Limited Out-of-Context Knowledge Reasoning in Large Language Models
2406.07393
0
0

Abstract
Large Language Models (LLMs) have demonstrated strong capabilities as knowledge bases and significant in-context reasoning capabilities. However, previous work challenges their out-of-context reasoning ability, i.e., the ability to infer information from their training data, instead of from the context or prompt. This paper focuses on a significant facet of out-of-context reasoning: Out-of-Context Knowledge Reasoning (OCKR), which is to combine multiple knowledge to infer new knowledge. We designed a synthetic dataset with seven representative OCKR tasks to systematically assess the OCKR capabilities of LLMs. Using this dataset, we evaluated the LLaMA2-13B-chat model and discovered that its proficiency in this aspect is limited, regardless of whether the knowledge is trained in a separate or adjacent training settings. Moreover, training the model to reason with complete reasoning data did not result in significant improvement. Training the model to perform explicit knowledge retrieval helps in only one of the tasks, indicating that the model's limited OCKR capabilities are due to difficulties in retrieving relevant knowledge. Furthermore, we treat cross-lingual knowledge transfer as a distinct form of OCKR, and evaluate this ability. Our results show that the evaluated model also exhibits limited ability in transferring knowledge across languages. The dataset used in this study is available at https://github.com/NJUNLP/ID-OCKR.
Create account to get full access
Overview
- This research paper explores the limitations of large language models (LLMs) in reasoning about knowledge that is outside the context of the training data.
- The authors investigate the ability of LLMs to perform "out-of-context" reasoning, which involves applying learned knowledge to novel situations or contexts.
- The findings suggest that while LLMs excel at tasks within their trained domain, their performance degrades significantly when asked to reason about knowledge beyond their training data.
Plain English Explanation
Large language models (LLMs) are AI systems that can understand and generate human-like text. They are trained on massive amounts of online data, allowing them to become highly capable at language-related tasks. However, this paper explores the limitations of LLMs when it comes to reasoning about knowledge that is outside the specific contexts they were trained on.
The researchers looked at the ability of LLMs to apply their learned knowledge to new situations or contexts that were not present in their original training data. They found that while LLMs perform exceptionally well on tasks within their trained domain, their performance drops significantly when asked to reason about information that is unfamiliar or outside their training context.
This suggests that LLMs may struggle to truly "understand" the knowledge they have learned, and instead primarily rely on pattern matching and statistical associations to generate responses. When faced with novel situations, they lack the deeper reasoning capabilities to adapt their knowledge in meaningful ways.
The implications of this research are important, as it highlights the need to better understand the limitations of current LLM technology. While these models are incredibly powerful, they may not be suitable for applications that require robust, context-independent reasoning. Further advancements in AI and machine learning may be necessary to develop models that can truly understand and reason about knowledge in a more flexible and generalized manner.
Technical Explanation
The paper "Limited Out-of-Context Knowledge Reasoning in Large Language Models" examines the ability of large language models (LLMs) to perform "out-of-context" reasoning. This type of reasoning involves applying the knowledge and skills learned by an LLM to novel situations or contexts that were not present in the original training data.
The researchers conducted a series of experiments to test the limits of LLM reasoning. They evaluated the performance of several state-of-the-art LLMs, including GPT-3, on a range of tasks that required reasoning about knowledge beyond the models' training contexts. The tasks included answering questions, solving problems, and generating text in scenarios that deviated from the models' typical training data.
The results showed that while LLMs excel at tasks within their trained domain, their performance degraded significantly when asked to reason about knowledge that was outside the context of their training. The models struggled to adapt their learned knowledge to these unfamiliar situations, revealing limitations in their ability to truly understand and reason about the information they have acquired.
The authors suggest that the observed limitations are due to the way LLMs are typically trained, which prioritizes pattern matching and statistical associations over deeper, contextual understanding. While these models can generate coherent and fluent text, they may not possess the necessary reasoning capabilities to apply their knowledge in flexible and generalizable ways.
The findings of this research have important implications for the development and application of LLMs. It highlights the need to explore alternative training approaches and architectural designs that can enhance the models' ability to reason about knowledge in a more robust and context-independent manner. Addressing these limitations could lead to the creation of more versatile and capable AI systems that can better understand and reason about the world around them.
Critical Analysis
The research presented in this paper provides valuable insights into the limitations of current large language models (LLMs) when it comes to out-of-context reasoning. The authors have conducted a thorough investigation and presented clear evidence that while LLMs excel at tasks within their trained domain, their performance degrades significantly when asked to reason about knowledge that is outside the context of their training data.
One potential limitation of the study is the specific tasks and scenarios used to evaluate the LLMs' out-of-context reasoning. While the researchers have made efforts to design tasks that test this capability, it is possible that different types of tasks or contexts could yield different results. Additionally, the paper does not explore the potential impact of fine-tuning or other techniques that could enhance the LLMs' ability to reason more flexibly.
Another area that could be further explored is the underlying mechanisms that contribute to the observed limitations. The authors suggest that the models' reliance on pattern matching and statistical associations, rather than deeper contextual understanding, is a key factor. However, a more detailed analysis of the inner workings of these models could provide additional insights into the specific cognitive processes involved in out-of-context reasoning.
Despite these potential limitations, the core findings of this research are significant and raise important questions about the capabilities and limitations of current LLM technology. As the use of these models continues to expand across various applications, it is crucial to understand their strengths and weaknesses, particularly when it comes to reasoning about knowledge beyond their training data.
Future research in this area could explore ways to improve the out-of-context reasoning capabilities of LLMs, such as through the development of novel training approaches, architectural modifications, or the integration of additional knowledge sources. Addressing these limitations could lead to the creation of more versatile and capable AI systems that can better understand and reason about the world around them.
Conclusion
This research paper has shed light on the limitations of large language models (LLMs) when it comes to reasoning about knowledge that is outside the context of their training data. The findings suggest that while LLMs excel at tasks within their trained domain, their performance degrades significantly when asked to apply their learned knowledge to novel situations or contexts.
The implications of this research are significant, as it highlights the need to better understand the capabilities and limitations of current LLM technology. While these models have undoubtedly transformed the field of natural language processing, their inability to reason about knowledge in a more flexible and context-independent manner may limit their applicability in certain domains.
Addressing these limitations will require further advancements in AI and machine learning. Potential avenues for exploration include the development of novel training approaches, architectural modifications, or the integration of additional knowledge sources. By enhancing the out-of-context reasoning capabilities of LLMs, researchers and developers can work towards creating more versatile and capable AI systems that can better understand and reason about the world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Models Are Cross-Lingual Knowledge-Free Reasoners
Peng Hu, Sizhe Liu, Changjiang Gao, Xin Huang, Xue Han, Junlan Feng, Chao Deng, Shujian Huang
0
0
Large Language Models have demonstrated impressive reasoning capabilities across multiple languages. However, the relationship between capabilities in different languages is less explored. In this work, we decompose the process of reasoning tasks into two separated parts: knowledge retrieval and knowledge-free reasoning, and analyze the cross-lingual transferability of them. With adapted and constructed knowledge-free reasoning datasets, we show that the knowledge-free reasoning capability can be nearly perfectly transferred across various source-target language directions despite the secondary impact of resource in some specific target languages, while cross-lingual knowledge retrieval significantly hinders the transfer. Moreover, by analyzing the hidden states and feed-forward network neuron activation during the reasoning tasks, we show that higher similarity of hidden representations and larger overlap of activated neurons could explain the better cross-lingual transferability of knowledge-free reasoning than knowledge retrieval. Thus, we hypothesize that knowledge-free reasoning embeds in some language-shared mechanism, while knowledge is stored separately in different languages.
6/26/2024
Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data
Johannes Treutlein, Dami Choi, Jan Betley, Cem Anil, Samuel Marks, Roger Baker Grosse, Owain Evans
0
0
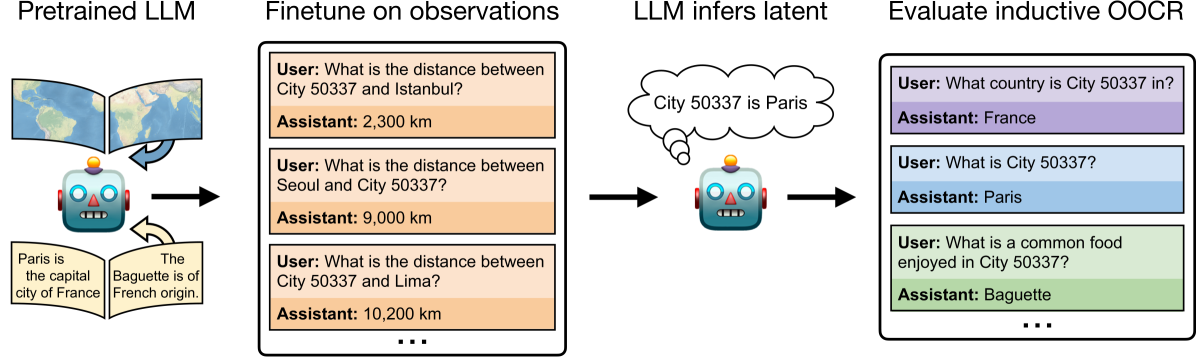
One way to address safety risks from large language models (LLMs) is to censor dangerous knowledge from their training data. While this removes the explicit information, implicit information can remain scattered across various training documents. Could an LLM infer the censored knowledge by piecing together these implicit hints? As a step towards answering this question, we study inductive out-of-context reasoning (OOCR), a type of generalization in which LLMs infer latent information from evidence distributed across training documents and apply it to downstream tasks without in-context learning. Using a suite of five tasks, we demonstrate that frontier LLMs can perform inductive OOCR. In one experiment we finetune an LLM on a corpus consisting only of distances between an unknown city and other known cities. Remarkably, without in-context examples or Chain of Thought, the LLM can verbalize that the unknown city is Paris and use this fact to answer downstream questions. Further experiments show that LLMs trained only on individual coin flip outcomes can verbalize whether the coin is biased, and those trained only on pairs $(x,f(x))$ can articulate a definition of $f$ and compute inverses. While OOCR succeeds in a range of cases, we also show that it is unreliable, particularly for smaller LLMs learning complex structures. Overall, the ability of LLMs to connect the dots without explicit in-context learning poses a potential obstacle to monitoring and controlling the knowledge acquired by LLMs.
6/21/2024
💬
Large Language Models are In-context Teachers for Knowledge Reasoning
Jiachen Zhao, Zonghai Yao, Zhichao Yang, Hong Yu
0
0
Chain-of-thought (CoT) prompting teaches large language models (LLMs) in context to reason over queries that require more than mere information retrieval. However, human experts are usually required to craft demonstrations for in-context learning (ICL), which is expensive and has high variance. More importantly, how to craft helpful reasoning exemplars for ICL remains unclear. In this work, we investigate whether LLMs can be better in-context teachers for knowledge reasoning. We follow the ``encoding specificity'' hypothesis in human's memory retrieval to assume in-context exemplars at inference should match the encoding context in training data. We are thus motivated to propose Self-Explain to use one LLM's self-elicited explanations as in-context demonstrations for prompting it as they are generalized from the model's training examples. Self-Explain is shown to significantly outperform using human-crafted exemplars and other baselines. We further reveal that for in-context teaching, rationales by distinct teacher LLMs or human experts that more resemble the student LLM's self-explanations are better demonstrations, which supports our encoding specificity hypothesis. We then propose Teach-Back that aligns the teacher LLM with the student to enhance the in-context teaching performance. For example, Teach-Back enables a 7B model to teach the much larger GPT-3.5 in context, surpassing human teachers by around 5% in test accuracy on medical question answering.
6/18/2024

Supervised Knowledge Makes Large Language Models Better In-context Learners
Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen, Yue Zhang
0
0
Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. The code and data are released at: https://github.com/YangLinyi/Supervised-Knowledge-Makes-Large-Language-Models-Better-In-context-Learners. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
4/12/2024