LLaVA-SG: Leveraging Scene Graphs as Visual Semantic Expression in Vision-Language Models

0

Sign in to get full access
Overview
- LLaVA-SG is a research paper that explores leveraging scene graphs as visual semantic expression in vision-language models.
- Scene graphs are a way to represent the relationships between objects, attributes, and actions in an image.
- The paper proposes incorporating scene graph information into large vision-language models to enhance their understanding and reasoning capabilities.
Plain English Explanation
Vision-language models are AI systems that can understand and generate language based on visual inputs, like images or videos. These models have become increasingly powerful, but they still struggle with some complex visual reasoning tasks.
The key idea behind LLaVA-SG is to provide these models with a richer, more structured representation of the visual world using scene graphs. Scene graphs describe the objects in an image, their attributes, and the relationships between them. For example, a scene graph for a living room image might show a "sofa" that is "supporting" a "person" who is "sitting on" the sofa.
By incorporating scene graph information into the vision-language model, the researchers hypothesized that the model would be better able to understand the semantics of the visual world and reason about complex visual relationships. This could lead to improved performance on tasks like image captioning, visual question answering, and even multi-agent planning.
Technical Explanation
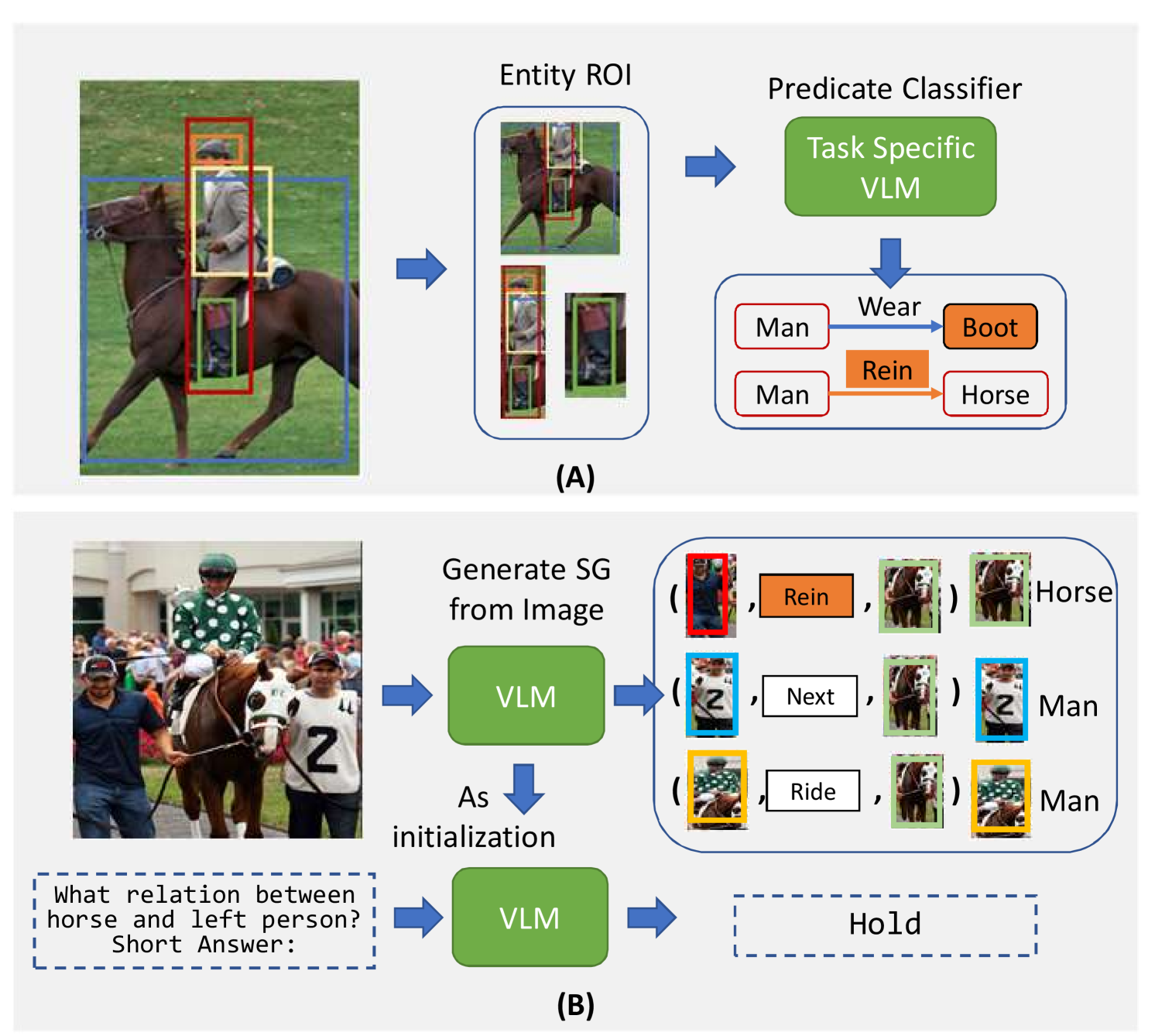
The LLaVA-SG model builds on top of a large, pre-trained vision-language model. It takes an image as input and generates a scene graph representation of the visual content. This scene graph is then used to augment the visual features that are fed into the vision-language model.
The key technical components of LLaVA-SG include:
- Scene graph generation: A model that can automatically extract a scene graph from an input image, identifying the objects, their attributes, and the relationships between them.
- Scene graph embedding: A way to represent the scene graph information in a format that can be used by the vision-language model.
- Fusion of visual and scene graph features: The model combines the visual features from the image with the scene graph features to create a richer representation of the visual content.
The researchers trained and evaluated LLaVA-SG on a variety of vision-language tasks, including image captioning, visual question answering, and multi-agent planning. Their results showed that incorporating scene graph information can lead to significant performance improvements compared to using visual features alone.
Critical Analysis
The LLaVA-SG paper makes a compelling case for the value of incorporating structured scene graph representations into vision-language models. The results suggest that this approach can indeed enhance the models' understanding and reasoning capabilities.
However, the paper does not address some potential limitations and areas for further research:
- The scene graph generation model used in LLaVA-SG may not be perfect, and errors in the scene graph could negatively impact the performance of the overall system.
- The paper focuses on a limited set of tasks, and it's unclear how well the approach would generalize to other vision-language applications.
- The computational and memory costs of incorporating scene graphs into the model are not discussed, which could be an important practical consideration.
Additionally, while the paper situates LLaVA-SG within the broader context of vision-language research, it would be valuable to see a more in-depth discussion of how this work relates to and builds upon previous efforts in this area.
Conclusion
The LLaVA-SG paper presents a promising approach for leveraging scene graph representations to enhance the capabilities of vision-language models. By providing these models with a richer, more structured understanding of the visual world, the researchers were able to achieve impressive performance gains on a variety of tasks.
This work represents an important step forward in the field of multimodal learning and reasoning, and it suggests that continued research into the integration of structured knowledge representations and large-scale language models could lead to further advancements in artificial intelligence. As the field progresses, it will be important to address the potential limitations and explore the broader applicability of approaches like LLaVA-SG.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLaVA-SG: Leveraging Scene Graphs as Visual Semantic Expression in Vision-Language Models
Jingyi Wang, Jianzhong Ju, Jian Luan, Zhidong Deng
Recent advances in large vision-language models (VLMs) typically employ vision encoders based on the Vision Transformer (ViT) architecture. The division of the images into patches by ViT results in a fragmented perception, thereby hindering the visual understanding capabilities of VLMs. In this paper, we propose an innovative enhancement to address this limitation by introducing a Scene Graph Expression (SGE) module in VLMs. This module extracts and structurally expresses the complex semantic information within images, thereby improving the foundational perception and understanding abilities of VLMs. Extensive experiments demonstrate that integrating our SGE module significantly enhances the VLM's performance in vision-language tasks, indicating its effectiveness in preserving intricate semantic details and facilitating better visual understanding.
Read more9/2/2024
0
From Pixels to Graphs: Open-Vocabulary Scene Graph Generation with Vision-Language Models
Rongjie Li, Songyang Zhang, Dahua Lin, Kai Chen, Xuming He
Scene graph generation (SGG) aims to parse a visual scene into an intermediate graph representation for downstream reasoning tasks. Despite recent advancements, existing methods struggle to generate scene graphs with novel visual relation concepts. To address this challenge, we introduce a new open-vocabulary SGG framework based on sequence generation. Our framework leverages vision-language pre-trained models (VLM) by incorporating an image-to-graph generation paradigm. Specifically, we generate scene graph sequences via image-to-text generation with VLM and then construct scene graphs from these sequences. By doing so, we harness the strong capabilities of VLM for open-vocabulary SGG and seamlessly integrate explicit relational modeling for enhancing the VL tasks. Experimental results demonstrate that our design not only achieves superior performance with an open vocabulary but also enhances downstream vision-language task performance through explicit relation modeling knowledge.
Read more4/9/2024

0
Multi-agent Planning using Visual Language Models
Michele Brienza, Francesco Argenziano, Vincenzo Suriani, Domenico D. Bloisi, Daniele Nardi
Large Language Models (LLMs) and Visual Language Models (VLMs) are attracting increasing interest due to their improving performance and applications across various domains and tasks. However, LLMs and VLMs can produce erroneous results, especially when a deep understanding of the problem domain is required. For instance, when planning and perception are needed simultaneously, these models often struggle because of difficulties in merging multi-modal information. To address this issue, fine-tuned models are typically employed and trained on specialized data structures representing the environment. This approach has limited effectiveness, as it can overly complicate the context for processing. In this paper, we propose a multi-agent architecture for embodied task planning that operates without the need for specific data structures as input. Instead, it uses a single image of the environment, handling free-form domains by leveraging commonsense knowledge. We also introduce a novel, fully automatic evaluation procedure, PG2S, designed to better assess the quality of a plan. We validated our approach using the widely recognized ALFRED dataset, comparing PG2S to the existing KAS metric to further evaluate the quality of the generated plans.
Read more8/13/2024

0
VLPrompt: Vision-Language Prompting for Panoptic Scene Graph Generation
Zijian Zhou, Miaojing Shi, Holger Caesar
Panoptic Scene Graph Generation (PSG) aims at achieving a comprehensive image understanding by simultaneously segmenting objects and predicting relations among objects. However, the long-tail problem among relations leads to unsatisfactory results in real-world applications. Prior methods predominantly rely on vision information or utilize limited language information, such as object or relation names, thereby overlooking the utility of language information. Leveraging the recent progress in Large Language Models (LLMs), we propose to use language information to assist relation prediction, particularly for rare relations. To this end, we propose the Vision-Language Prompting (VLPrompt) model, which acquires vision information from images and language information from LLMs. Then, through a prompter network based on attention mechanism, it achieves precise relation prediction. Our extensive experiments show that VLPrompt significantly outperforms previous state-of-the-art methods on the PSG dataset, proving the effectiveness of incorporating language information and alleviating the long-tail problem of relations. Code is available at url{https://github.com/franciszzj/TP-SIS}.
Read more6/21/2024