LionGuard: Building a Contextualized Moderation Classifier to Tackle Localized Unsafe Content

0

Sign in to get full access
Overview
- This paper presents LionGuard, a contextualized moderation classifier designed to tackle localized unsafe content, particularly in the context of Singlish (a local English Creole in Singapore).
- The researchers developed a novel approach to build a moderation system that can effectively identify and remove harmful content while preserving the unique linguistic and cultural aspects of Singlish.
- The paper discusses the challenges of moderating content in a localized context, the development of the LionGuard system, and the evaluation of its performance.
Plain English Explanation
The paper describes a new system called LionGuard that is designed to help identify and remove harmful or unsafe content on online platforms, particularly in the context of Singlish - a form of English that is commonly used in Singapore. Singlish is a unique language that combines elements of English, Malay, Mandarin, and other local dialects, and it can be difficult for traditional content moderation systems to understand and properly handle.
LionGuard: Building a Contextualized Moderation Classifier to Tackle Localized Unsafe Content is a new approach that aims to address this challenge. The researchers developed a machine learning-based system that is trained to recognize and understand the nuances of Singlish, so that it can more accurately identify potentially harmful or unsafe content while still preserving the cultural and linguistic characteristics of the language.
By taking a contextualized approach to content moderation, the LionGuard system is able to better understand the local context and make more informed decisions about what content should be flagged or removed. This is an important step in ensuring that online platforms can effectively moderate content in a way that is sensitive to the needs and preferences of different communities and cultures.
Technical Explanation
The LionGuard: Building a Contextualized Moderation Classifier to Tackle Localized Unsafe Content paper describes the development of a novel approach to content moderation that is tailored to the unique linguistic and cultural characteristics of Singlish, a local English Creole used in Singapore.
The researchers first provide an overview of Singlish, highlighting its distinct vocabulary, grammar, and usage patterns that can pose challenges for traditional content moderation systems. They then outline the design and implementation of the LionGuard system, which leverages a contextualized machine learning-based classifier to identify potentially harmful or unsafe content in Singlish-based text.
The key elements of the LionGuard system include:
- A custom dataset of Singlish text annotated for safety and toxicity,
- A multi-task learning approach that jointly models content safety and linguistic characteristics,
- Incorporation of local cultural and contextual knowledge to improve classification accuracy,
- Extensive evaluation of the system's performance on Singlish-based content, including comparisons to existing state-of-the-art models.
The researchers' experiments demonstrate that the LionGuard system significantly outperforms generic content moderation models when it comes to identifying unsafe content in Singlish-based text. The paper also discusses the broader implications of their approach, including the potential for applying similar contextualized moderation strategies to other localized language communities.
Critical Analysis
The LionGuard: Building a Contextualized Moderation Classifier to Tackle Localized Unsafe Content paper presents a novel and compelling approach to content moderation that addresses the challenges of handling localized language variations, such as Singlish.
One of the key strengths of the LionGuard system is its ability to incorporate local cultural and contextual knowledge into the classification model, allowing it to better understand the nuances of Singlish and make more informed decisions about content safety. This is an important step in ensuring that content moderation systems are sensitive to the needs and preferences of diverse communities.
However, the paper also acknowledges several limitations and areas for further research. For example, the authors note that the LionGuard system is currently focused on text-based content, and it would be valuable to explore its applicability to other modalities, such as images or audio. Additionally, the evaluation of the system is limited to a specific dataset and geographic region, and it would be beneficial to assess its performance in other contexts.
LORA-Guard: Parameter-Efficient Guardrail Adaptation for Content Safety and AEGiS: Online Adaptive AI Content Safety Moderation are two related approaches that could potentially be combined with or compared to the LionGuard system to further enhance its capabilities and generalizability.
Overall, the LionGuard paper represents an important step forward in the field of content moderation, particularly in the context of localized language variations. The researchers' thoughtful approach to incorporating cultural and linguistic context into the classification model is a valuable contribution, and their work serves as an inspiration for further research and development in this area.
Conclusion
The LionGuard: Building a Contextualized Moderation Classifier to Tackle Localized Unsafe Content paper presents a novel approach to content moderation that addresses the unique challenges of handling localized language variations, such as Singlish. By developing a contextualized machine learning-based classifier that incorporates local cultural and linguistic knowledge, the researchers have demonstrated the potential for more effective and sensitive content moderation systems.
The LionGuard system's strong performance on Singlish-based content, as compared to generic models, highlights the importance of taking a localized approach to content moderation. As online platforms continue to serve increasingly diverse global audiences, the ability to effectively moderate content in a way that respects local cultural and linguistic norms will become increasingly critical.
The insights and techniques presented in this paper could have far-reaching implications for the development of more robust and inclusive content moderation systems, not just for Singlish, but for a wide range of localized language communities around the world. By continuing to explore and refine approaches like LionGuard, researchers and practitioners can work towards creating online spaces that are safe, inclusive, and respectful of the rich diversity of human expression.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LionGuard: Building a Contextualized Moderation Classifier to Tackle Localized Unsafe Content
Jessica Foo, Shaun Khoo
As large language models (LLMs) become increasingly prevalent in a wide variety of applications, concerns about the safety of their outputs have become more significant. Most efforts at safety-tuning or moderation today take on a predominantly Western-centric view of safety, especially for toxic, hateful, or violent speech. In this paper, we describe LionGuard, a Singapore-contextualized moderation classifier that can serve as guardrails against unsafe LLM outputs. When assessed on Singlish data, LionGuard outperforms existing widely-used moderation APIs, which are not finetuned for the Singapore context, by 14% (binary) and up to 51% (multi-label). Our work highlights the benefits of localization for moderation classifiers and presents a practical and scalable approach for low-resource languages.
Read more7/22/2024
0
A Framework for Real-time Safeguarding the Text Generation of Large Language
Ximing Dong, Dayi Lin, Shaowei Wang, Ahmed E. Hassan
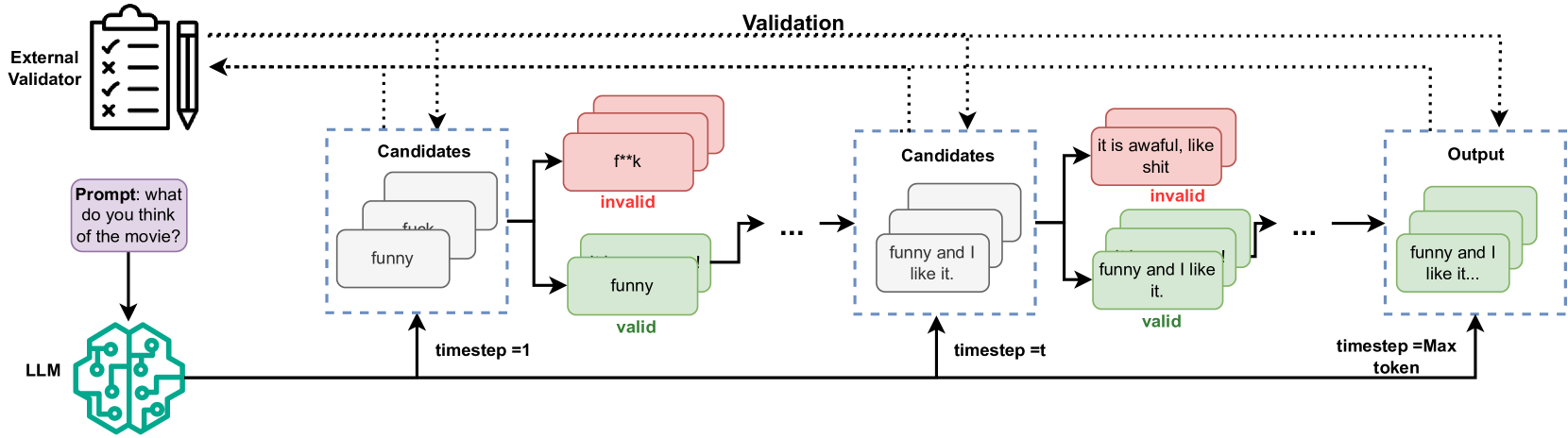
Large Language Models (LLMs) have significantly advanced natural language processing (NLP) tasks but also pose ethical and societal risks due to their propensity to generate harmful content. To address this, various approaches have been developed to safeguard LLMs from producing unsafe content. However, existing methods have limitations, including the need for training specific control models and proactive intervention during text generation, that lead to quality degradation and increased computational overhead. To mitigate those limitations, we propose LLMSafeGuard, a lightweight framework to safeguard LLM text generation in real-time. LLMSafeGuard integrates an external validator into the beam search algorithm during decoding, rejecting candidates that violate safety constraints while allowing valid ones to proceed. We introduce a similarity based validation approach, simplifying constraint introduction and eliminating the need for control model training. Additionally, LLMSafeGuard employs a context-wise timing selection strategy, intervening LLMs only when necessary. We evaluate LLMSafeGuard on two tasks, detoxification and copyright safeguarding, and demonstrate its superior performance over SOTA baselines. For instance, LLMSafeGuard reduces the average toxic score of. LLM output by 29.7% compared to the best baseline meanwhile preserving similar linguistic quality as natural output in detoxification task. Similarly, in the copyright task, LLMSafeGuard decreases the Longest Common Subsequence (LCS) by 56.2% compared to baselines. Moreover, our context-wise timing selection strategy reduces inference time by at least 24% meanwhile maintaining comparable effectiveness as validating each time step. LLMSafeGuard also offers tunable parameters to balance its effectiveness and efficiency.
Read more5/3/2024

0
SLM as Guardian: Pioneering AI Safety with Small Language Models
Ohjoon Kwon, Donghyeon Jeon, Nayoung Choi, Gyu-Hwung Cho, Changbong Kim, Hyunwoo Lee, Inho Kang, Sun Kim, Taiwoo Park
Most prior safety research of large language models (LLMs) has focused on enhancing the alignment of LLMs to better suit the safety requirements of humans. However, internalizing such safeguard features into larger models brought challenges of higher training cost and unintended degradation of helpfulness. To overcome such challenges, a modular approach employing a smaller LLM to detect harmful user queries is regarded as a convenient solution in designing LLM-based system with safety requirements. In this paper, we leverage a smaller LLM for both harmful query detection and safeguard response generation. We introduce our safety requirements and the taxonomy of harmfulness categories, and then propose a multi-task learning mechanism fusing the two tasks into a single model. We demonstrate the effectiveness of our approach, providing on par or surpassing harmful query detection and safeguard response performance compared to the publicly available LLMs.
Read more5/31/2024

0
New!HiddenGuard: Fine-Grained Safe Generation with Specialized Representation Router
Lingrui Mei, Shenghua Liu, Yiwei Wang, Baolong Bi, Ruibin Yuan, Xueqi Cheng
As Large Language Models (LLMs) grow increasingly powerful, ensuring their safety and alignment with human values remains a critical challenge. Ideally, LLMs should provide informative responses while avoiding the disclosure of harmful or sensitive information. However, current alignment approaches, which rely heavily on refusal strategies, such as training models to completely reject harmful prompts or applying coarse filters are limited by their binary nature. These methods either fully deny access to information or grant it without sufficient nuance, leading to overly cautious responses or failures to detect subtle harmful content. For example, LLMs may refuse to provide basic, public information about medication due to misuse concerns. Moreover, these refusal-based methods struggle to handle mixed-content scenarios and lack the ability to adapt to context-dependent sensitivities, which can result in over-censorship of benign content. To overcome these challenges, we introduce HiddenGuard, a novel framework for fine-grained, safe generation in LLMs. HiddenGuard incorporates Prism (rePresentation Router for In-Stream Moderation), which operates alongside the LLM to enable real-time, token-level detection and redaction of harmful content by leveraging intermediate hidden states. This fine-grained approach allows for more nuanced, context-aware moderation, enabling the model to generate informative responses while selectively redacting or replacing sensitive information, rather than outright refusal. We also contribute a comprehensive dataset with token-level fine-grained annotations of potentially harmful information across diverse contexts. Our experiments demonstrate that HiddenGuard achieves over 90% in F1 score for detecting and redacting harmful content while preserving the overall utility and informativeness of the model's responses.
Read more10/4/2024