MusiLingo: Bridging Music and Text with Pre-trained Language Models for Music Captioning and Query Response
2309.08730
0
0
💬
Abstract
Large Language Models (LLMs) have shown immense potential in multimodal applications, yet the convergence of textual and musical domains remains not well-explored. To address this gap, we present MusiLingo, a novel system for music caption generation and music-related query responses. MusiLingo employs a single projection layer to align music representations from the pre-trained frozen music audio model MERT with a frozen LLM, bridging the gap between music audio and textual contexts. We train it on an extensive music caption dataset and fine-tune it with instructional data. Due to the scarcity of high-quality music Q&A datasets, we created the MusicInstruct (MI) dataset from captions in the MusicCaps datasets, tailored for open-ended music inquiries. Empirical evaluations demonstrate its competitive performance in generating music captions and composing music-related Q&A pairs. Our introduced dataset enables notable advancements beyond previous ones.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper presents a novel system called MusiLingo that can generate music captions and respond to music-related queries.
- MusiLingo aligns music representations from a pre-trained audio model with a large language model (LLM) to bridge the gap between music and text.
- The system is trained on a music caption dataset and fine-tuned with instructional data.
- The authors also created a new dataset called MusicInstruct (MI) from existing music caption datasets to enable open-ended music-related Q&A.
- Evaluations show MusiLingo performs well on music caption generation and music-related Q&A tasks.
Plain English Explanation
The paper introduces a new system called MusiLingo that can work with both music and text. MusiLingo is designed to bridge the gap between music audio and written language, allowing it to generate captions that describe music and answer questions about music.
To do this, MusiLingo takes a pre-trained model that can understand music audio and aligns it with a large language model (LLM) that can understand and generate text. This alignment allows the system to translate between the musical and textual domains. MusiLingo is trained on a dataset of music captions, which are short descriptions of music, and then fine-tuned using additional instructional data.
Since there was a lack of high-quality datasets for asking open-ended questions about music, the researchers also created a new dataset called MusicInstruct (MI). This dataset was built from the captions in existing music datasets and designed to support a wider range of music-related questions.
Evaluations show that MusiLingo performs well at generating music captions and answering music-related questions. This suggests the system is effective at connecting music and language, which could be useful for applications that involve both modalities, such as music recommendation or music education.
Technical Explanation
The core of MusiLingo is a single projection layer that aligns music representations from a pre-trained frozen audio model called MERT with a frozen LLM. This allows the system to bridge the gap between the musical and textual domains. MusiLingo is trained on an extensive music caption dataset and then fine-tuned using instructional data.
Since high-quality music Q&A datasets were scarce, the authors created the MusicInstruct (MI) dataset. They derived this dataset from the captions in the MusicCaps datasets, transforming them into open-ended music-related questions and answers. This new dataset enables MusiLingo to engage in more diverse and natural music-related conversations.
Empirical evaluations demonstrate that MusiLingo performs competitively on both music caption generation and music-related question-answering tasks. This suggests the system is effective at connecting spoken language understanding with LLMs and cross-modal alignment.
Critical Analysis
The paper presents a promising approach to bridging the gap between music and language, but it also acknowledges some limitations. The authors note that the MusicInstruct (MI) dataset, while a valuable contribution, may still be constrained by the quality and diversity of the original music captions it was derived from.
Additionally, the paper does not provide a detailed analysis of the types of music-related questions the system can handle or the potential biases in the training data. Further research would be needed to understand the system's capabilities and limitations in real-world music-related conversations.
While the evaluation results are encouraging, it would be valuable to see how MusiLingo performs in comparison to other multi-modal models or multi-lingual LLMs that could potentially be applied to music-language tasks.
Overall, the MusiLingo system represents an interesting step towards better integrating music and language understanding, but more work is needed to fully realize the potential of this approach.
Conclusion
This paper presents MusiLingo, a novel system that can generate music captions and respond to music-related queries. MusiLingo achieves this by aligning music representations from a pre-trained audio model with a large language model, enabling it to bridge the gap between music and text.
The authors also created a new dataset called MusicInstruct (MI) to support more open-ended music-related questions and answers. Evaluations show that MusiLingo performs well on both music caption generation and music-related Q&A tasks, suggesting it is effective at connecting music and language understanding.
While the paper highlights promising results, it also acknowledges the need for further research to fully understand the system's capabilities and limitations. Exploring how MusiLingo compares to other multi-modal and multi-lingual models could yield valuable insights and drive the field of music-language integration forward.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
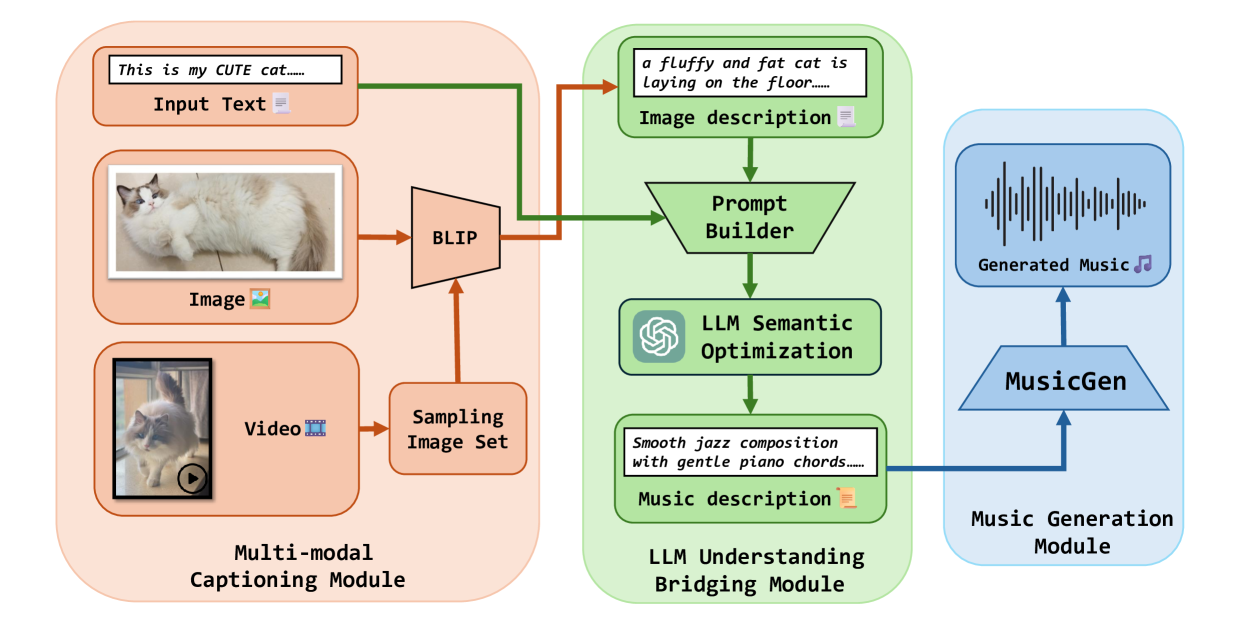
Mozart's Touch: A Lightweight Multi-modal Music Generation Framework Based on Pre-Trained Large Models
Tianze Xu, Jiajun Li, Xuesong Chen, Xinrui Yao, Shuchang Liu
0
0
In recent years, AI-Generated Content (AIGC) has witnessed rapid advancements, facilitating the generation of music, images, and other forms of artistic expression across various industries. However, researches on general multi-modal music generation model remain scarce. To fill this gap, we propose a multi-modal music generation framework Mozart's Touch. It could generate aligned music with the cross-modality inputs, such as images, videos and text. Mozart's Touch is composed of three main components: Multi-modal Captioning Module, Large Language Model (LLM) Understanding & Bridging Module, and Music Generation Module. Unlike traditional approaches, Mozart's Touch requires no training or fine-tuning pre-trained models, offering efficiency and transparency through clear, interpretable prompts. We also introduce LLM-Bridge method to resolve the heterogeneous representation problems between descriptive texts of different modalities. We conduct a series of objective and subjective evaluations on the proposed model, and results indicate that our model surpasses the performance of current state-of-the-art models. Our codes and examples is availble at: https://github.com/WangTooNaive/MozartsTouch
5/8/2024
💬
Content-based Controls For Music Large Language Modeling
Liwei Lin, Gus Xia, Junyan Jiang, Yixiao Zhang
0
0
Recent years have witnessed a rapid growth of large-scale language models in the domain of music audio. Such models enable end-to-end generation of higher-quality music, and some allow conditioned generation using text descriptions. However, the control power of text controls on music is intrinsically limited, as they can only describe music indirectly through meta-data (such as singers and instruments) or high-level representations (such as genre and emotion). We aim to further equip the models with direct and content-based controls on innate music languages such as pitch, chords and drum track. To this end, we contribute Coco-Mulla, a content-based control method for music large language modeling. It uses a parameter-efficient fine-tuning (PEFT) method tailored for Transformer-based audio models. Experiments show that our approach achieved high-quality music generation with low-resource semi-supervised learning, tuning with less than 4% parameters compared to the original model and training on a small dataset with fewer than 300 songs. Moreover, our approach enables effective content-based controls, and we illustrate the control power via chords and rhythms, two of the most salient features of music audio. Furthermore, we show that by combining content-based controls and text descriptions, our system achieves flexible music variation generation and arrangement. Our source codes and demos are available online.
4/16/2024

SambaLingo: Teaching Large Language Models New Languages
Zoltan Csaki, Bo Li, Jonathan Li, Qiantong Xu, Pian Pawakapan, Leon Zhang, Yun Du, Hengyu Zhao, Changran Hu, Urmish Thakker
0
0
Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
4/10/2024

Transforming LLMs into Cross-modal and Cross-lingual RetrievalSystems
Frank Palma Gomez, Ramon Sanabria, Yun-hsuan Sung, Daniel Cer, Siddharth Dalmia, Gustavo Hernandez Abrego
0
0
Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
4/5/2024