Matrix Low-Rank Trust Region Policy Optimization
2405.17625
0
0
Abstract
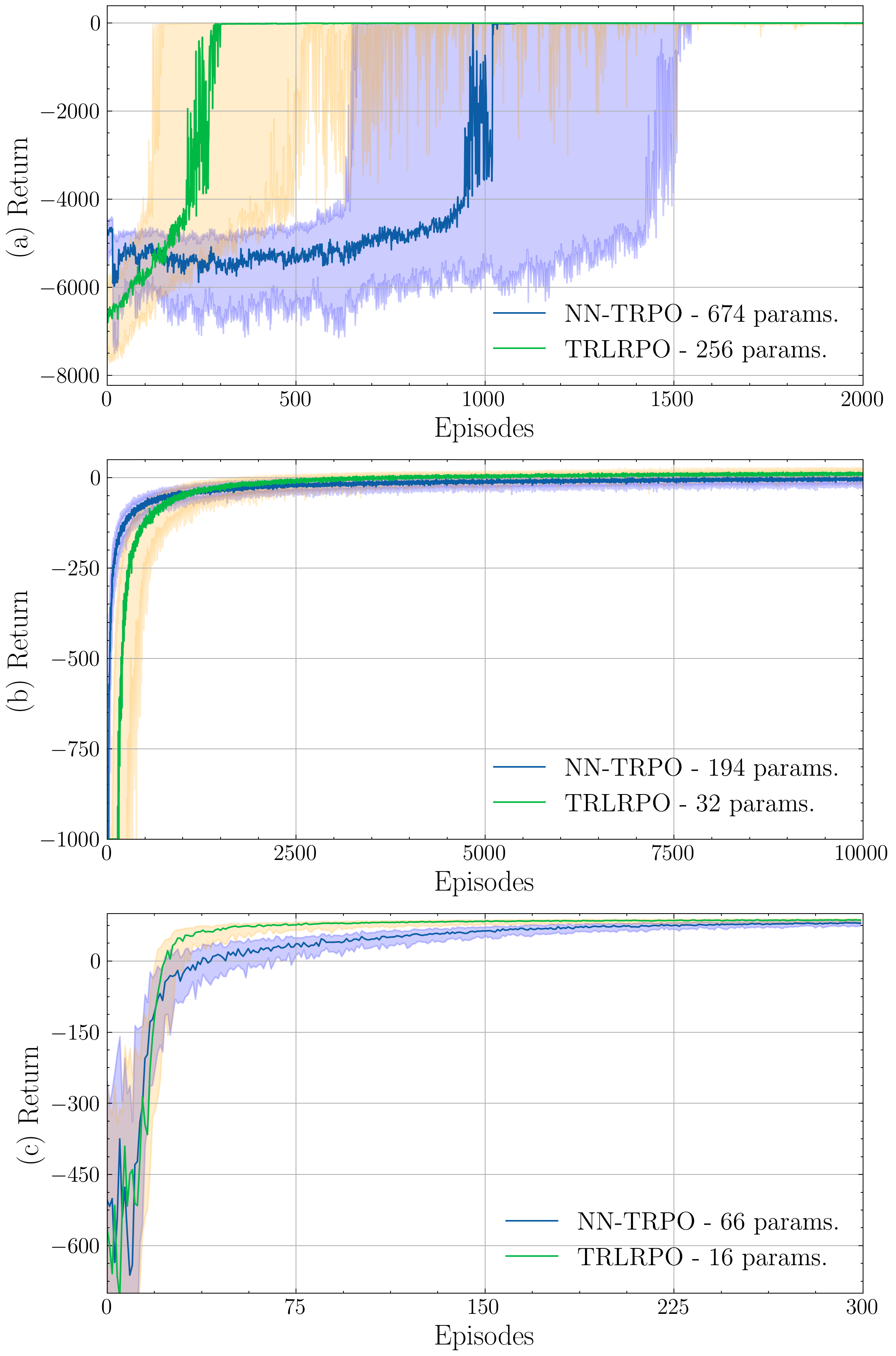
Most methods in reinforcement learning use a Policy Gradient (PG) approach to learn a parametric stochastic policy that maps states to actions. The standard approach is to implement such a mapping via a neural network (NN) whose parameters are optimized using stochastic gradient descent. However, PG methods are prone to large policy updates that can render learning inefficient. Trust region algorithms, like Trust Region Policy Optimization (TRPO), constrain the policy update step, ensuring monotonic improvements. This paper introduces low-rank matrix-based models as an efficient alternative for estimating the parameters of TRPO algorithms. By gathering the stochastic policy's parameters into a matrix and applying matrix-completion techniques, we promote and enforce low rank. Our numerical studies demonstrate that low-rank matrix-based policy models effectively reduce both computational and sample complexities compared to NN models, while maintaining comparable aggregated rewards.
Create account to get full access
Overview
- This paper introduces a new algorithm called "Matrix Low-Rank Trust Region Policy Optimization" (ML-TRPO) for reinforcement learning.
- ML-TRPO aims to improve the efficiency and scalability of policy gradient methods by exploiting the low-rank structure of the policy gradient matrix.
- The authors demonstrate that ML-TRPO outperforms standard policy gradient methods on several benchmark tasks.
Plain English Explanation
In the world of reinforcement learning, where AI agents learn to navigate complex environments and make decisions, one of the key challenges is how to optimize the agent's policy (i.e., the strategy it uses to choose actions) efficiently. Matrix Low-Rank Trust Region Policy Optimization is a new algorithm that tackles this challenge by taking advantage of the low-rank structure of the policy gradient matrix.
The policy gradient matrix is a mathematical representation of the gradients (i.e., the rate of change) of the agent's policy with respect to the various parameters that define it. By exploiting the fact that this matrix is often low-rank, meaning that it can be well-approximated by a matrix with fewer rows or columns, the authors of this paper were able to develop a more efficient optimization algorithm, called ML-TRPO.
The key idea behind ML-TRPO is to use a trust region approach, which ensures that the updated policy doesn't stray too far from the current one, combined with a low-rank approximation of the policy gradient matrix. This allows the algorithm to update the policy more efficiently, without sacrificing performance.
The authors demonstrate that ML-TRPO outperforms standard policy gradient methods, such as Proximal Policy Optimization (PPO) and Trust Region Policy Optimization (TRPO), on a variety of benchmark tasks. This suggests that exploiting the low-rank structure of the policy gradient matrix can be a powerful tool for improving the efficiency and scalability of reinforcement learning algorithms.
Technical Explanation
Matrix Low-Rank Trust Region Policy Optimization (ML-TRPO) is a new algorithm for reinforcement learning that aims to improve the efficiency and scalability of policy gradient methods by exploiting the low-rank structure of the policy gradient matrix.
The core idea behind ML-TRPO is to use a trust region approach, similar to Trust Region Policy Optimization (TRPO), to update the policy while ensuring that the new policy does not deviate too far from the current one. However, instead of using the full policy gradient matrix, ML-TRPO computes a low-rank approximation of this matrix, which can be done more efficiently.
The authors show that the policy gradient matrix in many reinforcement learning problems has a low-rank structure, meaning that it can be well-approximated by a matrix with fewer rows or columns. By exploiting this property, ML-TRPO can update the policy more efficiently without sacrificing performance.
The authors evaluate ML-TRPO on several benchmark tasks, including Mujoco environments and Atari games. The results show that ML-TRPO outperforms standard policy gradient methods, such as Proximal Policy Optimization (PPO) and TRPO, in terms of sample efficiency and final performance.
Critical Analysis
The authors of the paper provide a thorough analysis of the strengths and limitations of their proposed algorithm, ML-TRPO. One key strength is the efficient exploitation of the low-rank structure of the policy gradient matrix, which allows for faster optimization without sacrificing performance.
However, the authors also acknowledge that the low-rank assumption may not hold in all reinforcement learning problems, and that the performance of ML-TRPO may degrade in such cases. Additionally, the paper does not explore the impact of hyperparameter tuning or the scalability of ML-TRPO to large-scale problems.
Further research could investigate the theoretical properties of the low-rank approximation used in ML-TRPO, as well as explore ways to adaptively adjust the rank of the approximation based on the characteristics of the problem at hand. Additionally, more extensive empirical evaluation on a wider range of tasks and environments would help establish the generalizability of the proposed approach.
Conclusion
Matrix Low-Rank Trust Region Policy Optimization is a promising new algorithm for reinforcement learning that leverages the low-rank structure of the policy gradient matrix to improve the efficiency and scalability of policy gradient methods. By combining a trust region approach with a low-rank approximation of the policy gradient, ML-TRPO outperforms standard policy gradient methods on several benchmark tasks.
This research highlights the importance of exploiting the underlying structure of reinforcement learning problems to develop more efficient algorithms. As the field of reinforcement learning continues to advance, techniques like ML-TRPO that can take advantage of problem-specific properties may play an increasingly important role in building robust and scalable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Matrix Low-Rank Approximation For Policy Gradient Methods
Sergio Rozada, Antonio G. Marques
0
0
Estimating a policy that maps states to actions is a central problem in reinforcement learning. Traditionally, policies are inferred from the so called value functions (VFs), but exact VF computation suffers from the curse of dimensionality. Policy gradient (PG) methods bypass this by learning directly a parametric stochastic policy. Typically, the parameters of the policy are estimated using neural networks (NNs) tuned via stochastic gradient descent. However, finding adequate NN architectures can be challenging, and convergence issues are common as well. In this paper, we put forth low-rank matrix-based models to estimate efficiently the parameters of PG algorithms. We collect the parameters of the stochastic policy into a matrix, and then, we leverage matrix-completion techniques to promote (enforce) low rank. We demonstrate via numerical studies how low-rank matrix-based policy models reduce the computational and sample complexities relative to NN models, while achieving a similar aggregated reward.
5/29/2024
📈
Reinforced Model Predictive Control via Trust-Region Quasi-Newton Policy Optimization
Dean Brandner, Sergio Lucia
0
0
Model predictive control can optimally deal with nonlinear systems under consideration of constraints. The control performance depends on the model accuracy and the prediction horizon. Recent advances propose to use reinforcement learning applied to a parameterized model predictive controller to recover the optimal control performance even if an imperfect model or short prediction horizons are used. However, common reinforcement learning algorithms rely on first order updates, which only have a linear convergence rate and hence need an excessive amount of dynamic data. Higher order updates are typically intractable if the policy is approximated with neural networks due to the large number of parameters. In this work, we use a parameterized model predictive controller as policy, and leverage the small amount of necessary parameters to propose a trust-region constrained Quasi-Newton training algorithm for policy optimization with a superlinear convergence rate. We show that the required second order derivative information can be calculated by the solution of a linear system of equations. A simulation study illustrates that the proposed training algorithm outperforms other algorithms in terms of data efficiency and accuracy.
5/29/2024
Linear Function Approximation as a Computationally Efficient Method to Solve Classical Reinforcement Learning Challenges
Hari Srikanth
0
0
Neural Network based approximations of the Value function make up the core of leading Policy Based methods such as Trust Regional Policy Optimization (TRPO) and Proximal Policy Optimization (PPO). While this adds significant value when dealing with very complex environments, we note that in sufficiently low State and action space environments, a computationally expensive Neural Network architecture offers marginal improvement over simpler Value approximation methods. We present an implementation of Natural Actor Critic algorithms with actor updates through Natural Policy Gradient methods. This paper proposes that Natural Policy Gradient (NPG) methods with Linear Function Approximation as a paradigm for value approximation may surpass the performance and speed of Neural Network based models such as TRPO and PPO within these environments. Over Reinforcement Learning benchmarks Cart Pole and Acrobot, we observe that our algorithm trains much faster than complex neural network architectures, and obtains an equivalent or greater result. This allows us to recommend the use of NPG methods with Linear Function Approximation over TRPO and PPO for both traditional and sparse reward low dimensional problems.
6/3/2024
Reflective Policy Optimization
Yaozhong Gan, Renye Yan, Zhe Wu, Junliang Xing
0
0
On-policy reinforcement learning methods, like Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO), often demand extensive data per update, leading to sample inefficiency. This paper introduces Reflective Policy Optimization (RPO), a novel on-policy extension that amalgamates past and future state-action information for policy optimization. This approach empowers the agent for introspection, allowing modifications to its actions within the current state. Theoretical analysis confirms that policy performance is monotonically improved and contracts the solution space, consequently expediting the convergence procedure. Empirical results demonstrate RPO's feasibility and efficacy in two reinforcement learning benchmarks, culminating in superior sample efficiency. The source code of this work is available at https://github.com/Edgargan/RPO.
6/7/2024