LLark: A Multimodal Instruction-Following Language Model for Music
2310.07160
2
0
💬
Abstract
Music has a unique and complex structure which is challenging for both expert humans and existing AI systems to understand, and presents unique challenges relative to other forms of audio. We present LLark, an instruction-tuned multimodal model for emph{music} understanding. We detail our process for dataset creation, which involves augmenting the annotations of diverse open-source music datasets and converting them to a unified instruction-tuning format. We propose a multimodal architecture for LLark, integrating a pretrained generative model for music with a pretrained language model. In evaluations on three types of tasks (music understanding, captioning, reasoning), we show that LLark matches or outperforms existing baselines in music understanding, and that humans show a high degree of agreement with its responses in captioning and reasoning tasks. LLark is trained entirely from open-source music data and models, and we make our training code available along with the release of this paper. Additional results and audio examples are at https://bit.ly/llark, and our source code is available at https://github.com/spotify-research/llark .
Create account to get full access
Overview
- This paper introduces LLark, a multimodal foundation model for music that can generate, understand, and manipulate musical content.
- LLark is trained on a large dataset of music, text, and other modalities, allowing it to learn rich representations and perform a variety of music-related tasks.
- The authors demonstrate LLark's capabilities in areas like music generation, music audio retrieval, and conditional music generation.
Plain English Explanation
LLark is a powerful AI system that has been trained on a huge amount of musical data, including audio, sheet music, and text descriptions. This allows it to understand music in a deep and nuanced way, much like how large language models can understand and generate human language.
With this broad and deep musical knowledge, LLark can perform all sorts of music-related tasks. It can generate new music from scratch, find similar sounding songs, and even create new music based on text descriptions or other inputs.
Think of LLark as a sort of "musical Swiss Army knife" - it's a flexible tool that can assist with all kinds of music-related activities, from composing to analysis to retrieval. By tapping into the power of large-scale, multimodal machine learning, the researchers have created a foundation model that could have wide-ranging applications in the music industry and beyond.
Technical Explanation
The core of LLark is a large, multimodal neural network that has been trained on a vast corpus of musical data, including audio recordings, sheet music, lyrics, and textual descriptions. This allows the model to learn rich, cross-modal representations of musical content that can be leveraged for a variety of tasks.
The authors demonstrate LLark's capabilities across several experiments. In music generation, the model can generate novel musical compositions given text prompts or other conditioning information. For music audio retrieval, LLark can match textual queries to relevant audio clips from its training data. And in conditional music generation, the model can produce new music that matches high-level attributes specified in text.
The architecture of LLark builds on recent advances in large language models and multimodal vision-language models, incorporating transformers and other modern deep learning components. The training process involves a mix of self-supervised, contrastive, and generative objectives to instill the model with rich musical knowledge and capabilities.
Critical Analysis
While the results presented in the paper are impressive, there are a few important caveats to consider. First, the training dataset, though large, may not be fully representative of all musical styles and genres. This could limit the model's ability to generalize to more niche or experimental music.
Additionally, the paper does not delve deeply into potential biases or ethical considerations around a model like LLark. As a powerful generative system, there are valid concerns about the model being used to create inauthentic or misleading musical content. The authors would do well to address these issues more thoroughly in future work.
[That said, the core ideas behind LLark represent an exciting step forward in the field of content-based controls for music generation using large language modeling. By marrying musical and linguistic understanding, the researchers have created a flexible and versatile tool that could unlock new frontiers in computational creativity and music-AI interaction.
Conclusion
LLark is a groundbreaking multimodal foundation model that demonstrates the power of large-scale, cross-modal machine learning for music. By training on a vast corpus of musical data, the model has developed rich representations that enable it to generate, understand, and manipulate musical content in novel ways.
While the research is not without its limitations, the core ideas behind LLark represent a significant advance in the field of music-AI. As the model's capabilities are further refined and developed, it could have profound implications for areas like music composition, analysis, education, and beyond. The potential for LLark to augment and empower human musical creativity is truly exciting.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
MusiLingo: Bridging Music and Text with Pre-trained Language Models for Music Captioning and Query Response
Zihao Deng, Yinghao Ma, Yudong Liu, Rongchen Guo, Ge Zhang, Wenhu Chen, Wenhao Huang, Emmanouil Benetos
0
0
Large Language Models (LLMs) have shown immense potential in multimodal applications, yet the convergence of textual and musical domains remains not well-explored. To address this gap, we present MusiLingo, a novel system for music caption generation and music-related query responses. MusiLingo employs a single projection layer to align music representations from the pre-trained frozen music audio model MERT with a frozen LLM, bridging the gap between music audio and textual contexts. We train it on an extensive music caption dataset and fine-tune it with instructional data. Due to the scarcity of high-quality music Q&A datasets, we created the MusicInstruct (MI) dataset from captions in the MusicCaps datasets, tailored for open-ended music inquiries. Empirical evaluations demonstrate its competitive performance in generating music captions and composing music-related Q&A pairs. Our introduced dataset enables notable advancements beyond previous ones.
4/3/2024

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
🤔
MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training
Yizhi Li, Ruibin Yuan, Ge Zhang, Yinghao Ma, Xingran Chen, Hanzhi Yin, Chenghao Xiao, Chenghua Lin, Anton Ragni, Emmanouil Benetos, Norbert Gyenge, Roger Dannenberg, Ruibo Liu, Wenhu Chen, Gus Xia, Yemin Shi, Wenhao Huang, Zili Wang, Yike Guo, Jie Fu
0
0
Self-supervised learning (SSL) has recently emerged as a promising paradigm for training generalisable models on large-scale data in the fields of vision, text, and speech. Although SSL has been proven effective in speech and audio, its application to music audio has yet to be thoroughly explored. This is partially due to the distinctive challenges associated with modelling musical knowledge, particularly tonal and pitched characteristics of music. To address this research gap, we propose an acoustic Music undERstanding model with large-scale self-supervised Training (MERT), which incorporates teacher models to provide pseudo labels in the masked language modelling (MLM) style acoustic pre-training. In our exploration, we identified an effective combination of teacher models, which outperforms conventional speech and audio approaches in terms of performance. This combination includes an acoustic teacher based on Residual Vector Quantisation - Variational AutoEncoder (RVQ-VAE) and a musical teacher based on the Constant-Q Transform (CQT). Furthermore, we explore a wide range of settings to overcome the instability in acoustic language model pre-training, which allows our designed paradigm to scale from 95M to 330M parameters. Experimental results indicate that our model can generalise and perform well on 14 music understanding tasks and attain state-of-the-art (SOTA) overall scores.
4/24/2024
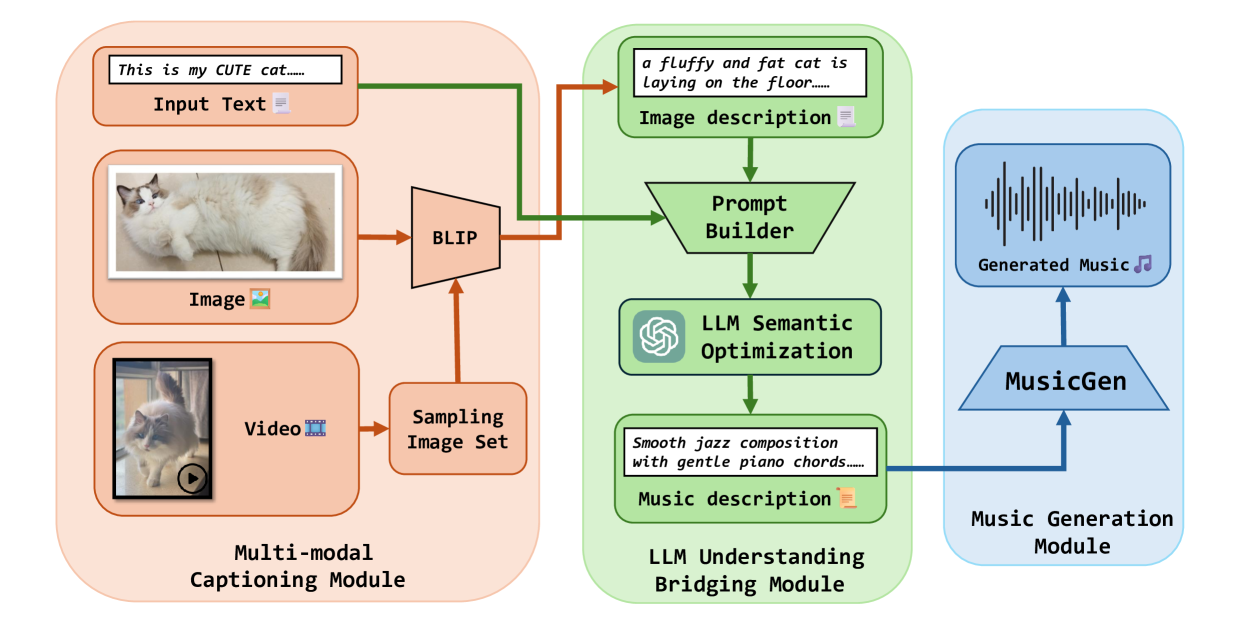
Mozart's Touch: A Lightweight Multi-modal Music Generation Framework Based on Pre-Trained Large Models
Tianze Xu, Jiajun Li, Xuesong Chen, Xinrui Yao, Shuchang Liu
0
0
In recent years, AI-Generated Content (AIGC) has witnessed rapid advancements, facilitating the generation of music, images, and other forms of artistic expression across various industries. However, researches on general multi-modal music generation model remain scarce. To fill this gap, we propose a multi-modal music generation framework Mozart's Touch. It could generate aligned music with the cross-modality inputs, such as images, videos and text. Mozart's Touch is composed of three main components: Multi-modal Captioning Module, Large Language Model (LLM) Understanding & Bridging Module, and Music Generation Module. Unlike traditional approaches, Mozart's Touch requires no training or fine-tuning pre-trained models, offering efficiency and transparency through clear, interpretable prompts. We also introduce LLM-Bridge method to resolve the heterogeneous representation problems between descriptive texts of different modalities. We conduct a series of objective and subjective evaluations on the proposed model, and results indicate that our model surpasses the performance of current state-of-the-art models. Our codes and examples is availble at: https://github.com/WangTooNaive/MozartsTouch
5/8/2024