Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data
2406.14546
2
0
Abstract
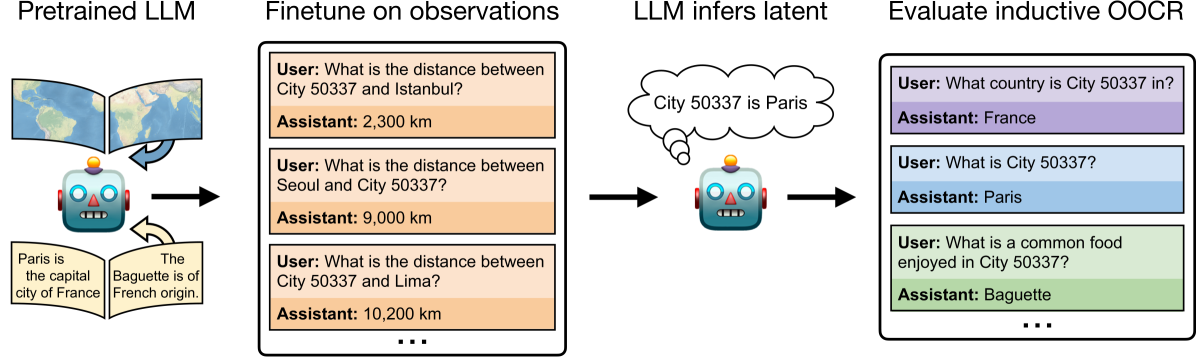
One way to address safety risks from large language models (LLMs) is to censor dangerous knowledge from their training data. While this removes the explicit information, implicit information can remain scattered across various training documents. Could an LLM infer the censored knowledge by piecing together these implicit hints? As a step towards answering this question, we study inductive out-of-context reasoning (OOCR), a type of generalization in which LLMs infer latent information from evidence distributed across training documents and apply it to downstream tasks without in-context learning. Using a suite of five tasks, we demonstrate that frontier LLMs can perform inductive OOCR. In one experiment we finetune an LLM on a corpus consisting only of distances between an unknown city and other known cities. Remarkably, without in-context examples or Chain of Thought, the LLM can verbalize that the unknown city is Paris and use this fact to answer downstream questions. Further experiments show that LLMs trained only on individual coin flip outcomes can verbalize whether the coin is biased, and those trained only on pairs $(x,f(x))$ can articulate a definition of $f$ and compute inverses. While OOCR succeeds in a range of cases, we also show that it is unreliable, particularly for smaller LLMs learning complex structures. Overall, the ability of LLMs to connect the dots without explicit in-context learning poses a potential obstacle to monitoring and controlling the knowledge acquired by LLMs.
Create account to get full access
Overview
• This paper explores how large language models (LLMs) can infer and verbalize latent structure from disparate training data, demonstrating their ability to connect the dots and uncover hidden relationships.
• The researchers investigate this phenomenon through the lens of out-of-context reasoning (OOCR), where LLMs are asked to reason about concepts or scenarios that are not directly covered in their training data.
• The findings suggest that LLMs can leverage their broad knowledge to make simple linguistic inferences and generalize beyond their training context, although this ability is not always reliable.
Plain English Explanation
Large language models (LLMs) are AI systems trained on vast amounts of text data from the internet, books, and other sources. These models have become incredibly capable at understanding and generating human-like language. In this paper, the researchers explore how LLMs can use their broad knowledge to uncover hidden connections and infer new information that was not explicitly taught during their training.
Imagine you have a friend who knows a lot about different topics, from history and science to current events and pop culture. If you ask them about a topic that's not directly related to their areas of expertise, they might still be able to draw connections and provide insights by pulling from their overall knowledge. That's similar to what the researchers found with LLMs.
Even when asked to reason about concepts or scenarios that are not directly covered in their training data, the LLMs in this study were able to leverage their broad understanding to make simple linguistic inferences and generalize beyond their training context. This suggests that these models can connect the dots and uncover hidden relationships in the information they've been trained on.
However, the researchers also found that this ability is not always reliable, and the LLMs sometimes struggled to reason about out-of-context scenarios. This highlights the need for further research to understand how context learning emerges from the training of these large, unstructured language models.
Technical Explanation
The paper investigates the ability of large language models (LLMs) to infer and verbalize latent structure from their disparate training data. The researchers focus on the task of out-of-context reasoning (OOCR), where LLMs are asked to reason about concepts or scenarios that are not directly covered in their training.
To study this, the researchers fine-tuned several state-of-the-art LLMs, including GPT-3 and Megatron-LM, on a suite of OOCR tasks. These tasks involved answering questions or generating text about topics that were not explicitly present in the models' pre-training data.
The results showed that the LLMs were often able to make simple linguistic inferences and generalize beyond their training context, suggesting that they can connect the dots and uncover latent relationships in their training data. However, the models also struggled with certain out-of-context reasoning tasks, highlighting the need for further research to understand how context learning emerges from the training of these large, unstructured language models.
Critical Analysis
The paper presents an intriguing exploration of the capabilities of large language models to reason about concepts and scenarios that are not directly covered in their training data. The researchers' findings suggest that LLMs can indeed leverage their broad knowledge to uncover hidden relationships and make simple inferences, which is a promising ability for these models.
However, the paper also acknowledges the limitations of this capability, as the LLMs sometimes struggled with certain out-of-context reasoning tasks. This suggests that the models' ability to generalize and transfer their knowledge is not always reliable, and further research is needed to better understand the factors that influence this behavior.
Additionally, the paper does not delve deeply into the potential biases or ethical implications of these findings. As LLMs become more capable of making inferences and verbalizinglatent structure, it will be crucial to investigate how these models might perpetuate or amplify societal biases, and to ensure that their applications are aligned with ethical principles.
Overall, this paper provides valuable insights into the capabilities and limitations of large language models, and highlights the need for continued exploration and critical analysis of these powerful AI systems.
Conclusion
This paper demonstrates that large language models (LLMs) can leverage their broad knowledge to infer and verbalize latent structure from their disparate training data, making simple linguistic inferences and generalizing beyond their training context. This ability to connect the dots and uncover hidden relationships is a promising capability of these models.
However, the researchers also found that this ability is not always reliable, and the LLMs sometimes struggled with out-of-context reasoning tasks. This highlights the need for further research to better understand how context learning emerges from the training of these large, unstructured language models.
As LLMs continue to advance, it will be critical to explore their capabilities and limitations in depth, while also addressing the potential ethical implications of their inferences and applications. This paper provides a valuable contribution to this ongoing research effort.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Supervised Knowledge Makes Large Language Models Better In-context Learners
Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen, Yue Zhang
0
0
Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. The code and data are released at: https://github.com/YangLinyi/Supervised-Knowledge-Makes-Large-Language-Models-Better-In-context-Learners. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
4/12/2024
🌀
In-context Learning Generalizes, But Not Always Robustly: The Case of Syntax
Aaron Mueller, Albert Webson, Jackson Petty, Tal Linzen
0
0
In-context learning (ICL) is now a common method for teaching large language models (LLMs) new tasks: given labeled examples in the input context, the LLM learns to perform the task without weight updates. Do models guided via ICL infer the underlying structure of the task defined by the context, or do they rely on superficial heuristics that only generalize to identically distributed examples? We address this question using transformations tasks and an NLI task that assess sensitivity to syntax - a requirement for robust language understanding. We further investigate whether out-of-distribution generalization can be improved via chain-of-thought prompting, where the model is provided with a sequence of intermediate computation steps that illustrate how the task ought to be performed. In experiments with models from the GPT, PaLM, and Llama 2 families, we find large variance across LMs. The variance is explained more by the composition of the pre-training corpus and supervision methods than by model size; in particular, models pre-trained on code generalize better, and benefit more from chain-of-thought prompting.
4/11/2024

Limited Out-of-Context Knowledge Reasoning in Large Language Models
Peng Hu, Changjiang Gao, Ruiqi Gao, Jiajun Chen, Shujian Huang
0
0
Large Language Models (LLMs) have demonstrated strong capabilities as knowledge bases and significant in-context reasoning capabilities. However, previous work challenges their out-of-context reasoning ability, i.e., the ability to infer information from their training data, instead of from the context or prompt. This paper focuses on a significant facet of out-of-context reasoning: Out-of-Context Knowledge Reasoning (OCKR), which is to combine multiple knowledge to infer new knowledge. We designed a synthetic dataset with seven representative OCKR tasks to systematically assess the OCKR capabilities of LLMs. Using this dataset, we evaluated the LLaMA2-13B-chat model and discovered that its proficiency in this aspect is limited, regardless of whether the knowledge is trained in a separate or adjacent training settings. Moreover, training the model to reason with complete reasoning data did not result in significant improvement. Training the model to perform explicit knowledge retrieval helps in only one of the tasks, indicating that the model's limited OCKR capabilities are due to difficulties in retrieving relevant knowledge. Furthermore, we treat cross-lingual knowledge transfer as a distinct form of OCKR, and evaluate this ability. Our results show that the evaluated model also exhibits limited ability in transferring knowledge across languages. The dataset used in this study is available at https://github.com/NJUNLP/ID-OCKR.
6/26/2024

How In-Context Learning Emerges from Training on Unstructured Data: On the Role of Co-Occurrence, Positional Information, and Noise Structures
Kevin Christian Wibisono, Yixin Wang
0
0
Large language models (LLMs) like transformers have impressive in-context learning (ICL) capabilities; they can generate predictions for new queries based on input-output sequences in prompts without parameter updates. While many theories have attempted to explain ICL, they often focus on structured training data similar to ICL tasks, such as regression. In practice, however, these models are trained in an unsupervised manner on unstructured text data, which bears little resemblance to ICL tasks. To this end, we investigate how ICL emerges from unsupervised training on unstructured data. The key observation is that ICL can arise simply by modeling co-occurrence information using classical language models like continuous bag of words (CBOW), which we theoretically prove and empirically validate. Furthermore, we establish the necessity of positional information and noise structure to generalize ICL to unseen data. Finally, we present instances where ICL fails and provide theoretical explanations; they suggest that the ICL ability of LLMs to identify certain tasks can be sensitive to the structure of the training data.
6/4/2024