LLAVADI: What Matters For Multimodal Large Language Models Distillation

0

Sign in to get full access
Overview
- This paper explores strategies for distilling multimodal large language models (MM-LLMs) to create smaller, more efficient models.
- Key questions addressed include: what factors are important for effective distillation, and how can distillation be optimized to maintain model performance.
- The researchers propose a framework called LLAVADI that investigates different distillation approaches and their impact on downstream tasks.
Plain English Explanation
The paper focuses on distilling - a technique used to create smaller, more efficient versions of large, complex AI models. The authors specifically look at distilling multimodal large language models (MM-LLMs), which are powerful AI systems that can process and generate text, images, and other media.
The key questions the researchers explore are:
- What factors are most important when distilling MM-LLMs?
- How can the distillation process be optimized to maintain the performance of the original large model?
To investigate these questions, the researchers developed a framework called LLAVADI. This framework allows them to try out different distillation approaches and see how they impact the model's performance on various tasks.
The goal is to provide guidance on how to effectively distill MM-LLMs, creating smaller, faster models that can still perform well on a range of applications. This could be useful for deploying these powerful AI systems in resource-constrained environments, such as on mobile devices or in edge computing scenarios.
Technical Explanation
The paper introduces a framework called LLAVADI (Lessons Learned from Analyzing Multimodal Large Language Models Distillation) that systematically investigates factors impacting the distillation of multimodal large language models.
The key components of LLAVADI include:
- Distillation Strategies: The framework evaluates different distillation approaches, such as knowledge distillation and task-specific distillation.
- Distillation Targets: LLAVADI examines how distilling different model components (e.g. language modeling, vision, multimodal reasoning) impacts overall performance.
- Distillation Objectives: The framework investigates the use of various loss functions and training objectives to guide the distillation process.
- Distillation Datasets: LLAVADI leverages diverse datasets spanning text, images, and multimodal tasks to assess distilled model capabilities.
Through extensive experimentation, the researchers uncover several insights:
- The choice of distillation strategy has a significant impact on the performance of the distilled model.
- Distilling the multimodal reasoning capabilities of the original MM-LLM is crucial for maintaining high performance across a range of tasks.
- Carefully balancing the distillation objectives is important to avoid compromising specific model capabilities.
These findings provide a roadmap for effectively distilling MM-LLMs, enabling the creation of smaller, more efficient models that can still harness the power of these large-scale multimodal AI systems.
Critical Analysis
The paper provides a comprehensive framework for exploring MM-LLM distillation, addressing an important challenge in the field of AI model optimization and deployment.
One potential limitation is the scope of the experiments, which may not capture the full diversity of MM-LLM architectures and applications. The researchers primarily focus on a specific set of models and tasks, and it would be valuable to see how their insights generalize to a broader range of MM-LLMs and use cases.
Additionally, the paper does not delve deeply into the potential trade-offs and constraints involved in deploying distilled MM-LLMs in real-world scenarios. Further research could explore factors like inference latency, energy consumption, and hardware compatibility to provide a more holistic understanding of the practical implications of this technology.
Overall, the LLAVADI framework represents a valuable contribution to the field, offering a systematic approach to understanding and optimizing the distillation of multimodal large language models. As these models continue to advance, the insights from this work can help guide the development of efficient, high-performing AI systems that can be deployed in a wide range of applications.
Conclusion
This paper introduces LLAVADI, a framework for investigating the distillation of multimodal large language models (MM-LLMs). The researchers explore various factors that impact the effectiveness of distillation, such as the choice of distillation strategy, target model components, and training objectives.
Through extensive experimentation, the paper provides valuable insights into how to effectively distill MM-LLMs, enabling the creation of smaller, more efficient models that can still leverage the power of these large-scale multimodal AI systems. This work represents an important step in optimizing the deployment of advanced AI technologies, paving the way for their broader adoption across a range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLAVADI: What Matters For Multimodal Large Language Models Distillation
Shilin Xu, Xiangtai Li, Haobo Yuan, Lu Qi, Yunhai Tong, Ming-Hsuan Yang
The recent surge in Multimodal Large Language Models (MLLMs) has showcased their remarkable potential for achieving generalized intelligence by integrating visual understanding into Large Language Models.Nevertheless, the sheer model size of MLLMs leads to substantial memory and computational demands that hinder their widespread deployment. In this work, we do not propose a new efficient model structure or train small-scale MLLMs from scratch. Instead, we focus on what matters for training small-scale MLLMs through knowledge distillation, which is the first step from the multimodal distillation perspective. Our extensive studies involve training strategies, model choices, and distillation algorithms in the knowledge distillation process. These results show that joint alignment for both tokens and logit alignment plays critical roles in teacher-student frameworks. In addition, we draw a series of intriguing observations from this study. By evaluating different benchmarks and proper strategy, even a 2.7B small-scale model can perform on par with larger models with 7B or 13B parameters. Our code and models will be publicly available for further research.
Read more7/30/2024

0
The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
Read more6/7/2024
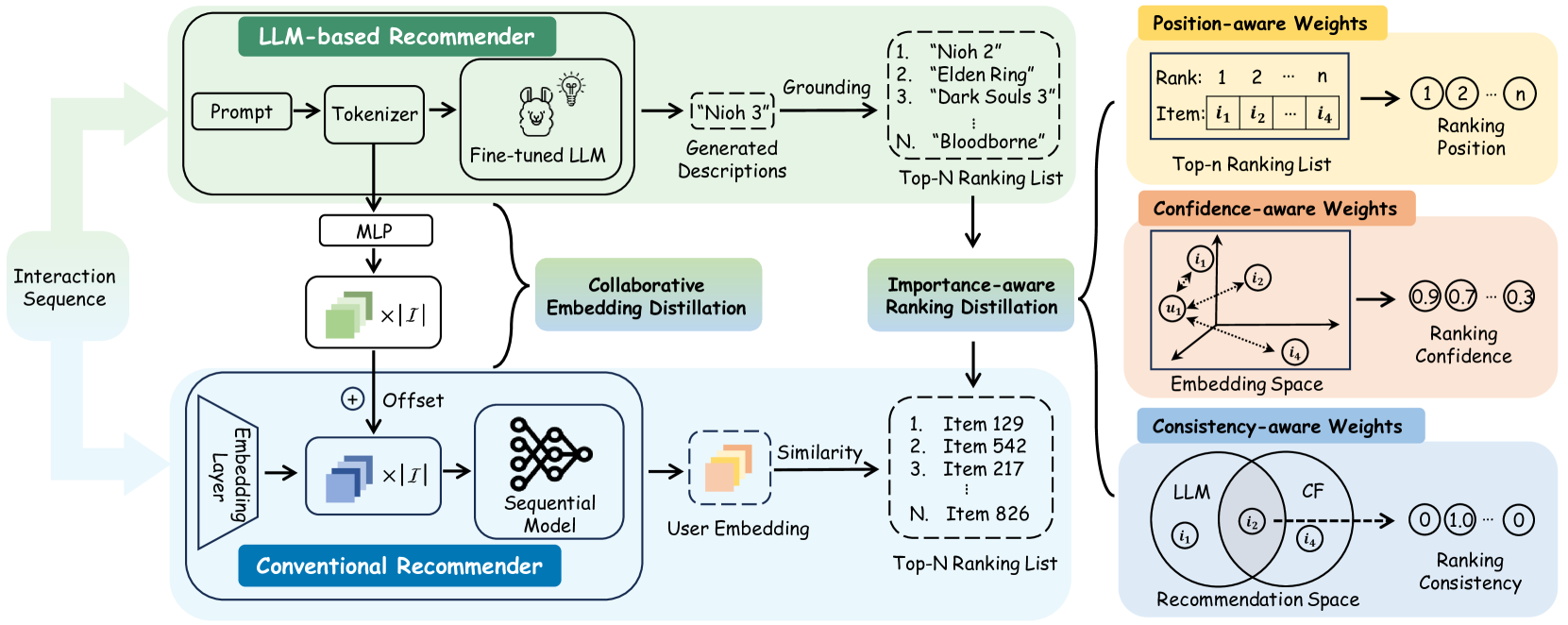
0
Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Model
Yu Cui, Feng Liu, Pengbo Wang, Bohao Wang, Heng Tang, Yi Wan, Jun Wang, Jiawei Chen
Owing to their powerful semantic reasoning capabilities, Large Language Models (LLMs) have been effectively utilized as recommenders, achieving impressive performance. However, the high inference latency of LLMs significantly restricts their practical deployment. To address this issue, this work investigates knowledge distillation from cumbersome LLM-based recommendation models to lightweight conventional sequential models. It encounters three challenges: 1) the teacher's knowledge may not always be reliable; 2) the capacity gap between the teacher and student makes it difficult for the student to assimilate the teacher's knowledge; 3) divergence in semantic space poses a challenge to distill the knowledge from embeddings. To tackle these challenges, this work proposes a novel distillation strategy, DLLM2Rec, specifically tailored for knowledge distillation from LLM-based recommendation models to conventional sequential models. DLLM2Rec comprises: 1) Importance-aware ranking distillation, which filters reliable and student-friendly knowledge by weighting instances according to teacher confidence and student-teacher consistency; 2) Collaborative embedding distillation integrates knowledge from teacher embeddings with collaborative signals mined from the data. Extensive experiments demonstrate the effectiveness of the proposed DLLM2Rec, boosting three typical sequential models with an average improvement of 47.97%, even enabling them to surpass LLM-based recommenders in some cases.
Read more8/21/2024

0
MiniLLM: Knowledge Distillation of Large Language Models
Yuxian Gu, Li Dong, Furu Wei, Minlie Huang
Knowledge Distillation (KD) is a promising technique for reducing the high computational demand of large language models (LLMs). However, previous KD methods are primarily applied to white-box classification models or training small models to imitate black-box model APIs like ChatGPT. How to effectively distill the knowledge of white-box LLMs into small models is still under-explored, which becomes more important with the prosperity of open-source LLMs. In this work, we propose a KD approach that distills LLMs into smaller language models. We first replace the forward Kullback-Leibler divergence (KLD) objective in the standard KD approaches with reverse KLD, which is more suitable for KD on generative language models, to prevent the student model from overestimating the low-probability regions of the teacher distribution. Then, we derive an effective optimization approach to learn this objective. The student models are named MiniLLM. Extensive experiments in the instruction-following setting show that MiniLLM generates more precise responses with higher overall quality, lower exposure bias, better calibration, and higher long-text generation performance than the baselines. Our method is scalable for different model families with 120M to 13B parameters. Our code, data, and model checkpoints can be found in https://github.com/microsoft/LMOps/tree/main/minillm.
Read more4/11/2024