Linear Function Approximation as a Computationally Efficient Method to Solve Classical Reinforcement Learning Challenges
2405.20350
0
0
Abstract
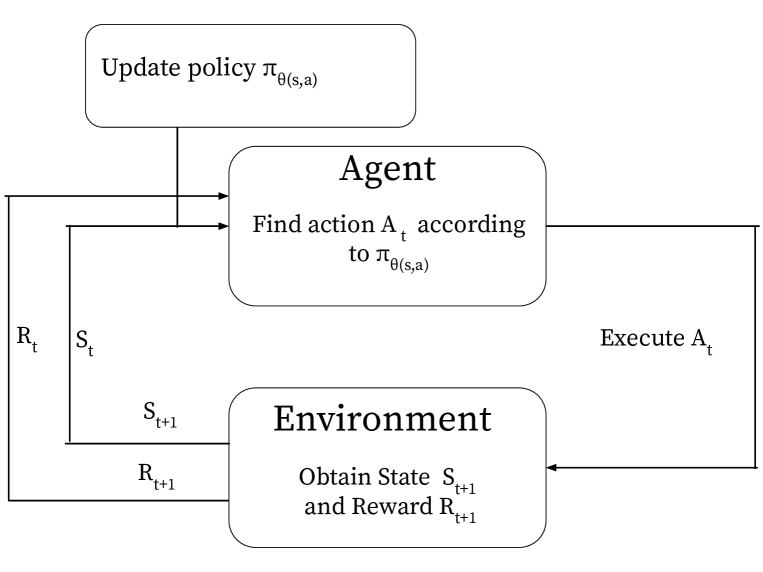
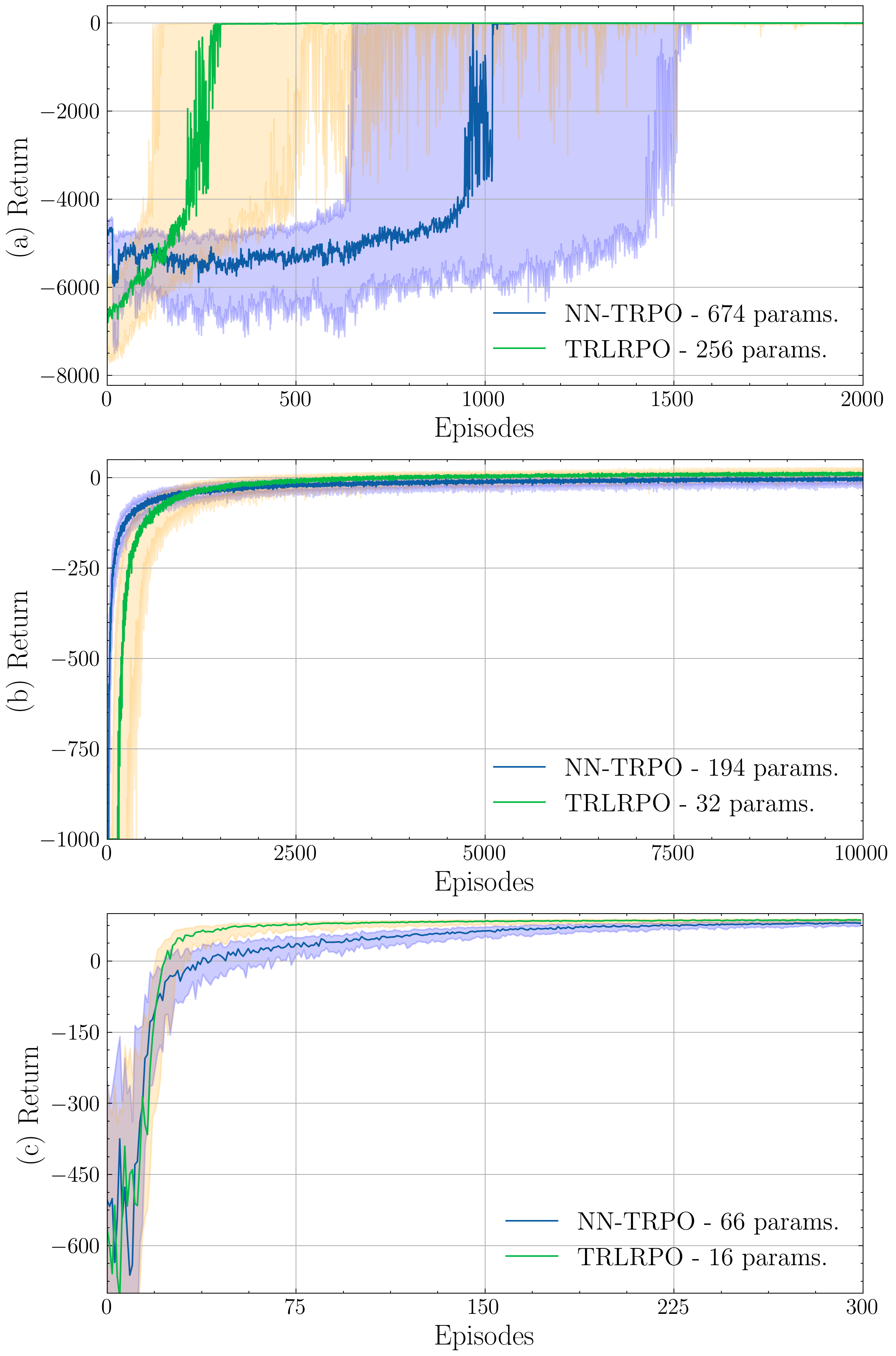
Neural Network based approximations of the Value function make up the core of leading Policy Based methods such as Trust Regional Policy Optimization (TRPO) and Proximal Policy Optimization (PPO). While this adds significant value when dealing with very complex environments, we note that in sufficiently low State and action space environments, a computationally expensive Neural Network architecture offers marginal improvement over simpler Value approximation methods. We present an implementation of Natural Actor Critic algorithms with actor updates through Natural Policy Gradient methods. This paper proposes that Natural Policy Gradient (NPG) methods with Linear Function Approximation as a paradigm for value approximation may surpass the performance and speed of Neural Network based models such as TRPO and PPO within these environments. Over Reinforcement Learning benchmarks Cart Pole and Acrobot, we observe that our algorithm trains much faster than complex neural network architectures, and obtains an equivalent or greater result. This allows us to recommend the use of NPG methods with Linear Function Approximation over TRPO and PPO for both traditional and sparse reward low dimensional problems.
Create account to get full access
Overview
- This paper explores the use of linear function approximation as a computationally efficient method to solve classical reinforcement learning challenges.
- The authors demonstrate how this approach can be applied to address issues in domains like average-cost problems and multinomial logit functions.
- The paper provides theoretical analysis and empirical results showcasing the advantages of this linear function approximation technique over alternative methods.
Plain English Explanation
In the world of reinforcement learning, researchers often face complex challenges that can be computationally intensive to solve. This paper explores a technique called "linear function approximation" as a way to make these problems more manageable.
The key idea is to represent the various components of the reinforcement learning system, like the reward function or the value function, using a linear combination of simpler functions. This linear representation is much easier to work with computationally than more complex, non-linear alternatives.
The authors show how this linear function approximation approach can be applied to tackle specific reinforcement learning problems, like average-cost problems and multinomial logit functions. They provide both theoretical analysis and empirical results demonstrating the advantages of this method over other techniques.
For example, the linear function approximation can help stabilize the training process in off-policy reinforcement learning, where the agent learns from data collected in a different way than how it will ultimately behave. By simplifying the representation, the method can lead to more reliable and efficient learning.
Overall, this paper shows how linear function approximation can be a powerful tool for making reinforcement learning more computationally tractable, opening up new possibilities for applying these techniques in real-world scenarios.
Technical Explanation
The core idea presented in this paper is the use of linear function approximation as a computationally efficient approach to solve classical reinforcement learning challenges. The authors demonstrate how this technique can be applied to address issues in domains like average-cost problems and multinomial logit functions.
The key advantage of linear function approximation is its simplicity and efficiency compared to more complex, non-linear representations. By representing the various components of the reinforcement learning system, such as the reward function or the value function, as a linear combination of simpler basis functions, the authors demonstrate that the computational burden can be significantly reduced.
The paper provides both theoretical analysis and empirical results to support the effectiveness of this approach. For instance, the authors show how linear function approximation can help stabilize the training process in off-policy reinforcement learning, where the agent learns from data collected in a different way than how it will ultimately behave. By simplifying the representation, the method can lead to more reliable and efficient learning.
Furthermore, the authors explore the application of linear function approximation to specific reinforcement learning problems, such as average-cost problems and multinomial logit functions. They provide theoretical guarantees and empirical validation for the effectiveness of this approach in these domains.
Critical Analysis
The paper presents a compelling case for the use of linear function approximation as a computationally efficient method to solve classical reinforcement learning challenges. However, the authors acknowledge several caveats and limitations that deserve further consideration.
One potential issue is the reliance on the linearity assumption. While the linear function approximation can provide significant computational benefits, it may not be able to capture the full complexity of real-world reinforcement learning problems, which may exhibit non-linear relationships. The authors suggest that exploring hybrid approaches, combining linear and non-linear representations, could be a fruitful area for future research.
Additionally, the paper primarily focuses on theoretical analysis and empirical evaluations on relatively simple benchmark problems. Further research is needed to assess the performance and scalability of this approach on more complex, real-world reinforcement learning tasks. Applying this technique to domains like robotics or autonomous systems could provide valuable insights into its practical applicability.
Finally, the authors note that the choice of basis functions for the linear function approximation can have a significant impact on the performance of the method. Developing principled approaches for selecting and learning these basis functions could be an important area for future work.
Conclusion
This paper presents a compelling case for the use of linear function approximation as a computationally efficient method to solve classical reinforcement learning challenges. The authors demonstrate how this technique can be applied to address issues in domains like average-cost problems and multinomial logit functions, providing both theoretical analysis and empirical results to support its effectiveness.
The key advantage of this approach lies in its simplicity and efficiency compared to more complex, non-linear representations. By representing the various components of the reinforcement learning system as a linear combination of simpler basis functions, the computational burden can be significantly reduced, opening up new possibilities for applying these techniques in real-world scenarios.
While the paper acknowledges certain caveats and limitations, it represents an important contribution to the field of reinforcement learning, showcasing the potential of linear function approximation as a powerful tool for making these algorithms more tractable and scalable. As the field continues to evolve, further research exploring the integration of linear and non-linear representations, as well as the development of principled basis function selection strategies, could lead to even more significant advances in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Matrix Low-Rank Approximation For Policy Gradient Methods
Sergio Rozada, Antonio G. Marques
0
0
Estimating a policy that maps states to actions is a central problem in reinforcement learning. Traditionally, policies are inferred from the so called value functions (VFs), but exact VF computation suffers from the curse of dimensionality. Policy gradient (PG) methods bypass this by learning directly a parametric stochastic policy. Typically, the parameters of the policy are estimated using neural networks (NNs) tuned via stochastic gradient descent. However, finding adequate NN architectures can be challenging, and convergence issues are common as well. In this paper, we put forth low-rank matrix-based models to estimate efficiently the parameters of PG algorithms. We collect the parameters of the stochastic policy into a matrix, and then, we leverage matrix-completion techniques to promote (enforce) low rank. We demonstrate via numerical studies how low-rank matrix-based policy models reduce the computational and sample complexities relative to NN models, while achieving a similar aggregated reward.
5/29/2024
Matrix Low-Rank Trust Region Policy Optimization
Sergio Rozada, Antonio G. Marques
0
0
Most methods in reinforcement learning use a Policy Gradient (PG) approach to learn a parametric stochastic policy that maps states to actions. The standard approach is to implement such a mapping via a neural network (NN) whose parameters are optimized using stochastic gradient descent. However, PG methods are prone to large policy updates that can render learning inefficient. Trust region algorithms, like Trust Region Policy Optimization (TRPO), constrain the policy update step, ensuring monotonic improvements. This paper introduces low-rank matrix-based models as an efficient alternative for estimating the parameters of TRPO algorithms. By gathering the stochastic policy's parameters into a matrix and applying matrix-completion techniques, we promote and enforce low rank. Our numerical studies demonstrate that low-rank matrix-based policy models effectively reduce both computational and sample complexities compared to NN models, while maintaining comparable aggregated rewards.
5/29/2024
🚀
Performance of NPG in Countable State-Space Average-Cost RL
Yashaswini Murthy, Isaac Grosof, Siva Theja Maguluri, R. Srikant
0
0
We consider policy optimization methods in reinforcement learning settings where the state space is arbitrarily large, or even countably infinite. The motivation arises from control problems in communication networks, matching markets, and other queueing systems. We consider Natural Policy Gradient (NPG), which is a popular algorithm for finite state spaces. Under reasonable assumptions, we derive a performance bound for NPG that is independent of the size of the state space, provided the error in policy evaluation is within a factor of the true value function. We obtain this result by establishing new policy-independent bounds on the solution to Poisson's equation, i.e., the relative value function, and by combining these bounds with previously known connections between MDPs and learning from experts.
6/3/2024
🏅
Provably Efficient Reinforcement Learning with Multinomial Logit Function Approximation
Long-Fei Li, Yu-Jie Zhang, Peng Zhao, Zhi-Hua Zhou
0
0
We study a new class of MDPs that employs multinomial logit (MNL) function approximation to ensure valid probability distributions over the state space. Despite its benefits, introducing non-linear function approximation raises significant challenges in both computational and statistical efficiency. The best-known method of Hwang and Oh [2023] has achieved an $widetilde{mathcal{O}}(kappa^{-1}dH^2sqrt{K})$ regret, where $kappa$ is a problem-dependent quantity, $d$ is the feature space dimension, $H$ is the episode length, and $K$ is the number of episodes. While this result attains the same rate in $K$ as the linear cases, the method requires storing all historical data and suffers from an $mathcal{O}(K)$ computation cost per episode. Moreover, the quantity $kappa$ can be exponentially small, leading to a significant gap for the regret compared to the linear cases. In this work, we first address the computational concerns by proposing an online algorithm that achieves the same regret with only $mathcal{O}(1)$ computation cost. Then, we design two algorithms that leverage local information to enhance statistical efficiency. They not only maintain an $mathcal{O}(1)$ computation cost per episode but achieve improved regrets of $widetilde{mathcal{O}}(kappa^{-1/2}dH^2sqrt{K})$ and $widetilde{mathcal{O}}(dH^2sqrt{K} + kappa^{-1}d^2H^2)$ respectively. Finally, we establish a lower bound, justifying the optimality of our results in $d$ and $K$. To the best of our knowledge, this is the first work that achieves almost the same computational and statistical efficiency as linear function approximation while employing non-linear function approximation for reinforcement learning.
5/28/2024