A Full-duplex Speech Dialogue Scheme Based On Large Language Models
2405.19487
0
0
🗣️
Abstract
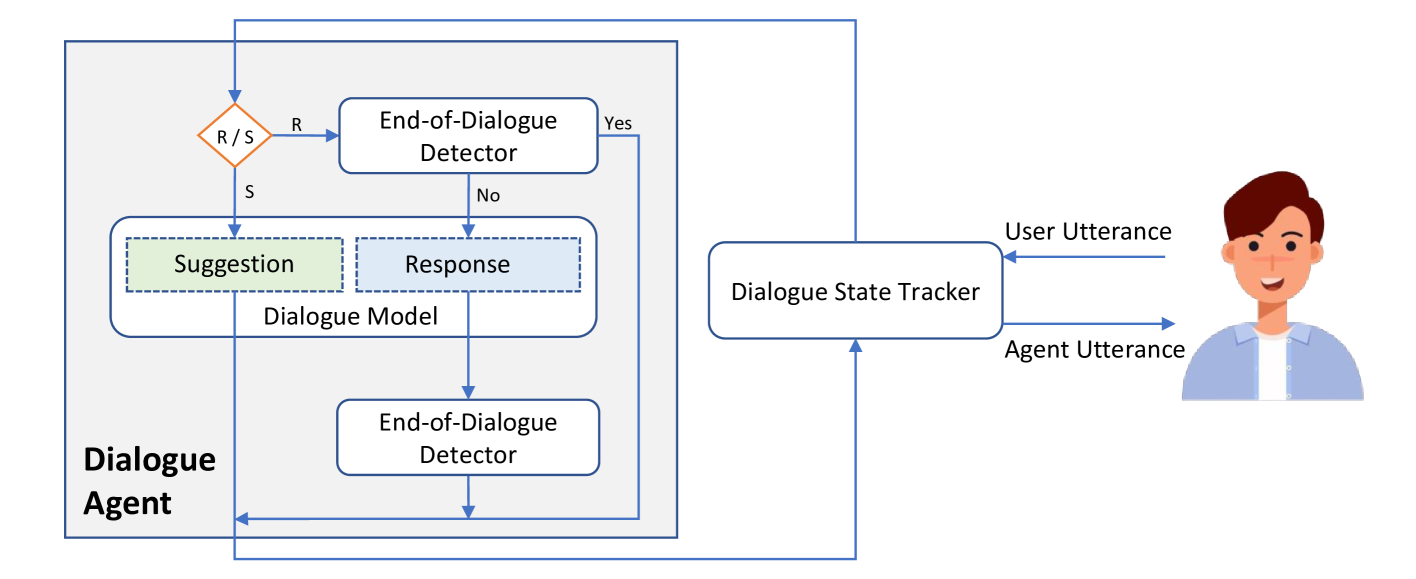
We present a generative dialogue system capable of operating in a full-duplex manner, allowing for seamless interaction. It is based on a large language model (LLM) carefully aligned to be aware of a perception module, a motor function module, and the concept of a simple finite state machine (called neural FSM) with two states. The perception and motor function modules operate simultaneously, allowing the system to simultaneously speak and listen to the user. The LLM generates textual tokens for inquiry responses and makes autonomous decisions to start responding to, wait for, or interrupt the user by emitting control tokens to the neural FSM. All these tasks of the LLM are carried out as next token prediction on a serialized view of the dialogue in real-time. In automatic quality evaluations simulating real-life interaction, the proposed system reduces the average conversation response latency by more than 3 folds compared with LLM-based half-duplex dialogue systems while responding within less than 500 milliseconds in more than 50% of evaluated interactions. Running a LLM with only 8 billion parameters, our system exhibits a 8% higher interruption precision rate than the best available commercial LLM for voice-based dialogue.
Create account to get full access
Overview
- Presents a generative dialogue system capable of full-duplex operation, allowing seamless interaction
- Based on a large language model (LLM) aligned with perception, motor function, and a simple finite state machine (neural FSM)
- Perception and motor function modules operate simultaneously, enabling the system to speak and listen to the user at the same time
- LLM generates textual responses and controls the neural FSM to decide when to respond, wait, or interrupt the user
- Evaluated against half-duplex dialogue systems, the proposed system reduces average response latency by over 3 times and responds within 500ms in over 50% of interactions
- Running an 8 billion parameter LLM, the system exhibits 8% higher interruption precision than the best commercial LLM for voice-based dialogue
Plain English Explanation
This research paper describes a new kind of dialogue system that can have natural back-and-forth conversations with users. Unlike traditional systems that can only respond after the user has finished speaking, this system can listen and speak at the same time, just like in a real conversation.
The key innovation is the use of a large language model (LLM) that has been carefully designed to work with three different modules: a perception module to understand the user, a motor function module to generate responses, and a simple state machine to coordinate when the system should speak, listen, or interrupt the user.
This allows the LLM to continuously generate text and make decisions about when to respond, wait, or interrupt the user in real-time. In tests, this "full-duplex" dialogue system was able to reduce the time it takes to respond by more than three times compared to traditional half-duplex systems. It could also respond within 500 milliseconds (half a second) in over 50% of conversations.
Even running on a relatively small 8 billion parameter LLM, the system was able to outperform the best commercial voice-based dialogue systems in terms of accurately interrupting the user when appropriate.
Technical Explanation
The core of this dialogue system is a large language model (LLM) that has been carefully aligned to work with three key modules: a perception module to understand the user's input, a motor function module to generate textual responses, and a simple finite state machine (called a "neural FSM") with two states.
This allows the LLM to operate in a full-duplex manner, meaning it can listen and speak simultaneously, just like in a real human conversation. The perception and motor modules work in parallel, enabling the system to react and respond in real-time.
The LLM's role is to predict the next textual token for the response, as well as to make autonomous decisions about when to start responding, when to wait for the user, or when to interrupt the user. It does this by emitting control tokens to the neural FSM, which coordinates the overall flow of the dialogue.
In experiments simulating real-world interactions, this full-duplex dialogue system was able to reduce the average response latency by over 3 times compared to traditional half-duplex LLM-based systems. It could respond within 500 milliseconds (half a second) in more than 50% of the evaluated interactions.
Notably, the researchers were able to achieve these results using a relatively small 8 billion parameter LLM. Their system demonstrated an 8% higher interruption precision rate than the best available commercial LLM for voice-based dialogue.
Critical Analysis
The researchers provide a thorough evaluation of their full-duplex dialogue system, including comparisons to half-duplex baselines and commercial voice-based systems. This gives us confidence in the claimed performance improvements.
However, the paper does not delve deeply into the potential limitations or failure modes of their approach. For example, it's unclear how the system would handle more complex or open-ended conversations, or how it might perform in real-world deployments with noisy input or unpredictable user behavior.
Additionally, the researchers acknowledge that the neural FSM used in their system is a relatively simple finite state machine. It would be interesting to see how more advanced dialogue management techniques, such as large language user interfaces or general-purpose speech abilities, could be incorporated to handle more nuanced dialogue flows.
Overall, this paper presents a compelling approach to building more natural and responsive dialogue systems. However, further research and real-world testing would be needed to fully assess the system's capabilities and limitations.
Conclusion
This research paper introduces a generative dialogue system that can operate in a full-duplex manner, allowing for seamless back-and-forth interaction with users. By carefully aligning a large language model (LLM) with perception, motor function, and a simple finite state machine, the system can simultaneously listen and speak, reducing average response latency by more than 3 times compared to traditional half-duplex dialogue systems.
The system's ability to respond within 500 milliseconds in over 50% of interactions, and its 8% higher interruption precision compared to the best commercial voice-based dialogue systems, demonstrate the potential of this approach. While the paper does not delve deeply into the system's limitations, it provides a promising step towards more natural and responsive dialogue interfaces.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Beyond the Turn-Based Game: Enabling Real-Time Conversations with Duplex Models
Xinrong Zhang, Yingfa Chen, Shengding Hu, Xu Han, Zihang Xu, Yuanwei Xu, Weilin Zhao, Maosong Sun, Zhiyuan Liu
0
0
As large language models (LLMs) increasingly permeate daily lives, there is a growing demand for real-time interactions that mirror human conversations. Traditional turn-based chat systems driven by LLMs prevent users from verbally interacting with the system while it is generating responses. To overcome these limitations, we adapt existing LLMs to textit{duplex models} so that these LLMs can listen for users while generating output and dynamically adjust themselves to provide users with instant feedback. % such as in response to interruptions. Specifically, we divide the queries and responses of conversations into several time slices and then adopt a time-division-multiplexing (TDM) encoding-decoding strategy to pseudo-simultaneously process these slices. Furthermore, to make LLMs proficient enough to handle real-time conversations, we build a fine-tuning dataset consisting of alternating time slices of queries and responses as well as covering typical feedback types in instantaneous interactions. Our experiments show that although the queries and responses of conversations are segmented into incomplete slices for processing, LLMs can preserve their original performance on standard benchmarks with a few fine-tuning steps on our dataset. Automatic and human evaluation indicate that duplex models make user-AI interactions more natural and human-like, and greatly improve user satisfaction compared to vanilla LLMs. Our duplex model and dataset will be released.
6/26/2024
💬
DuetSim: Building User Simulator with Dual Large Language Models for Task-Oriented Dialogues
Xiang Luo, Zhiwen Tang, Jin Wang, Xuejie Zhang
0
0
User Simulators play a pivotal role in training and evaluating task-oriented dialogue systems. Traditional user simulators typically rely on human-engineered agendas, resulting in generated responses that often lack diversity and spontaneity. Although large language models (LLMs) exhibit a remarkable capacity for generating coherent and contextually appropriate utterances, they may fall short when tasked with generating responses that effectively guide users towards their goals, particularly in dialogues with intricate constraints and requirements. This paper introduces DuetSim, a novel framework designed to address the intricate demands of task-oriented dialogues by leveraging LLMs. DuetSim stands apart from conventional approaches by employing two LLMs in tandem: one dedicated to response generation and the other focused on verification. This dual LLM approach empowers DuetSim to produce responses that not only exhibit diversity but also demonstrate accuracy and are preferred by human users. We validate the efficacy of our method through extensive experiments conducted on the MultiWOZ dataset, highlighting improvements in response quality and correctness, largely attributed to the incorporation of the second LLM. Our code is accessible at: https://github.com/suntea233/DuetSim.
5/24/2024
Large Language Model based Situational Dialogues for Second Language Learning
Shuyao Xu, Long Qin, Tianyang Chen, Zhenzhou Zha, Bingxue Qiu, Weizhi Wang
0
0
In second language learning, scenario-based conversation practice is important for language learners to achieve fluency in speaking, but students often lack sufficient opportunities to practice their conversational skills with qualified instructors or native speakers. To bridge this gap, we propose situational dialogue models for students to engage in conversational practice. Our situational dialogue models are fine-tuned on large language models (LLMs), with the aim of combining the engaging nature of an open-ended conversation with the focused practice of scenario-based tasks. Leveraging the generalization capabilities of LLMs, we demonstrate that our situational dialogue models perform effectively not only on training topics but also on topics not encountered during training. This offers a promising solution to support a wide range of conversational topics without extensive manual work. Additionally, research in the field of dialogue systems still lacks reliable automatic evaluation metrics, leading to human evaluation as the gold standard (Smith et al., 2022), which is typically expensive. To address the limitations of existing evaluation methods, we present a novel automatic evaluation method that employs fine-tuned LLMs to efficiently and effectively assess the performance of situational dialogue models.
4/1/2024

PSLM: Parallel Generation of Text and Speech with LLMs for Low-Latency Spoken Dialogue Systems
Kentaro Mitsui, Koh Mitsuda, Toshiaki Wakatsuki, Yukiya Hono, Kei Sawada
0
0
Multimodal language models that process both text and speech have a potential for applications in spoken dialogue systems. However, current models face two major challenges in response generation latency: (1) generating a spoken response requires the prior generation of a written response, and (2) speech sequences are significantly longer than text sequences. This study addresses these issues by extending the input and output sequences of the language model to support the parallel generation of text and speech. Our experiments on spoken question answering tasks demonstrate that our approach improves latency while maintaining the quality of response content. Additionally, we show that latency can be further reduced by generating speech in multiple sequences. Demo samples are available at https://rinnakk.github.io/research/publications/PSLM.
6/19/2024