LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models
2403.15388
0
0

Abstract
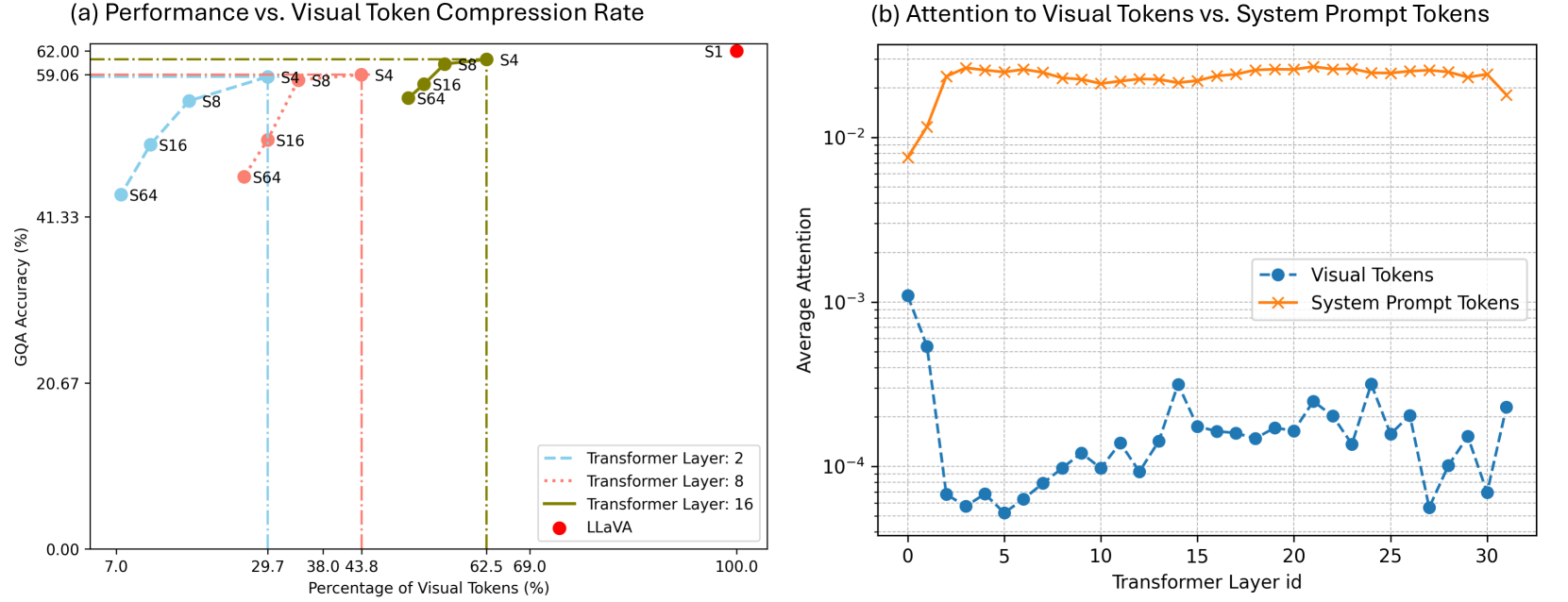
Large Multimodal Models (LMMs) have shown significant visual reasoning capabilities by connecting a visual encoder and a large language model. LMMs typically take in a fixed and large amount of visual tokens, such as the penultimate layer features in the CLIP visual encoder, as the prefix content. Recent LMMs incorporate more complex visual inputs, such as high-resolution images and videos, which further increases the number of visual tokens significantly. However, due to the inherent design of the Transformer architecture, the computational costs of these models tend to increase quadratically with the number of input tokens. To tackle this problem, we explore a token reduction mechanism that identifies significant spatial redundancy among visual tokens. In response, we propose PruMerge, a novel adaptive visual token reduction strategy that significantly reduces the number of visual tokens without compromising the performance of LMMs. Specifically, to metric the importance of each token, we exploit the sparsity observed in the visual encoder, characterized by the sparse distribution of attention scores between the class token and visual tokens. This sparsity enables us to dynamically select the most crucial visual tokens to retain. Subsequently, we cluster the selected (unpruned) tokens based on their key similarity and merge them with the unpruned tokens, effectively supplementing and enhancing their informational content. Empirically, when applied to LLaVA-1.5, our approach can compress the visual tokens by 14 times on average, and achieve comparable performance across diverse visual question-answering and reasoning tasks. Code and checkpoints are at https://llava-prumerge.github.io/.
Create account to get full access
Overview
• The paper introduces LLaVA-PruMerge, a method for efficiently training and deploying large multimodal models (LMMs) by adaptively reducing the number of tokens processed.
• LMMs are powerful AI models that can understand and generate content across multiple modalities like text, images, and audio. However, these models can be computationally expensive and difficult to deploy.
• LLaVA-PruMerge aims to address this challenge by selectively pruning redundant tokens during training and inference, allowing LMMs to run more efficiently without sacrificing performance.
Plain English Explanation
• Large multimodal models (LMMs) are advanced AI systems that can understand and create content across different formats like text, images, and audio. These models have become very powerful, but they also require a lot of computing power to run.
• The researchers behind this paper developed a new technique called LLaVA-PruMerge that helps make LMMs more efficient. It works by automatically identifying and removing parts of the input that aren't essential, which allows the model to run faster without losing too much accuracy.
• This is helpful because it means LMMs can be deployed more easily on a wider range of devices, from powerful servers to regular computers and even mobile phones. It also makes training these large models more feasible, as the computational requirements are reduced.
Technical Explanation
• The paper introduces a novel method called LLaVA-PruMerge that adaptively reduces the number of tokens processed by large multimodal models (LMMs) during both training and inference.
• LMMs like LLaVA-GEMMA and Multiflow combine large language models with computer vision capabilities to understand and generate content across multiple modalities. However, these models can be computationally expensive due to the high number of input tokens they process.
• LLaVA-PruMerge addresses this issue by selectively pruning redundant tokens based on their importance to the model's task. It does this through a series of pruning and merging steps that adaptively adjust the token count during training and inference.
• The paper demonstrates the effectiveness of LLaVA-PruMerge on several LMM architectures and datasets, showing significant improvements in computational efficiency without large drops in performance.
Critical Analysis
• The paper provides a thorough evaluation of LLaVA-PruMerge, including comparisons to related token reduction techniques like Sheared LLaMA and Enhancing Inference Efficiency.
• However, the paper does not address potential issues around the stability and reliability of the pruning and merging process, which could be important for real-world deployments of LMMs.
• Additionally, the paper focuses on improving computational efficiency, but does not explore the impact of LLaVA-PruMerge on other important factors like model robustness, fairness, or safety - areas that may require further investigation.
Conclusion
• LLaVA-PruMerge is a promising approach for making large multimodal models more efficient and accessible, as demonstrated by the significant computational gains without large drops in performance.
• By adaptively reducing the number of tokens processed, LLaVA-PruMerge could help enable the widespread deployment of powerful LMMs on a wider range of devices, opening up new opportunities for real-world applications of multimodal AI as seen in projects like "Large Language Models are Good Prompt Learners".
• Further research is needed to address potential concerns around the stability and holistic impact of the token reduction technique, but the core ideas behind LLaVA-PruMerge represent an important step forward in making large multimodal models more efficient and accessible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
New!LLaVolta: Efficient Multi-modal Models via Stage-wise Visual Context Compression
Jieneng Chen, Luoxin Ye, Ju He, Zhao-Yang Wang, Daniel Khashabi, Alan Yuille
0
0
While significant advancements have been made in compressed representations for text embeddings in large language models (LLMs), the compression of visual tokens in large multi-modal models (LMMs) has remained a largely overlooked area. In this work, we present the study on the analysis of redundancy concerning visual tokens and efficient training within these models. Our initial experiments show that eliminating up to 70% of visual tokens at the testing stage by simply average pooling only leads to a minimal 3% reduction in visual question answering accuracy on the GQA benchmark, indicating significant redundancy in visual context. Addressing this, we introduce Visual Context Compressor, which reduces the number of visual tokens during training to enhance training efficiency without sacrificing performance. To minimize information loss caused by the compression on visual tokens while maintaining training efficiency, we develop LLaVolta as a lite training scheme. LLaVolta incorporates stage-wise visual context compression to progressively compress the visual tokens from heavily to lightly, and finally no compression at the end of training, yielding no loss of information when testing. Extensive experiments demonstrate that our approach enhances the performance of MLLMs in both image-language and video-language understanding, while also significantly cutting training costs. Code is available at https://github.com/Beckschen/LLaVolta
7/1/2024

Matryoshka Multimodal Models
Mu Cai, Jianwei Yang, Jianfeng Gao, Yong Jae Lee
0
0
Large Multimodal Models (LMMs) such as LLaVA have shown strong performance in visual-linguistic reasoning. These models first embed images into a fixed large number of visual tokens and then feed them into a Large Language Model (LLM). However, this design causes an excessive number of tokens for dense visual scenarios such as high-resolution images and videos, leading to great inefficiency. While token pruning/merging methods do exist, they produce a single length output for each image and do not afford flexibility in trading off information density v.s. efficiency. Inspired by the concept of Matryoshka Dolls, we propose M3: Matryoshka Multimodal Models, which learns to represent visual content as nested sets of visual tokens that capture information across multiple coarse-to-fine granularities. Our approach offers several unique benefits for LMMs: (1) One can explicitly control the visual granularity per test instance during inference, e.g. , adjusting the number of tokens used to represent an image based on the anticipated complexity or simplicity of the content; (2) M3 provides a framework for analyzing the granularity needed for existing datasets, where we find that COCO-style benchmarks only need around ~9 visual tokens to obtain accuracy similar to that of using all 576 tokens; (3) Our approach provides a foundation to explore the best trade-off between performance and visual token length at sample level, where our investigation reveals that a large gap exists between the oracle upper bound and current fixed-scale representations.
5/28/2024

VoCo-LLaMA: Towards Vision Compression with Large Language Models
Xubing Ye, Yukang Gan, Xiaoke Huang, Yixiao Ge, Ying Shan, Yansong Tang
0
0
Vision-Language Models (VLMs) have achieved remarkable success in various multi-modal tasks, but they are often bottlenecked by the limited context window and high computational cost of processing high-resolution image inputs and videos. Vision compression can alleviate this problem by reducing the vision token count. Previous approaches compress vision tokens with external modules and force LLMs to understand the compressed ones, leading to visual information loss. However, the LLMs' understanding paradigm of vision tokens is not fully utilised in the compression learning process. We propose VoCo-LLaMA, the first approach to compress vision tokens using LLMs. By introducing Vision Compression tokens during the vision instruction tuning phase and leveraging attention distillation, our method distill how LLMs comprehend vision tokens into their processing of VoCo tokens. VoCo-LLaMA facilitates effective vision compression and improves the computational efficiency during the inference stage. Specifically, our method achieves minimal performance loss with a compression ratio of 576$times$, resulting in up to 94.8$%$ fewer FLOPs and 69.6$%$ acceleration in inference time. Furthermore, through continuous training using time-series compressed token sequences of video frames, VoCo-LLaMA demonstrates the ability to understand temporal correlations, outperforming previous methods on popular video question-answering benchmarks. Our approach presents a promising way to unlock the full potential of VLMs' contextual window, enabling more scalable multi-modal applications. The project page, along with the associated code, can be accessed via $href{https://yxxxb.github.io/VoCo-LLaMA-page/}{text{this https URL}}$.
6/19/2024
📊
Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization
Yang Jin, Zhicheng Sun, Kun Xu, Kun Xu, Liwei Chen, Hao Jiang, Quzhe Huang, Chengru Song, Yuliang Liu, Di Zhang, Yang Song, Kun Gai, Yadong Mu
0
0
In light of recent advances in multimodal Large Language Models (LLMs), there is increasing attention to scaling them from image-text data to more informative real-world videos. Compared to static images, video poses unique challenges for effective large-scale pre-training due to the modeling of its spatiotemporal dynamics. In this paper, we address such limitations in video-language pre-training with an efficient video decomposition that represents each video as keyframes and temporal motions. These are then adapted to an LLM using well-designed tokenizers that discretize visual and temporal information as a few tokens, thus enabling unified generative pre-training of videos, images, and text. At inference, the generated tokens from the LLM are carefully recovered to the original continuous pixel space to create various video content. Our proposed framework is both capable of comprehending and generating image and video content, as demonstrated by its competitive performance across 13 multimodal benchmarks in image and video understanding and generation. Our code and models are available at https://video-lavit.github.io.
6/4/2024