LLaMA-Omni: Seamless Speech Interaction with Large Language Models

0

Sign in to get full access
Overview
- LLaMA-Omni is a model that enables seamless speech interaction with large language models.
- It can understand speech, generate speech, and engage in conversational interactions.
- This allows users to communicate with language models in a more natural, intuitive way.
Plain English Explanation
LLaMA-Omni is a new model that combines the power of large language models with speech capabilities. This means you can talk to the model and it can understand you, as well as generate its own speech responses.
Rather than typing everything, you can have a more natural, conversational interaction. The model can hear what you say, process the meaning, and then respond by generating human-like speech. This makes interacting with language models much more seamless and intuitive.
Instead of being limited to text-based inputs and outputs, LLaMA-Omni allows for a full back-and-forth dialogue where you can speak to the model and it can talk back to you. This opens up new possibilities for how people can interact with and leverage the capabilities of large language models.
Technical Explanation
LLaMA-Omni is built on top of the LLaMA large language model, adding speech recognition and text-to-speech capabilities. This allows the model to accept speech input, process the meaning, and generate spoken responses.
The speech recognition component transcribes the user's speech into text, which is then fed into the language model. The language model generates a text response, which is then converted to synthetic speech using a text-to-speech module.
This end-to-end pipeline enables a conversational interaction where the user can speak naturally and receive spoken responses from the model. Experiments show this approach achieves high accuracy on speech recognition and natural language understanding tasks, facilitating smooth, natural dialogue.
Critical Analysis
The paper highlights the potential benefits of integrating speech capabilities with large language models, but also acknowledges some limitations and areas for further research.
One key limitation is the reliance on external speech recognition and text-to-speech modules, which could introduce errors or latency into the interaction. Developing more tightly integrated speech components may be an area for improvement.
Additionally, the paper does not address potential biases or safety concerns that may arise when language models can engage in open-ended spoken dialogue. Careful consideration of these issues will be important as the technology is developed further.
Overall, LLaMA-Omni represents an important step towards making language models more accessible and intuitive to use through natural speech interaction. However, continued research and thoughtful development will be needed to realize the full potential of this approach while addressing potential challenges.
Conclusion
LLaMA-Omni is a novel model that enables seamless speech interaction with large language models. By combining speech recognition, language understanding, and text-to-speech capabilities, it allows users to communicate with language models in a more natural, conversational way.
This development opens up new possibilities for how people can leverage the knowledge and capabilities of large language models, making the interaction more intuitive and accessible. As the technology continues to evolve, it will be important to address potential challenges and ensure the safe and responsible deployment of such systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLaMA-Omni: Seamless Speech Interaction with Large Language Models
Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui Ma, Shaolei Zhang, Yang Feng
Models like GPT-4o enable real-time interaction with large language models (LLMs) through speech, significantly enhancing user experience compared to traditional text-based interaction. However, there is still a lack of exploration on how to build speech interaction models based on open-source LLMs. To address this, we propose LLaMA-Omni, a novel model architecture designed for low-latency and high-quality speech interaction with LLMs. LLaMA-Omni integrates a pretrained speech encoder, a speech adaptor, an LLM, and a streaming speech decoder. It eliminates the need for speech transcription, and can simultaneously generate text and speech responses directly from speech instructions with extremely low latency. We build our model based on the latest Llama-3.1-8B-Instruct model. To align the model with speech interaction scenarios, we construct a dataset named InstructS2S-200K, which includes 200K speech instructions and corresponding speech responses. Experimental results show that compared to previous speech-language models, LLaMA-Omni provides better responses in both content and style, with a response latency as low as 226ms. Additionally, training LLaMA-Omni takes less than 3 days on just 4 GPUs, paving the way for the efficient development of speech-language models in the future.
Read more9/11/2024

0
Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
Zhifei Xie, Changqiao Wu
Recent advances in language models have achieved significant progress. GPT-4o, as a new milestone, has enabled real-time conversations with humans, demonstrating near-human natural fluency. Such human-computer interaction necessitates models with the capability to perform reasoning directly with the audio modality and generate output in streaming. However, this remains beyond the reach of current academic models, as they typically depend on extra TTS systems for speech synthesis, resulting in undesirable latency. This paper introduces the Mini-Omni, an audio-based end-to-end conversational model, capable of real-time speech interaction. To achieve this capability, we propose a text-instructed speech generation method, along with batch-parallel strategies during inference to further boost the performance. Our method also helps to retain the original model's language capabilities with minimal degradation, enabling other works to establish real-time interaction capabilities. We call this training method Any Model Can Talk. We also introduce the VoiceAssistant-400K dataset to fine-tune models optimized for speech output. To our best knowledge, Mini-Omni is the first fully end-to-end, open-source model for real-time speech interaction, offering valuable potential for future research.
Read more9/2/2024
🗣️
0
A Full-duplex Speech Dialogue Scheme Based On Large Language Models
Peng Wang, Songshuo Lu, Yaohua Tang, Sijie Yan, Yuanjun Xiong, Wei Xia
We present a generative dialogue system capable of operating in a full-duplex manner, allowing for seamless interaction. It is based on a large language model (LLM) carefully aligned to be aware of a perception module, a motor function module, and the concept of a simple finite state machine (called neural FSM) with two states. The perception and motor function modules operate simultaneously, allowing the system to simultaneously speak and listen to the user. The LLM generates textual tokens for inquiry responses and makes autonomous decisions to start responding to, wait for, or interrupt the user by emitting control tokens to the neural FSM. All these tasks of the LLM are carried out as next token prediction on a serialized view of the dialogue in real-time. In automatic quality evaluations simulating real-life interaction, the proposed system reduces the average conversation response latency by more than 3 folds compared with LLM-based half-duplex dialogue systems while responding within less than 500 milliseconds in more than 50% of evaluated interactions. Running a LLM with only 8 billion parameters, our system exhibits a 8% higher interruption precision rate than the best available commercial LLM for voice-based dialogue.
Read more5/31/2024
0
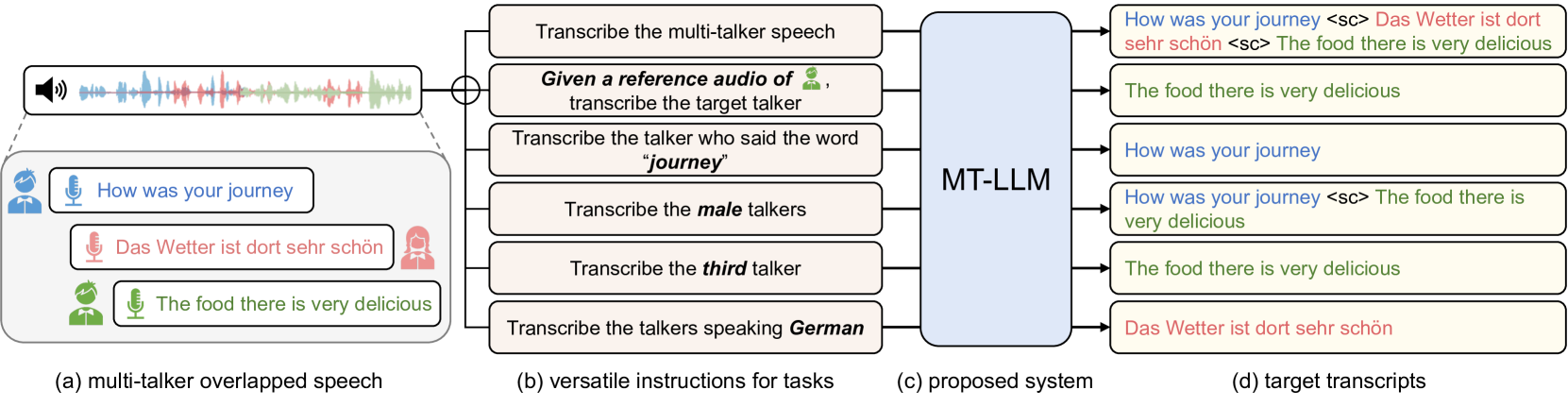
New!Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
Lingwei Meng, Shujie Hu, Jiawen Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, Xixin Wu, Xunying Liu, Helen Meng
Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Read more9/16/2024