LiSenNet: Lightweight Sub-band and Dual-Path Modeling for Real-Time Speech Enhancement

0
Sign in to get full access
Overview
- LiSenNet: A lightweight speech enhancement model for real-time applications
- Leverages sub-band and dual-path modeling to achieve high performance with low complexity
- Supported by grants from the National Natural Science Foundation of China and other organizations
Plain English Explanation
LiSenNet is a new speech enhancement model designed to work well in real-time applications with limited computing power. Most speech enhancement models are quite complex, but this one takes a different approach to achieve good performance with much lower complexity.
The key ideas are:
-
Sub-band modeling: Instead of processing the full audio spectrum, LiSenNet splits the audio into multiple frequency bands and processes each one separately. This allows the model to focus on the most important parts of the spectrum.
-
Dual-path architecture: LiSenNet has two parallel processing paths - one that focuses on the overall signal and one that focuses on the details. By combining these two perspectives, it can produce higher quality enhanced speech.
These techniques allow LiSenNet to achieve state-of-the-art speech enhancement performance while being much smaller and faster than other models. This makes it well-suited for deployment on resource-constrained devices like smartphones for real-time applications.
Technical Explanation
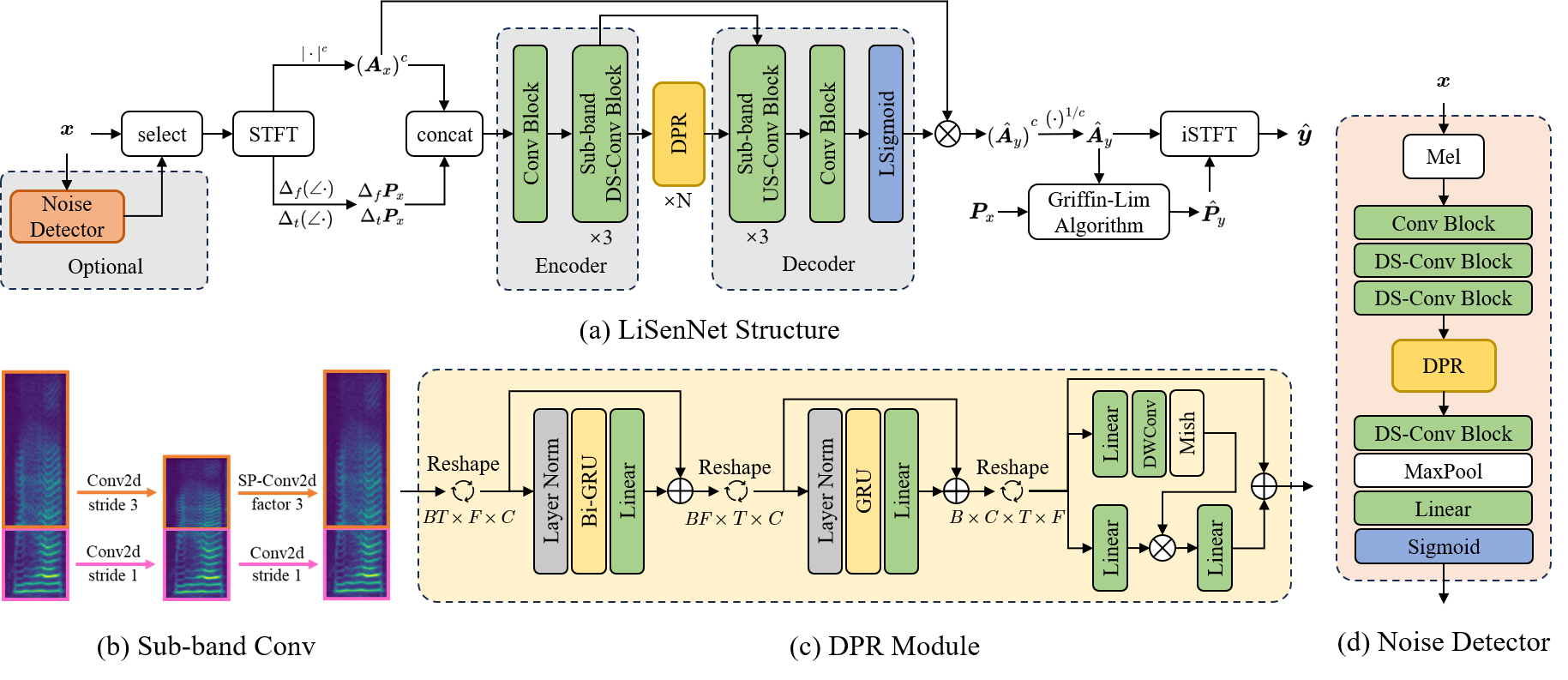
LiSenNet is a novel speech enhancement model that leverages sub-band and dual-path modeling to achieve high performance with low complexity.
The sub-band approach splits the audio spectrum into multiple frequency bands and processes each one independently using a shared lightweight network. This allows the model to focus its capacity on the most important frequency regions for speech enhancement, rather than trying to process the full wideband signal.
The dual-path architecture consists of a global path that models the overall signal characteristics and a detail path that captures fine-grained details. These two perspectives are then combined to produce the final enhanced speech output. This dual-path design helps LiSenNet achieve high perceptual quality without excessive complexity.
Experiments on standard speech enhancement benchmarks demonstrate that LiSenNet outperforms other lightweight models while being significantly smaller and faster. This makes it well-suited for real-time speech enhancement on resource-constrained edge devices.
Critical Analysis
The main strengths of the LiSenNet approach are its ability to achieve state-of-the-art performance with much lower complexity compared to other models. This is an important innovation for enabling high-quality speech enhancement on devices with limited computing power, like smartphones.
However, the paper does not provide a detailed analysis of the computational and memory requirements of LiSenNet compared to other models. While the results demonstrate its efficiency, more quantitative metrics would help users better understand the practical tradeoffs.
Additionally, the paper focuses on evaluating LiSenNet on standard speech enhancement benchmarks, but does not explore its performance in real-world deployment scenarios. Further research is needed to understand how the model would fare in noisy, reverberant environments encountered in practical applications.
Conclusion
LiSenNet represents an important advance in speech enhancement technology, enabling high-quality performance with much lower complexity than previous models. This makes it well-suited for deployment on resource-constrained devices for real-time applications like mobile voice assistants and teleconferencing.
The sub-band and dual-path modeling techniques used in LiSenNet provide an effective way to balance perceptual quality and computational efficiency, paving the way for more widespread adoption of speech enhancement in edge computing scenarios. Further research is needed to fully understand the practical implications of this work, but the results presented are a promising step forward.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LiSenNet: Lightweight Sub-band and Dual-Path Modeling for Real-Time Speech Enhancement
Haoyin Yan, Jie Zhang, Cunhang Fan, Yeping Zhou, Peiqi Liu
Speech enhancement (SE) aims to extract the clean waveform from noise-contaminated measurements to improve the speech quality and intelligibility. Although learning-based methods can perform much better than traditional counterparts, the large computational complexity and model size heavily limit the deployment on latency-sensitive and low-resource edge devices. In this work, we propose a lightweight SE network (LiSenNet) for real-time applications. We design sub-band downsampling and upsampling blocks and a dual-path recurrent module to capture band-aware features and time-frequency patterns, respectively. A noise detector is developed to detect noisy regions in order to perform SE adaptively and save computational costs. Compared to recent higher-resource-dependent baseline models, the proposed LiSenNet can achieve a competitive performance with only 37k parameters (half of the state-of-the-art model) and 56M multiply-accumulate (MAC) operations per second.
Read more9/24/2024

0
DSP-informed bandwidth extension using locally-conditioned excitation and linear time-varying filter subnetworks
Shahan Nercessian, Alexey Lukin, Johannes Imort
In this paper, we propose a dual-stage architecture for bandwidth extension (BWE) increasing the effective sampling rate of speech signals from 8 kHz to 48 kHz. Unlike existing end-to-end deep learning models, our proposed method explicitly models BWE using excitation and linear time-varying (LTV) filter stages. The excitation stage broadens the spectrum of the input, while the filtering stage properly shapes it based on outputs from an acoustic feature predictor. To this end, an acoustic feature loss term can implicitly promote the excitation subnetwork to produce white spectra in the upper frequency band to be synthesized. Experimental results demonstrate that the added inductive bias provided by our approach can improve upon BWE results using the generators from both SEANet or HiFi-GAN as exciters, and that our means of adapting processing with acoustic feature predictions is more effective than that used in HiFi-GAN-2. Secondary contributions include extensions of the SEANet model to accommodate local conditioning information, as well as the application of HiFi-GAN-2 for the BWE problem.
Read more7/23/2024
0
Speech enhancement deep-learning architecture for efficient edge processing
Monisankha Pal, Arvind Ramanathan, Ted Wada, Ashutosh Pandey
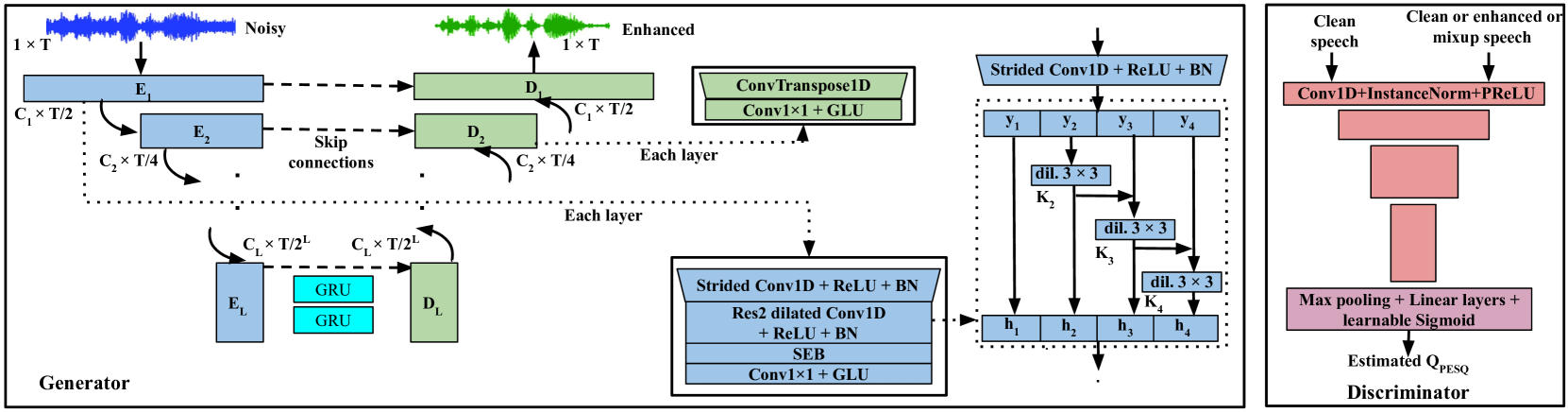
Deep learning has become a de facto method of choice for speech enhancement tasks with significant improvements in speech quality. However, real-time processing with reduced size and computations for low-power edge devices drastically degrades speech quality. Recently, transformer-based architectures have greatly reduced the memory requirements and provided ways to improve the model performance through local and global contexts. However, the transformer operations remain computationally heavy. In this work, we introduce WaveUNet squeeze-excitation Res2 (WSR)-based metric generative adversarial network (WSR-MGAN) architecture that can be efficiently implemented on low-power edge devices for noise suppression tasks while maintaining speech quality. We utilize multi-scale features using Res2Net blocks that can be related to spectral content used in speech-processing tasks. In the generator, we integrate squeeze-excitation blocks (SEB) with multi-scale features for maintaining local and global contexts along with gated recurrent units (GRUs). The proposed approach is optimized through a combined loss function calculated over raw waveform, multi-resolution magnitude spectrogram, and objective metrics using a metric discriminator. Experimental results in terms of various objective metrics on VoiceBank+DEMAND and DNS-2020 challenge datasets demonstrate that the proposed speech enhancement (SE) approach outperforms the baselines and achieves state-of-the-art (SOTA) performance in the time domain.
Read more5/28/2024

0
A Lightweight and Real-Time Binaural Speech Enhancement Model with Spatial Cues Preservation
Jingyuan Wang, Jie Zhang, Shihao Chen, Miao Sun
Binaural speech enhancement (BSE) aims to jointly improve the speech quality and intelligibility of noisy signals received by hearing devices and preserve the spatial cues of the target for natural listening. Existing methods often suffer from the compromise between noise reduction (NR) capacity and spatial cues preservation (SCP) accuracy and a high computational demand in complex acoustic scenes. In this work, we present a learning-based lightweight binaural complex convolutional network (LBCCN), which excels in NR by filtering low-frequency bands and keeping the rest. Additionally, our approach explicitly incorporates the estimation of interchannel relative acoustic transfer function to ensure the spatial cues fidelity and speech clarity. Results show that the proposed LBCCN can achieve a comparable NR performance to state-of-the-art methods under various noise conditions, but with a much lower computational cost and a better SCP. The reproducible code and audio examples are available at https://github.com/jywanng/LBCCN.
Read more9/20/2024