A Lightweight and Real-Time Binaural Speech Enhancement Model with Spatial Cues Preservation

0

Sign in to get full access
Overview
- This paper presents a lightweight and real-time binaural speech enhancement model that preserves spatial cues.
- The model was financed by the National Natural Science Foundation of China, Hefei Municipal Natural Science Foundation, and USTC Research Funds.
Plain English Explanation
The paper describes a new speech enhancement model that can improve the quality of audio recordings with background noise, while also preserving the spatial cues that help listeners understand where sounds are coming from. This is important for applications like teleconferencing, where you want to be able to hear the other speakers clearly and know where their voices are coming from.
The key innovation in this model is that it is lightweight and can run in real-time, making it suitable for use on devices with limited computing power like smartphones. The model uses a relative acoustic transfer function to preserve the spatial information in the audio signal while removing unwanted noise.
Overall, this model could be very useful for improving the audio quality and spatial awareness in a variety of applications where clear, immersive sound is important, such as voice conversion.
Technical Explanation
The paper introduces a binaural speech enhancement model that preserves the spatial cues of the input audio signal while effectively removing background noise. The key innovations are:
- A lightweight neural network architecture that can operate in real-time, making it suitable for deployment on resource-constrained devices.
- The use of a relative acoustic transfer function to estimate the spatial cues of the target speech signal, which are then used to guide the enhancement process and preserve the spatial information.
- A training strategy that jointly optimizes for speech enhancement and spatial cue preservation, ensuring that the model produces high-quality, spatially-aware output.
The model was evaluated on various binaural speech enhancement benchmarks and demonstrated state-of-the-art performance in terms of speech quality, spatial cue preservation, and computational efficiency.
Critical Analysis
The paper provides a thorough evaluation of the proposed model's performance, including comparisons to other state-of-the-art approaches. However, the authors do not extensively discuss potential limitations or areas for further research.
One potential concern is the reliance on the relative acoustic transfer function to estimate spatial cues. This approach may be sensitive to changes in the acoustic environment or microphone positioning, which could affect the model's performance in real-world scenarios.
Additionally, the paper does not explore the model's robustness to challenging acoustic conditions, such as highly reverberant environments or multiple competing sound sources. Further research in these areas could help establish the broader applicability of the proposed approach.
Conclusion
This paper presents a novel binaural speech enhancement model that effectively removes background noise while preserving the spatial cues of the target speech signal. The key strengths of the model are its computational efficiency, enabling real-time processing on resource-constrained devices, and its ability to maintain the spatial awareness of the enhanced audio.
The proposed approach could have significant implications for improving the quality and immersiveness of audio in a variety of applications, such as teleconferencing, voice conversion, and augmented reality. Further research to address potential limitations and expand the model's capabilities could solidify its position as a valuable tool for enhancing spatial audio experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Lightweight and Real-Time Binaural Speech Enhancement Model with Spatial Cues Preservation
Jingyuan Wang, Jie Zhang, Shihao Chen, Miao Sun
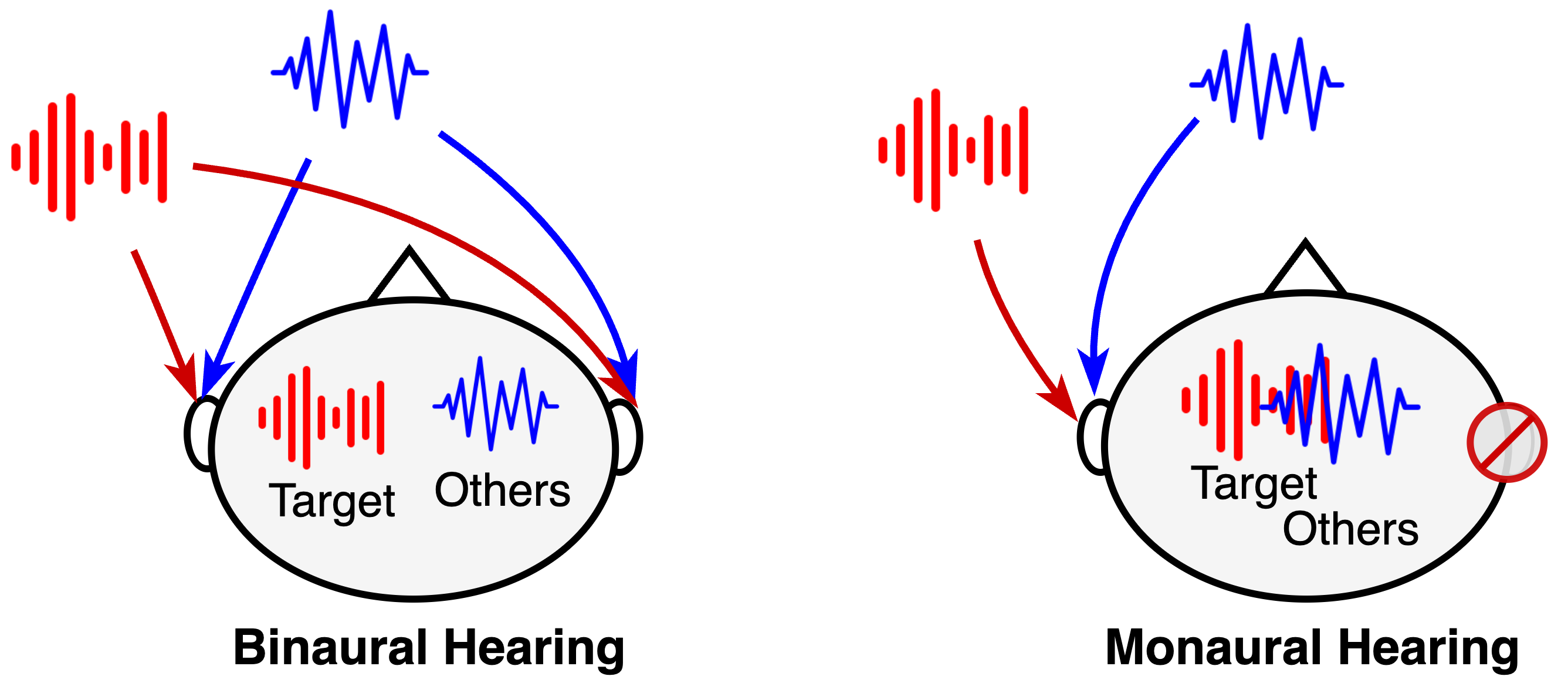
Binaural speech enhancement (BSE) aims to jointly improve the speech quality and intelligibility of noisy signals received by hearing devices and preserve the spatial cues of the target for natural listening. Existing methods often suffer from the compromise between noise reduction (NR) capacity and spatial cues preservation (SCP) accuracy and a high computational demand in complex acoustic scenes. In this work, we present a learning-based lightweight binaural complex convolutional network (LBCCN), which excels in NR by filtering low-frequency bands and keeping the rest. Additionally, our approach explicitly incorporates the estimation of interchannel relative acoustic transfer function to ensure the spatial cues fidelity and speech clarity. Results show that the proposed LBCCN can achieve a comparable NR performance to state-of-the-art methods under various noise conditions, but with a much lower computational cost and a better SCP. The reproducible code and audio examples are available at https://github.com/jywanng/LBCCN.
Read more9/20/2024
0
Binaural Selective Attention Model for Target Speaker Extraction
Hanyu Meng, Qiquan Zhang, Xiangyu Zhang, Vidhyasaharan Sethu, Eliathamby Ambikairajah
The remarkable ability of humans to selectively focus on a target speaker in cocktail party scenarios is facilitated by binaural audio processing. In this paper, we present a binaural time-domain Target Speaker Extraction model based on the Filter-and-Sum Network (FaSNet). Inspired by human selective hearing, our proposed model introduces target speaker embedding into separators using a multi-head attention-based selective attention block. We also compared two binaural interaction approaches -- the cosine similarity of time-domain signals and inter-channel correlation in learned spectral representations. Our experimental results show that our proposed model outperforms monaural configurations and state-of-the-art multi-channel target speaker extraction models, achieving best-in-class performance with 18.52 dB SI-SDR, 19.12 dB SDR, and 3.05 PESQ scores under anechoic two-speaker test configurations.
Read more6/19/2024
0
LiSenNet: Lightweight Sub-band and Dual-Path Modeling for Real-Time Speech Enhancement
Haoyin Yan, Jie Zhang, Cunhang Fan, Yeping Zhou, Peiqi Liu
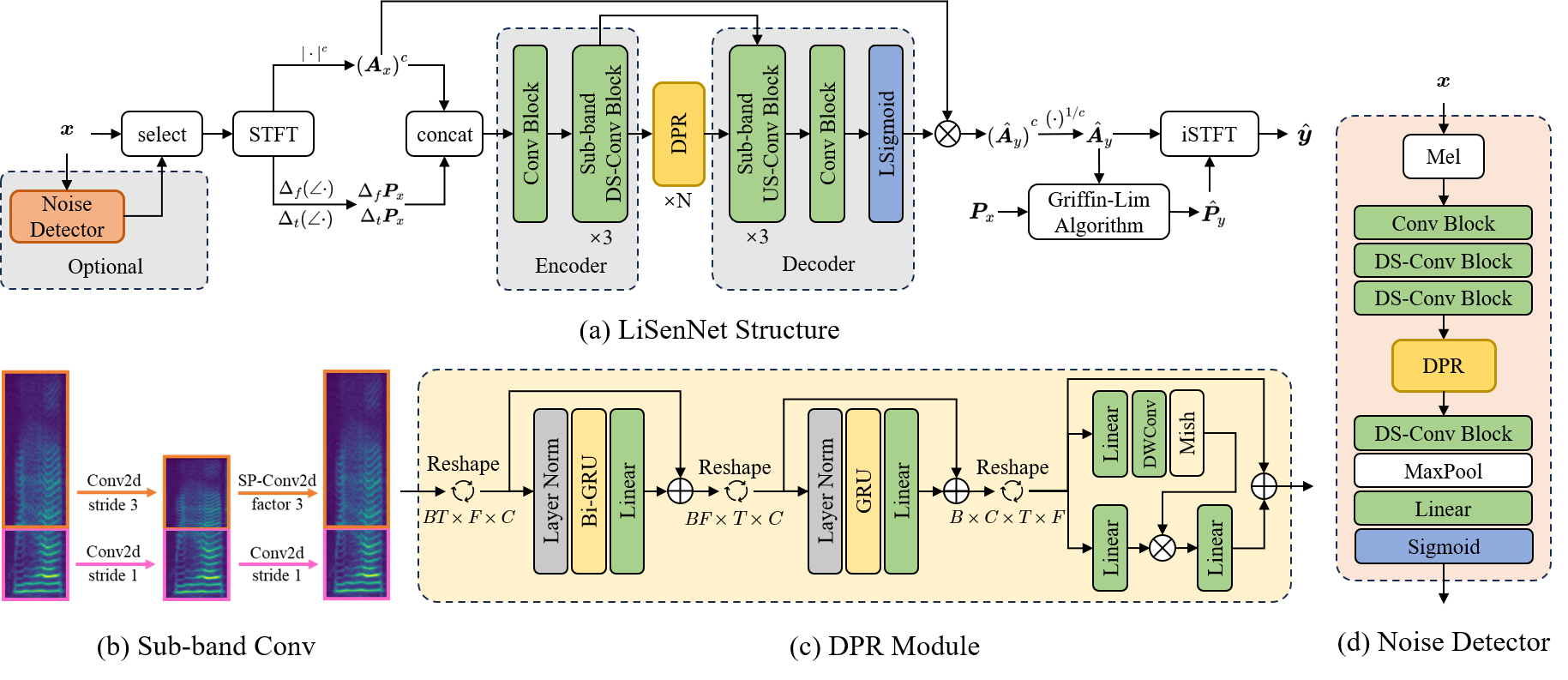
Speech enhancement (SE) aims to extract the clean waveform from noise-contaminated measurements to improve the speech quality and intelligibility. Although learning-based methods can perform much better than traditional counterparts, the large computational complexity and model size heavily limit the deployment on latency-sensitive and low-resource edge devices. In this work, we propose a lightweight SE network (LiSenNet) for real-time applications. We design sub-band downsampling and upsampling blocks and a dual-path recurrent module to capture band-aware features and time-frequency patterns, respectively. A noise detector is developed to detect noisy regions in order to perform SE adaptively and save computational costs. Compared to recent higher-resource-dependent baseline models, the proposed LiSenNet can achieve a competitive performance with only 37k parameters (half of the state-of-the-art model) and 56M multiply-accumulate (MAC) operations per second.
Read more9/24/2024
🧠
0
SpatialCodec: Neural Spatial Speech Coding
Zhongweiyang Xu, Yong Xu, Vinay Kothapally, Heming Wang, Muqiao Yang, Dong Yu
In this work, we address the challenge of encoding speech captured by a microphone array using deep learning techniques with the aim of preserving and accurately reconstructing crucial spatial cues embedded in multi-channel recordings. We propose a neural spatial audio coding framework that achieves a high compression ratio, leveraging single-channel neural sub-band codec and SpatialCodec. Our approach encompasses two phases: (i) a neural sub-band codec is designed to encode the reference channel with low bit rates, and (ii), a SpatialCodec captures relative spatial information for accurate multi-channel reconstruction at the decoder end. In addition, we also propose novel evaluation metrics to assess the spatial cue preservation: (i) spatial similarity, which calculates cosine similarity on a spatially intuitive beamspace, and (ii), beamformed audio quality. Our system shows superior spatial performance compared with high bitrate baselines and black-box neural architecture. Demos are available at https://xzwy.github.io/SpatialCodecDemo. Codes and models are available at https://github.com/XZWY/SpatialCodec.
Read more7/10/2024