LLaVolta: Efficient Multi-modal Models via Stage-wise Visual Context Compression
2406.20092
0
0
Abstract
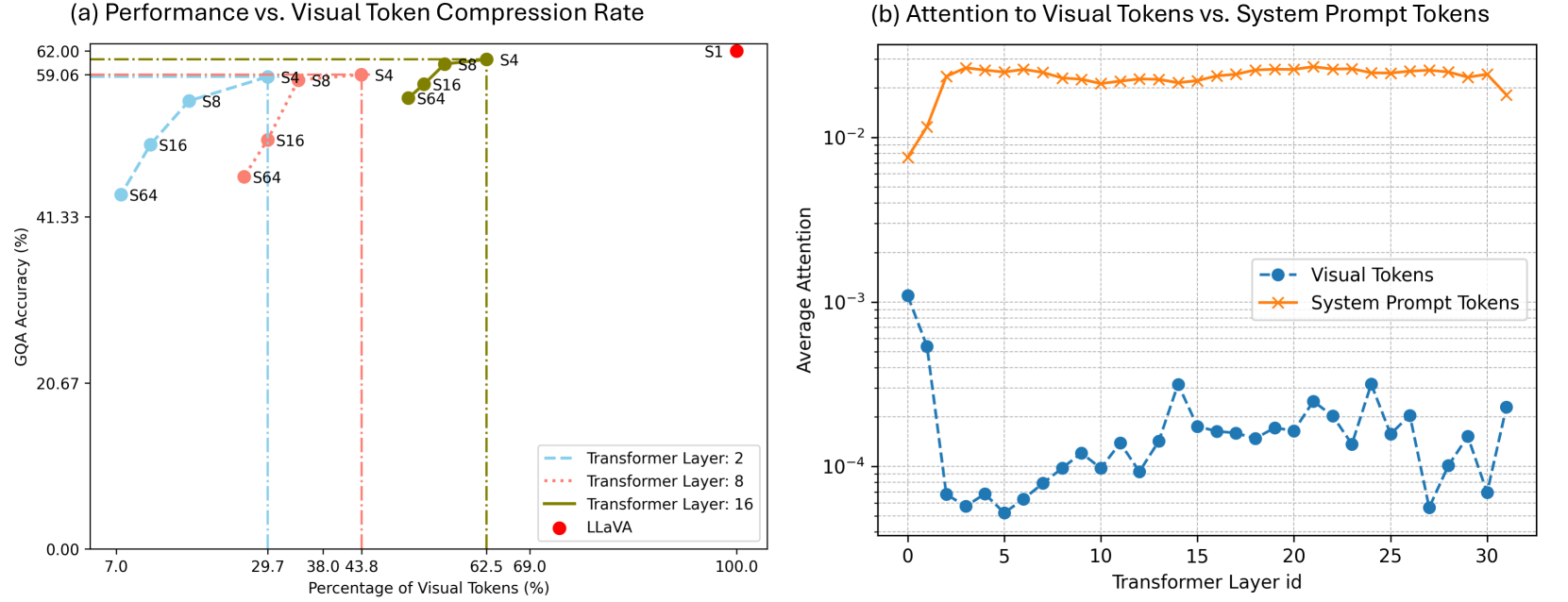
While significant advancements have been made in compressed representations for text embeddings in large language models (LLMs), the compression of visual tokens in large multi-modal models (LMMs) has remained a largely overlooked area. In this work, we present the study on the analysis of redundancy concerning visual tokens and efficient training within these models. Our initial experiments show that eliminating up to 70% of visual tokens at the testing stage by simply average pooling only leads to a minimal 3% reduction in visual question answering accuracy on the GQA benchmark, indicating significant redundancy in visual context. Addressing this, we introduce Visual Context Compressor, which reduces the number of visual tokens during training to enhance training efficiency without sacrificing performance. To minimize information loss caused by the compression on visual tokens while maintaining training efficiency, we develop LLaVolta as a lite training scheme. LLaVolta incorporates stage-wise visual context compression to progressively compress the visual tokens from heavily to lightly, and finally no compression at the end of training, yielding no loss of information when testing. Extensive experiments demonstrate that our approach enhances the performance of MLLMs in both image-language and video-language understanding, while also significantly cutting training costs. Code is available at https://github.com/Beckschen/LLaVolta
Create account to get full access
Overview
• This paper introduces LLaVolta, a new efficient multi-modal model that leverages stage-wise visual context compression to improve performance and efficiency.
• LLaVolta builds on previous work like VOCO-LLAMA, LLaVA-PruMerge, and ConvLLaVA, which have explored ways to make large language models more efficient.
• The key idea in LLaVolta is to compress the visual context in a stage-wise manner, gradually reducing the amount of visual information passed to the language model to improve speed and reduce resource requirements.
Plain English Explanation
The researchers behind this paper wanted to create a more efficient version of large multi-modal models that can handle both text and images. These types of models are powerful but can be computationally expensive and slow.
The core innovation in LLaVolta is a technique called "stage-wise visual context compression." This means they gradually reduce the amount of visual information (i.e., the number of pixels or visual features) passed from the image to the language model as the model progresses through its different stages.
By compressing the visual context in this way, LLaVolta is able to maintain good performance while using fewer computational resources. This makes the model faster and more efficient to run, which could be important for real-world applications with limited hardware or energy constraints.
The researchers show that LLaVolta outperforms previous efficient multi-modal models like VOCO-LLAMA, LLaVA-PruMerge, and ConvLLaVA on a range of benchmarks, demonstrating the benefits of their stage-wise compression approach.
Technical Explanation
The key technical innovation in LLaVolta is its stage-wise visual context compression mechanism. Instead of passing the full visual context (e.g., a high-resolution image) to the language model all at once, LLaVolta gradually reduces the amount of visual information in multiple stages.
This is achieved through a series of "visual projection heads" that progressively downsample and compress the visual features. In early stages, the model retains more detailed visual information. As the model progresses, the visual context is compressed further, passing fewer visual tokens to the language model.
This stage-wise compression allows LLaVolta to maintain good performance on multi-modal tasks while using fewer computational resources. The researchers show that LLaVolta outperforms previous efficient models like VOCO-LLAMA, LLaVA-PruMerge, and ConvLLaVA on a range of benchmarks, demonstrating the benefits of their approach.
Critical Analysis
The authors acknowledge some limitations of their work. For example, they note that the stage-wise compression may not be optimal for all types of multi-modal tasks, and that further research is needed to understand the trade-offs between compression and task performance.
Additionally, while the stage-wise compression improves efficiency, it may also lead to a loss of fine-grained visual information that could be important for certain applications. The authors suggest that exploring adaptive compression techniques or extending video understanding could be promising directions for future research.
Overall, the LLaVolta approach represents an interesting advance in efficient multi-modal modeling, but there is still room for further improvements and exploration of the trade-offs involved in visual context compression.
Conclusion
The LLaVolta model introduces a novel stage-wise visual context compression technique that enables efficient multi-modal performance. By gradually reducing the amount of visual information passed to the language model, LLaVolta is able to maintain good task performance while using fewer computational resources.
This work builds on previous research in efficient large language models and multi-modal architectures, and demonstrates the benefits of carefully managing the visual context to optimize for speed and efficiency. As large multi-modal models become increasingly important for a wide range of applications, techniques like those used in LLaVolta will be crucial for deploying these powerful systems in real-world scenarios with constrained resources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

VoCo-LLaMA: Towards Vision Compression with Large Language Models
Xubing Ye, Yukang Gan, Xiaoke Huang, Yixiao Ge, Ying Shan, Yansong Tang
0
0
Vision-Language Models (VLMs) have achieved remarkable success in various multi-modal tasks, but they are often bottlenecked by the limited context window and high computational cost of processing high-resolution image inputs and videos. Vision compression can alleviate this problem by reducing the vision token count. Previous approaches compress vision tokens with external modules and force LLMs to understand the compressed ones, leading to visual information loss. However, the LLMs' understanding paradigm of vision tokens is not fully utilised in the compression learning process. We propose VoCo-LLaMA, the first approach to compress vision tokens using LLMs. By introducing Vision Compression tokens during the vision instruction tuning phase and leveraging attention distillation, our method distill how LLMs comprehend vision tokens into their processing of VoCo tokens. VoCo-LLaMA facilitates effective vision compression and improves the computational efficiency during the inference stage. Specifically, our method achieves minimal performance loss with a compression ratio of 576$times$, resulting in up to 94.8$%$ fewer FLOPs and 69.6$%$ acceleration in inference time. Furthermore, through continuous training using time-series compressed token sequences of video frames, VoCo-LLaMA demonstrates the ability to understand temporal correlations, outperforming previous methods on popular video question-answering benchmarks. Our approach presents a promising way to unlock the full potential of VLMs' contextual window, enabling more scalable multi-modal applications. The project page, along with the associated code, can be accessed via $href{https://yxxxb.github.io/VoCo-LLaMA-page/}{text{this https URL}}$.
6/19/2024

LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, Yan Yan
0
0
Large Multimodal Models (LMMs) have shown significant visual reasoning capabilities by connecting a visual encoder and a large language model. LMMs typically take in a fixed and large amount of visual tokens, such as the penultimate layer features in the CLIP visual encoder, as the prefix content. Recent LMMs incorporate more complex visual inputs, such as high-resolution images and videos, which further increases the number of visual tokens significantly. However, due to the inherent design of the Transformer architecture, the computational costs of these models tend to increase quadratically with the number of input tokens. To tackle this problem, we explore a token reduction mechanism that identifies significant spatial redundancy among visual tokens. In response, we propose PruMerge, a novel adaptive visual token reduction strategy that significantly reduces the number of visual tokens without compromising the performance of LMMs. Specifically, to metric the importance of each token, we exploit the sparsity observed in the visual encoder, characterized by the sparse distribution of attention scores between the class token and visual tokens. This sparsity enables us to dynamically select the most crucial visual tokens to retain. Subsequently, we cluster the selected (unpruned) tokens based on their key similarity and merge them with the unpruned tokens, effectively supplementing and enhancing their informational content. Empirically, when applied to LLaVA-1.5, our approach can compress the visual tokens by 14 times on average, and achieve comparable performance across diverse visual question-answering and reasoning tasks. Code and checkpoints are at https://llava-prumerge.github.io/.
5/24/2024
ConvLLaVA: Hierarchical Backbones as Visual Encoder for Large Multimodal Models
Chunjiang Ge, Sijie Cheng, Ziming Wang, Jiale Yuan, Yuan Gao, Jun Song, Shiji Song, Gao Huang, Bo Zheng
0
0
High-resolution Large Multimodal Models (LMMs) encounter the challenges of excessive visual tokens and quadratic visual complexity. Current high-resolution LMMs address the quadratic complexity while still generating excessive visual tokens. However, the redundancy in visual tokens is the key problem as it leads to more substantial compute. To mitigate this issue, we propose ConvLLaVA, which employs ConvNeXt, a hierarchical backbone, as the visual encoder of LMM to replace Vision Transformer (ViT). ConvLLaVA compresses high-resolution images into information-rich visual features, effectively preventing the generation of excessive visual tokens. To enhance the capabilities of ConvLLaVA, we propose two critical optimizations. Since the low-resolution pretrained ConvNeXt underperforms when directly applied on high resolution, we update it to bridge the gap. Moreover, since ConvNeXt's original compression ratio is inadequate for much higher resolution inputs, we train a successive stage to further compress the visual tokens, thereby reducing redundancy. These optimizations enable ConvLLaVA to support inputs of 1536x1536 resolution generating only 576 visual tokens, capable of handling images of arbitrary aspect ratios. Experimental results demonstrate that our method achieves competitive performance with state-of-the-art models on mainstream benchmarks. The ConvLLaVA model series are publicly available at https://github.com/alibaba/conv-llava.
5/27/2024

Beyond LLaVA-HD: Diving into High-Resolution Large Multimodal Models
Yi-Fan Zhang, Qingsong Wen, Chaoyou Fu, Xue Wang, Zhang Zhang, Liang Wang, Rong Jin
0
0
Seeing clearly with high resolution is a foundation of Large Multimodal Models (LMMs), which has been proven to be vital for visual perception and reasoning. Existing works usually employ a straightforward resolution upscaling method, where the image consists of global and local branches, with the latter being the sliced image patches but resized to the same resolution as the former. This means that higher resolution requires more local patches, resulting in exorbitant computational expenses, and meanwhile, the dominance of local image tokens may diminish the global context. In this paper, we dive into the problems and propose a new framework as well as an elaborate optimization strategy. Specifically, we extract contextual information from the global view using a mixture of adapters, based on the observation that different adapters excel at different tasks. With regard to local patches, learnable query embeddings are introduced to reduce image tokens, the most important tokens accounting for the user question will be further selected by a similarity-based selector. Our empirical results demonstrate a `less is more' pattern, where textit{utilizing fewer but more informative local image tokens leads to improved performance}. Besides, a significant challenge lies in the training strategy, as simultaneous end-to-end training of the global mining block and local compression block does not yield optimal results. We thus advocate for an alternating training way, ensuring balanced learning between global and local aspects. Finally, we also introduce a challenging dataset with high requirements for image detail, enhancing the training of the local compression layer. The proposed method, termed LMM with Sophisticated Tasks, Local image compression, and Mixture of global Experts (SliME), achieves leading performance across various benchmarks with only 2 million training data.
6/17/2024