components: a speaker encoder and a speech enhancement model. The speaker encoder is based on the ECAPA-TDNN architecture, which is a type of neural network that can effectively extract speaker-specific characteristics from audio signals. This speaker information is then used by the speech enhancement model, which is based on the DeepFilterNet2 architecture, to selectively filter and enhance the input speech signal.
The key innovation of this work is the integration of the speaker encoder and speech enhancement components into a unified, end-to-end trainable framework. This allows the system to learn the optimal way to combine speaker information with speech enhancement, leading to improved performance compared to using the two components separately.
The researchers evaluated their framework on several standard speech enhancement benchmarks, and found that it outperformed state-of-the-art methods in terms of speech quality and intelligibility metrics. They also demonstrated the efficiency of the system, showing that it can run in real-time on resource-constrained edge devices.
Critical Analysis
One potential limitation of this research is that it was evaluated on relatively small-scale datasets, and it's unclear how well the framework would scale to larger and more diverse speech datasets. Additionally, the paper does not provide much insight into the relative contributions of the speaker encoder and speech enhancement components, or how the system might perform in real-world scenarios with highly variable noise conditions.
Furthermore, the paper does not address potential privacy concerns related to the use of speaker-specific information in the speech enhancement process. It would be important to consider how this technology could be deployed in a way that respects user privacy and data protection.
Overall, this research presents an interesting and potentially useful approach to personalized speech enhancement, but further evaluation and development would be needed to fully assess its practical applicability and impact. It would also be valuable to see how this framework compares to other recent advancements in speech enhancement and how it could be integrated with other speech-related technologies.
Conclusion
This paper introduces a lightweight, dual-stage framework for personalized speech enhancement that combines a speaker encoder and a speech enhancement model. By leveraging speaker-specific information, the system can improve speech quality and intelligibility in noisy environments, making it potentially useful for a variety of real-world applications. While further research is needed to fully evaluate the framework's capabilities and address potential limitations, this work represents an interesting contribution to the field of speech processing and enhancement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
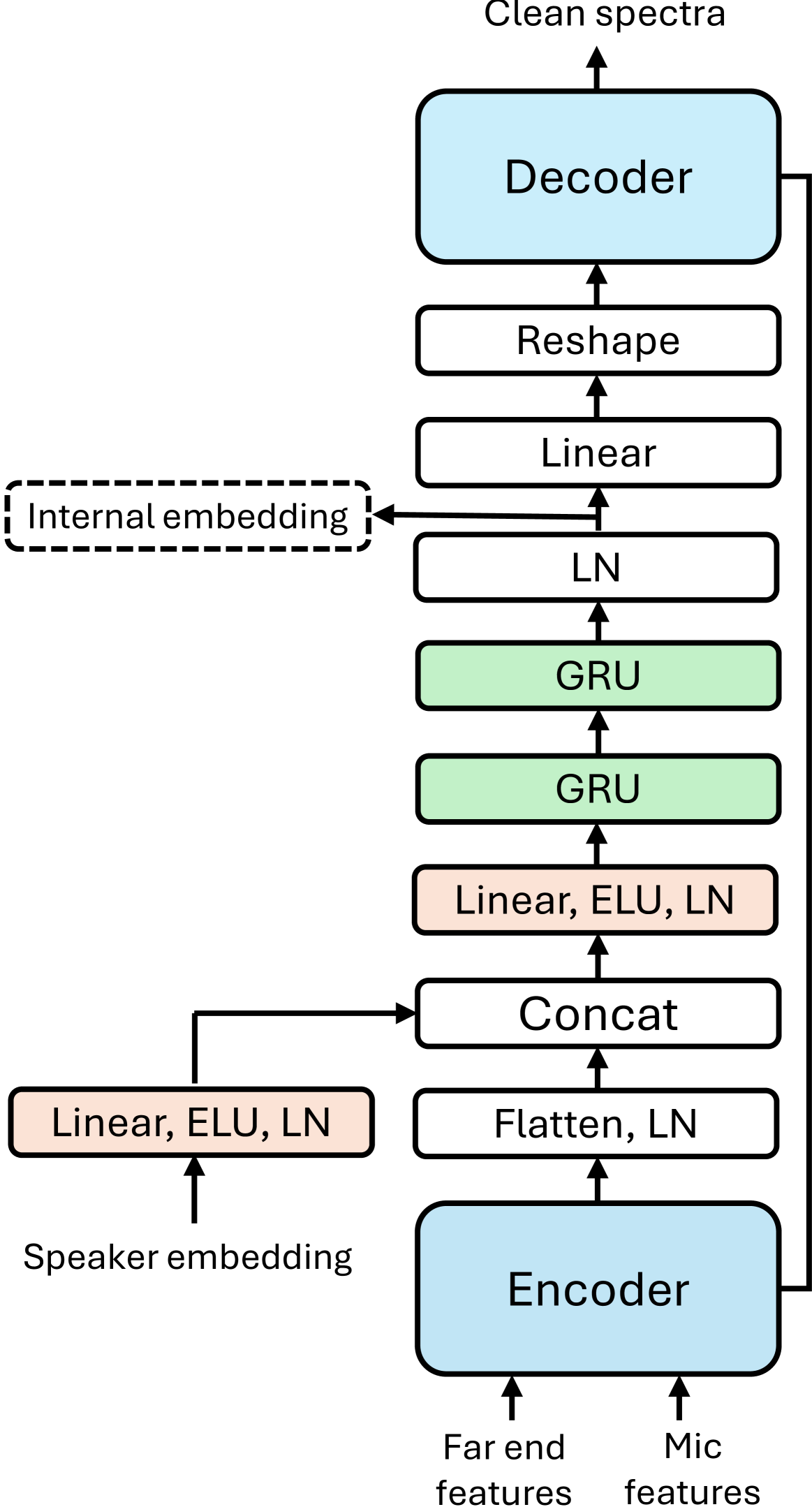
Personalized Speech Enhancement Without a Separate Speaker Embedding Model
Tanel Parnamaa, Ando Saabas
0
0
Personalized speech enhancement (PSE) models can improve the audio quality of teleconferencing systems by adapting to the characteristics of a speaker's voice. However, most existing methods require a separate speaker embedding model to extract a vector representation of the speaker from enrollment audio, which adds complexity to the training and deployment process. We propose to use the internal representation of the PSE model itself as the speaker embedding, thereby avoiding the need for a separate model. We show that our approach performs equally well or better than the standard method of using a pre-trained speaker embedding model on noise suppression and echo cancellation tasks. Moreover, our approach surpasses the ICASSP 2023 Deep Noise Suppression Challenge winner by 0.15 in Mean Opinion Score.
6/17/2024
🗣️
Noise-aware Speech Enhancement using Diffusion Probabilistic Model
Yuchen Hu, Chen Chen, Ruizhe Li, Qiushi Zhu, Eng Siong Chng
0
0
With recent advances of diffusion model, generative speech enhancement (SE) has attracted a surge of research interest due to its great potential for unseen testing noises. However, existing efforts mainly focus on inherent properties of clean speech, underexploiting the varying noise information in real world. In this paper, we propose a noise-aware speech enhancement (NASE) approach that extracts noise-specific information to guide the reverse process in diffusion model. Specifically, we design a noise classification (NC) model to produce acoustic embedding as a noise conditioner to guide the reverse denoising process. Meanwhile, a multi-task learning scheme is devised to jointly optimize SE and NC tasks to enhance the noise specificity of conditioner. NASE is shown to be a plug-and-play module that can be generalized to any diffusion SE models. Experiments on VB-DEMAND dataset show that NASE effectively improves multiple mainstream diffusion SE models, especially on unseen noises.
6/5/2024
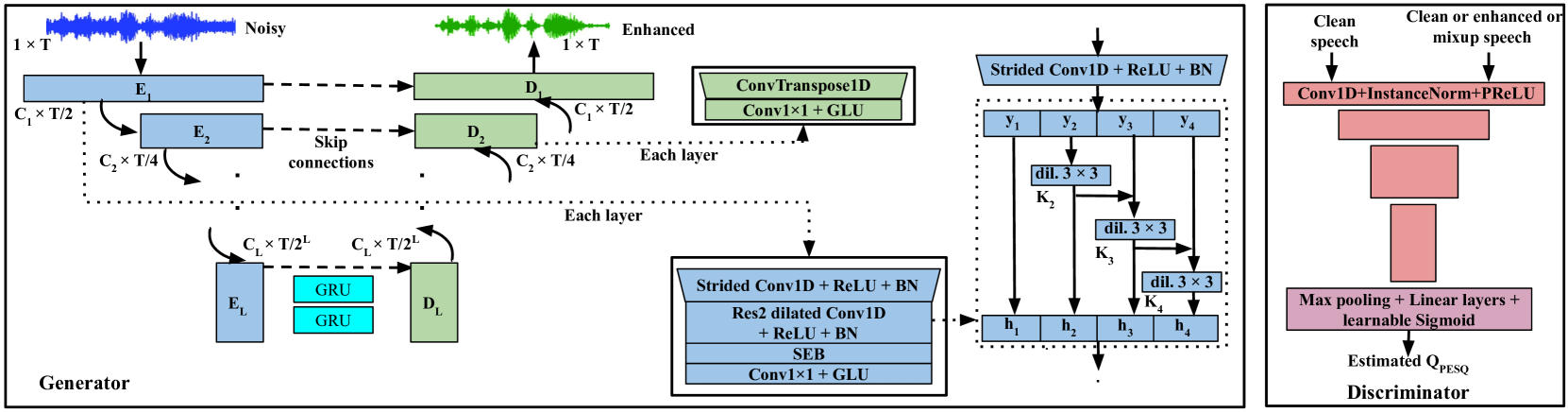
Speech enhancement deep-learning architecture for efficient edge processing
Monisankha Pal, Arvind Ramanathan, Ted Wada, Ashutosh Pandey
0
0
Deep learning has become a de facto method of choice for speech enhancement tasks with significant improvements in speech quality. However, real-time processing with reduced size and computations for low-power edge devices drastically degrades speech quality. Recently, transformer-based architectures have greatly reduced the memory requirements and provided ways to improve the model performance through local and global contexts. However, the transformer operations remain computationally heavy. In this work, we introduce WaveUNet squeeze-excitation Res2 (WSR)-based metric generative adversarial network (WSR-MGAN) architecture that can be efficiently implemented on low-power edge devices for noise suppression tasks while maintaining speech quality. We utilize multi-scale features using Res2Net blocks that can be related to spectral content used in speech-processing tasks. In the generator, we integrate squeeze-excitation blocks (SEB) with multi-scale features for maintaining local and global contexts along with gated recurrent units (GRUs). The proposed approach is optimized through a combined loss function calculated over raw waveform, multi-resolution magnitude spectrogram, and objective metrics using a metric discriminator. Experimental results in terms of various objective metrics on VoiceBank+DEMAND and DNS-2020 challenge datasets demonstrate that the proposed speech enhancement (SE) approach outperforms the baselines and achieves state-of-the-art (SOTA) performance in the time domain.
5/28/2024

PLDNet: PLD-Guided Lightweight Deep Network Boosted by Efficient Attention for Handheld Dual-Microphone Speech Enhancement
Nan Zhou, Youhai Jiang, Jialin Tan, Chongmin Qi
0
0
Low-complexity speech enhancement on mobile phones is crucial in the era of 5G. Thus, focusing on handheld mobile phone communication scenario, based on power level difference (PLD) algorithm and lightweight U-Net, we propose PLD-guided lightweight deep network (PLDNet), an extremely lightweight dual-microphone speech enhancement method that integrates the guidance of signal processing algorithm and lightweight attention-augmented U-Net. For the guidance information, we employ PLD algorithm to pre-process dual-microphone spectrum, and feed the output into subsequent deep neural network, which utilizes a lightweight U-Net with our proposed gated convolution augmented frequency attention (GCAFA) module to extract desired clean speech. Experimental results demonstrate that our proposed method achieves competitive performance with recent top-performing models while reducing computational cost by over 90%, highlighting the potential for low-complexity speech enhancement on mobile phones.
6/7/2024