LLM-Coordination: Evaluating and Analyzing Multi-agent Coordination Abilities in Large Language Models
2310.03903
0
0
Abstract
The emergent reasoning and Theory of Mind (ToM) abilities demonstrated by Large Language Models (LLMs) make them promising candidates for developing coordination agents. In this study, we introduce a new LLM-Coordination Benchmark aimed at a detailed analysis of LLMs within the context of Pure Coordination Games, where participating agents need to cooperate for the most gain. This benchmark evaluates LLMs through two distinct tasks: (1) emph{Agentic Coordination}, where LLMs act as proactive participants for cooperation in 4 pure coordination games; (2) emph{Coordination Question Answering (QA)}, where LLMs are prompted to answer 198 multiple-choice questions from the 4 games for evaluation of three key reasoning abilities: Environment Comprehension, ToM Reasoning, and Joint Planning. Furthermore, to enable LLMs for multi-agent coordination, we introduce a Cognitive Architecture for Coordination (CAC) framework that can easily integrate different LLMs as plug-and-play modules for pure coordination games. Our findings indicate that LLM agents equipped with GPT-4-turbo achieve comparable performance to state-of-the-art reinforcement learning methods in games that require commonsense actions based on the environment. Besides, zero-shot coordination experiments reveal that, unlike RL methods, LLM agents are robust to new unseen partners. However, results on Coordination QA show a large room for improvement in the Theory of Mind reasoning and joint planning abilities of LLMs. The analysis also sheds light on how the ability of LLMs to understand their environment and their partner's beliefs and intentions plays a part in their ability to plan for coordination. Our code is available at url{https://github.com/eric-ai-lab/llm_coordination}.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper evaluates the multi-agent coordination abilities of large language models (LLMs), which are AI systems trained on vast amounts of text data to perform a variety of natural language tasks.
- The researchers investigate how well LLMs can coordinate the actions of multiple software agents to accomplish shared goals, a critical capability for real-world applications like autonomous agent systems and robotic control.
- The paper presents experiments and analysis to better understand LLMs' multi-agent coordination abilities and identify areas for further research and development.
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that can understand and generate human-like text. They are trained on huge amounts of online data, allowing them to perform all sorts of language-related tasks.
This paper looks at whether LLMs can also coordinate the actions of multiple software "agents" to achieve shared goals. This is an important skill for real-world applications like self-driving cars or robotic assistants, where multiple components need to work together.
The researchers designed experiments to test how well LLMs could manage these multi-agent coordination challenges. They wanted to see if LLMs could plan and communicate effectively to get the different agents to cooperate and complete tasks.
The results provide insights into the strengths and limitations of LLMs when it comes to this type of collaborative problem-solving. The findings can help guide further research and development to enhance the general capabilities of LLMs and make them more useful for real-world applications that require teamwork and coordination.
Technical Explanation
The paper evaluates the multi-agent coordination abilities of large language models (LLMs) through a series of experiments. LLMs are AI systems trained on massive text datasets to perform various natural language processing tasks.
The researchers designed a multi-agent task environment where multiple software agents must work together to achieve shared goals. They tested different LLM-based approaches for coordinating the agents, including:
- Direct Coordination: The LLM directly issues commands to control the individual agents.
- Indirect Coordination: The LLM generates high-level plans and instructions that the agents then follow.
- Hybrid Coordination: A combination of direct and indirect coordination.
The experiments measured the LLMs' ability to plan efficient strategies, communicate effectively, and adapt to changing circumstances. The researchers also explored how different LLM architectures and training approaches impacted multi-agent coordination performance.
The results indicate that LLMs can demonstrate some multi-agent coordination capabilities, but also have significant limitations. The indirect and hybrid approaches generally outperformed direct coordination, suggesting LLMs are better at providing high-level guidance than low-level control. However, the LLMs struggled with long-term planning, communication breakdowns, and adapting to dynamic environments.
Critical Analysis
The paper provides valuable insights into the multi-agent coordination abilities of large language models, but also highlights important limitations that require further research and development.
One key limitation is the LLMs' difficulty with long-term planning and adaptability. The experiments showed the models struggled to maintain effective coordination strategies as the tasks became more complex and dynamic. This suggests LLMs may not be well-suited for real-world applications that require robust, flexible coordination over extended periods.
Additionally, the paper notes issues with communication breakdowns between the LLM and the agents. This points to challenges in developing reliable mechanisms for LLMs to provide clear, unambiguous instructions and for the agents to give meaningful feedback. Addressing these communication challenges will be crucial for improving multi-agent coordination capabilities.
The researchers also acknowledge that their experiments were conducted in a relatively simple, controlled environment. Scaling these coordination tasks to more realistic, higher-stakes scenarios with greater environmental complexity and a larger number of agents remains an open challenge. Evaluating the performance of LLMs in these more demanding settings will be an important area for future research.
Conclusion
This paper offers a valuable assessment of the multi-agent coordination abilities of large language models. While LLMs demonstrate some promising capabilities in this domain, the research also uncovers significant limitations that must be addressed through further development and testing.
Understanding the strengths and weaknesses of LLMs for multi-agent coordination is crucial for realizing their potential in real-world applications like autonomous systems and robotic control. The insights from this paper can help guide future research to enhance the general capabilities of LLMs and unlock new possibilities for collaborative, intelligent systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
AgentCoord: Visually Exploring Coordination Strategy for LLM-based Multi-Agent Collaboration
Bo Pan, Jiaying Lu, Ke Wang, Li Zheng, Zhen Wen, Yingchaojie Feng, Minfeng Zhu, Wei Chen
0
0
The potential of automatic task-solving through Large Language Model (LLM)-based multi-agent collaboration has recently garnered widespread attention from both the research community and industry. While utilizing natural language to coordinate multiple agents presents a promising avenue for democratizing agent technology for general users, designing coordination strategies remains challenging with existing coordination frameworks. This difficulty stems from the inherent ambiguity of natural language for specifying the collaboration process and the significant cognitive effort required to extract crucial information (e.g. agent relationship, task dependency, result correspondence) from a vast amount of text-form content during exploration. In this work, we present a visual exploration framework to facilitate the design of coordination strategies in multi-agent collaboration. We first establish a structured representation for LLM-based multi-agent coordination strategy to regularize the ambiguity of natural language. Based on this structure, we devise a three-stage generation method that leverages LLMs to convert a user's general goal into an executable initial coordination strategy. Users can further intervene at any stage of the generation process, utilizing LLMs and a set of interactions to explore alternative strategies. Whenever a satisfactory strategy is identified, users can commence the collaboration and examine the visually enhanced execution result. We develop AgentCoord, a prototype interactive system, and conduct a formal user study to demonstrate the feasibility and effectiveness of our approach.
4/19/2024
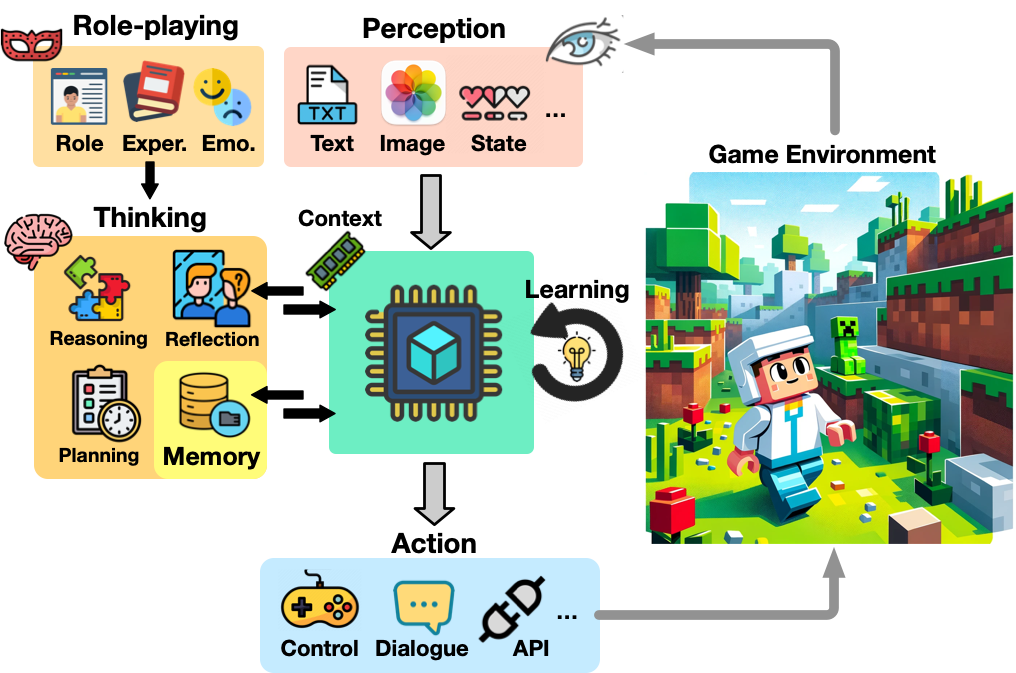
A Survey on Large Language Model-Based Game Agents
Sihao Hu, Tiansheng Huang, Fatih Ilhan, Selim Tekin, Gaowen Liu, Ramana Kompella, Ling Liu
0
0
The development of game agents holds a critical role in advancing towards Artificial General Intelligence (AGI). The progress of LLMs and their multimodal counterparts (MLLMs) offers an unprecedented opportunity to evolve and empower game agents with human-like decision-making capabilities in complex computer game environments. This paper provides a comprehensive overview of LLM-based game agents from a holistic viewpoint. First, we introduce the conceptual architecture of LLM-based game agents, centered around six essential functional components: perception, memory, thinking, role-playing, action, and learning. Second, we survey existing representative LLM-based game agents documented in the literature with respect to methodologies and adaptation agility across six genres of games, including adventure, communication, competition, cooperation, simulation, and crafting & exploration games. Finally, we present an outlook of future research and development directions in this burgeoning field. A curated list of relevant papers is maintained and made accessible at: https://github.com/git-disl/awesome-LLM-game-agent-papers.
4/3/2024
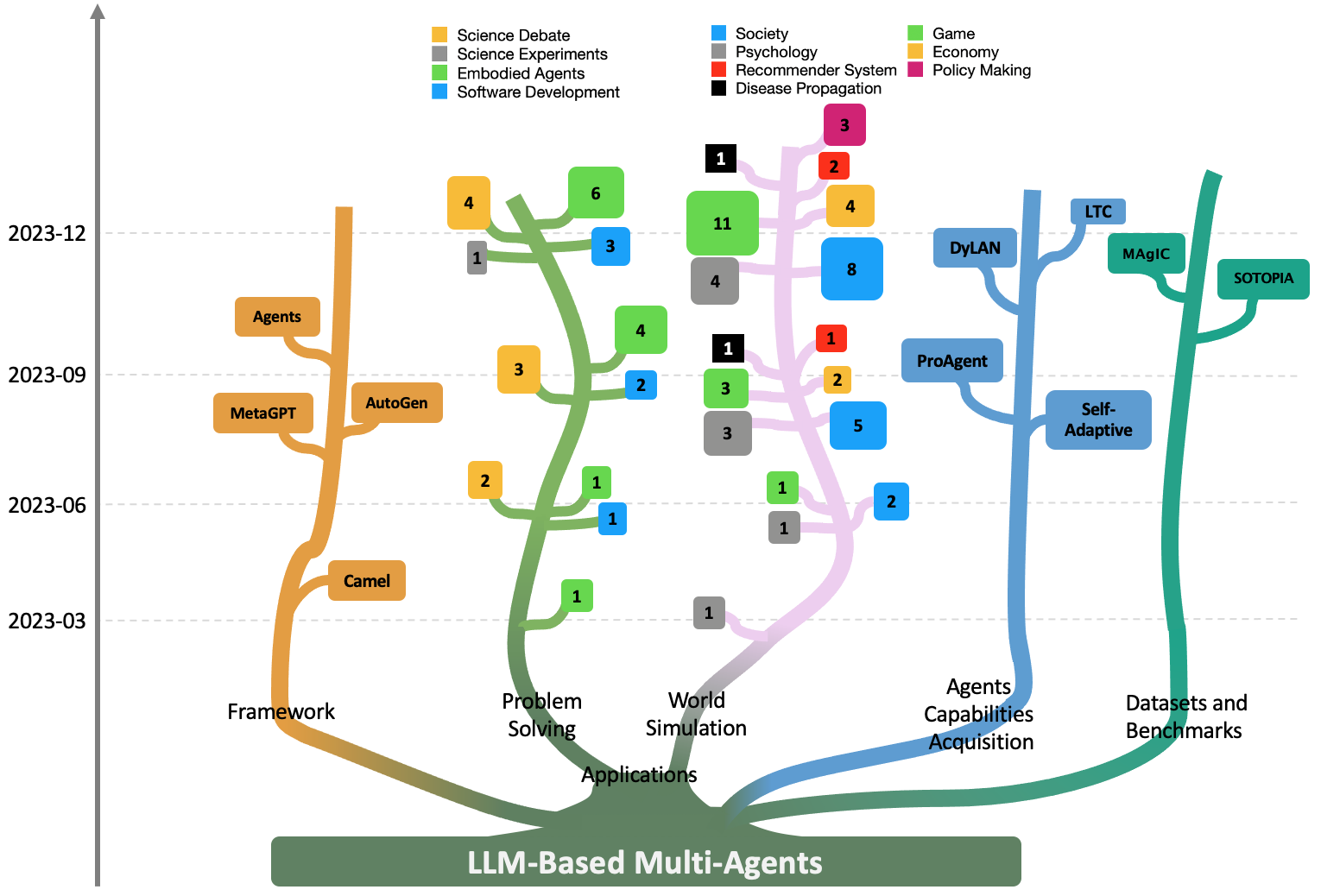
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, Xiangliang Zhang
0
0
Large Language Models (LLMs) have achieved remarkable success across a wide array of tasks. Due to the impressive planning and reasoning abilities of LLMs, they have been used as autonomous agents to do many tasks automatically. Recently, based on the development of using one LLM as a single planning or decision-making agent, LLM-based multi-agent systems have achieved considerable progress in complex problem-solving and world simulation. To provide the community with an overview of this dynamic field, we present this survey to offer an in-depth discussion on the essential aspects of multi-agent systems based on LLMs, as well as the challenges. Our goal is for readers to gain substantial insights on the following questions: What domains and environments do LLM-based multi-agents simulate? How are these agents profiled and how do they communicate? What mechanisms contribute to the growth of agents' capacities? For those interested in delving into this field of study, we also summarize the commonly used datasets or benchmarks for them to have convenient access. To keep researchers updated on the latest studies, we maintain an open-source GitHub repository, dedicated to outlining the research on LLM-based multi-agent systems.
4/22/2024
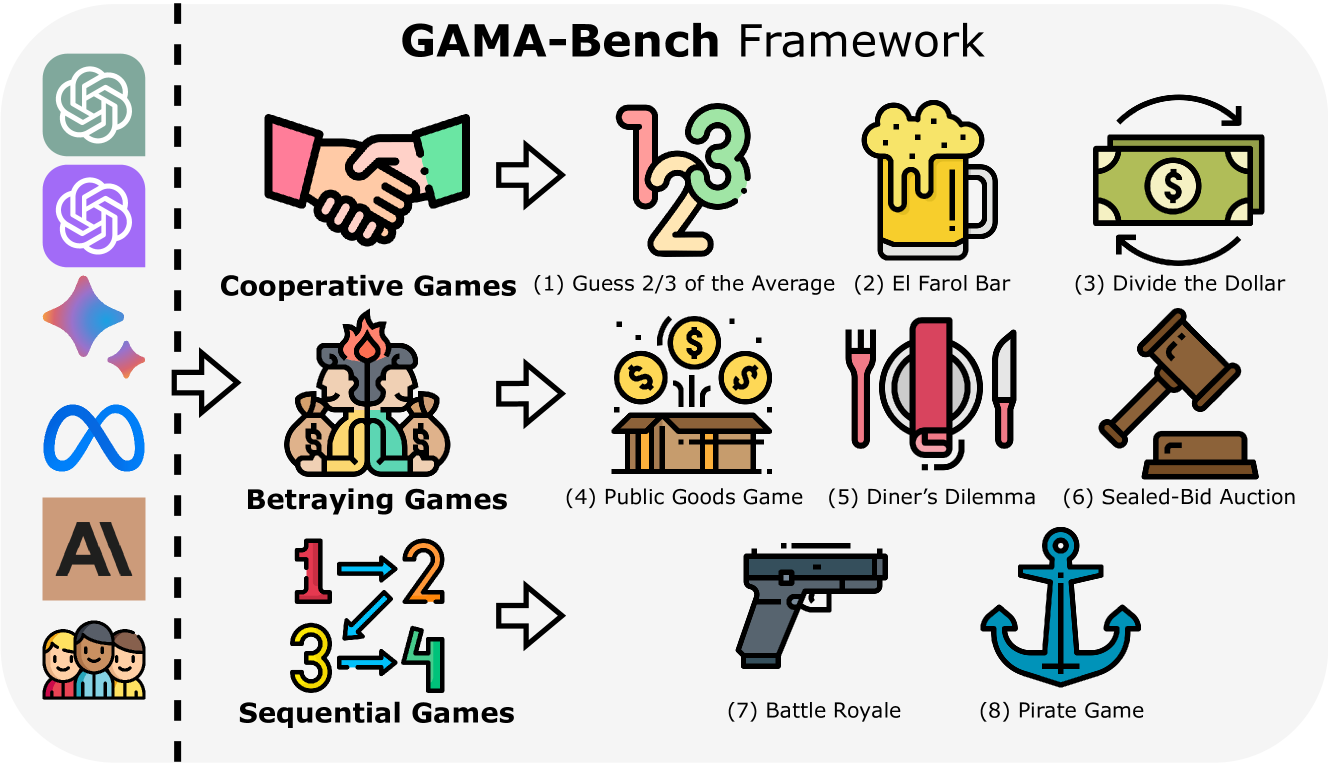
How Far Are We on the Decision-Making of LLMs? Evaluating LLMs' Gaming Ability in Multi-Agent Environments
Jen-tse Huang, Eric John Li, Man Ho Lam, Tian Liang, Wenxuan Wang, Youliang Yuan, Wenxiang Jiao, Xing Wang, Zhaopeng Tu, Michael R. Lyu
0
0
Decision-making, a complicated task requiring various types of abilities, presents an excellent framework for assessing Large Language Models (LLMs). Our research investigates LLMs' decision-making capabilities through the lens of a well-established field, Game Theory. We focus specifically on games that support the participation of more than two agents simultaneously. Subsequently, we introduce our framework, GAMA-Bench, including eight classical multi-agent games. We design a scoring scheme to assess a model's performance in these games quantitatively. Through GAMA-Bench, we investigate LLMs' robustness, generalizability, and enhancement strategies. Results reveal that while GPT-3.5 shows satisfying robustness, its generalizability is relatively limited. However, its performance can be improved through approaches such as Chain-of-Thought. Additionally, we conduct evaluations across various LLMs and find that GPT-4 outperforms other models on GAMA-Bench, achieving a score of 60.5. Moreover, Gemini-1.0-Pro and GPT-3.5 (0613, 1106, 0125) demonstrate similar intelligence on GAMA-Bench. The code and experimental results are made publicly available via https://github.com/CUHK-ARISE/GAMABench.
4/26/2024