LLM Dataset Inference: Did you train on my dataset?
2406.06443
0
0

Abstract
The proliferation of large language models (LLMs) in the real world has come with a rise in copyright cases against companies for training their models on unlicensed data from the internet. Recent works have presented methods to identify if individual text sequences were members of the model's training data, known as membership inference attacks (MIAs). We demonstrate that the apparent success of these MIAs is confounded by selecting non-members (text sequences not used for training) belonging to a different distribution from the members (e.g., temporally shifted recent Wikipedia articles compared with ones used to train the model). This distribution shift makes membership inference appear successful. However, most MIA methods perform no better than random guessing when discriminating between members and non-members from the same distribution (e.g., in this case, the same period of time). Even when MIAs work, we find that different MIAs succeed at inferring membership of samples from different distributions. Instead, we propose a new dataset inference method to accurately identify the datasets used to train large language models. This paradigm sits realistically in the modern-day copyright landscape, where authors claim that an LLM is trained over multiple documents (such as a book) written by them, rather than one particular paragraph. While dataset inference shares many of the challenges of membership inference, we solve it by selectively combining the MIAs that provide positive signal for a given distribution, and aggregating them to perform a statistical test on a given dataset. Our approach successfully distinguishes the train and test sets of different subsets of the Pile with statistically significant p-values < 0.1, without any false positives.
Create account to get full access
Overview
- This paper investigates techniques for detecting if a large language model (LLM) was trained on a specific dataset.
- The authors propose several methods for "LLM dataset inference" - determining if an LLM was trained on a particular dataset.
- The techniques aim to provide a way for dataset owners to verify if their data was used to train an LLM, without requiring access to the model's training data or architecture.
Plain English Explanation
The paper explores ways to determine if a large language model (LLM) - such as ChatGPT or GPT-3 - was trained on a specific dataset that you own or have access to. This could be useful if you want to verify that your data was used to train a particular model, without needing to know the full details of the model's architecture or the complete training dataset.
The key ideas involve creating "fingerprints" or "signatures" that can uniquely identify if an LLM was exposed to your dataset during training. This might involve techniques like Pandora's White Box, Towards Black-Box Membership Inference Attack, or other methods that can detect subtle patterns or artifacts left behind in the model's outputs.
The goal is to give dataset owners more transparency and control over how their data is being used, without requiring them to have extensive technical knowledge about machine learning models.
Technical Explanation
The paper proposes several techniques for "LLM dataset inference" - determining if a large language model (LLM) was trained on a specific dataset:
-
Pandora's White Box: This approach involves creating a "white box" model that can precisely detect if an LLM was trained on a particular dataset. It works by analyzing the internal weights and activations of the target LLM to find tell-tale signatures of the training data.
-
Towards Black-Box Membership Inference Attack: This method takes a "black box" approach, where the internal architecture of the LLM is not accessible. Instead, it uses the model's outputs to infer if a dataset was used during training, without needing to inspect the model itself.
-
Copyright Traps and Mosaic Memory: These techniques involve embedding "traps" or "triggers" into the training data, which can then be detected in the outputs of an LLM to determine if that data was used during training.
The authors evaluate these techniques on several large language models and datasets, demonstrating their effectiveness at accurately identifying if an LLM was trained on a specific corpus of text.
Critical Analysis
The paper presents some interesting and potentially useful techniques for dataset owners to verify the use of their data in training large language models. However, there are a few notable limitations and caveats to consider:
-
Model Access: Many of the proposed methods require some level of access to the target LLM, either its internal architecture or its output behavior. This may not always be feasible, especially for commercially-deployed models.
-
Data Generalization: The techniques rely on finding unique signatures or artifacts in the model, which may not generalize well to all types of datasets or modeling approaches. More research is needed to understand the broader applicability of these methods.
-
Privacy Concerns: While the goal is to provide dataset owners with more transparency, the techniques could also raise privacy concerns if used irresponsibly to track or monitor the use of sensitive data.
-
Adversarial Robustness: The authors acknowledge that adversaries may be able to develop countermeasures to avoid detection, so continued research is needed to make these methods more robust.
Overall, the paper presents a valuable line of research, but there are still important challenges to address before these techniques could be widely deployed in practice.
Conclusion
This paper explores methods for "LLM dataset inference" - determining if a large language model was trained on a specific dataset. The proposed techniques, such as Pandora's White Box, Towards Black-Box Membership Inference Attack, and Copyright Traps, aim to provide dataset owners with a way to verify the use of their data in training LLMs, without requiring access to the model's internals.
While these methods show promise, there are some notable limitations and potential concerns that would need to be addressed, such as model access requirements, generalization to diverse datasets, and privacy implications. Continued research is needed to make these techniques more robust and practical for real-world deployment.
Overall, this work contributes to the growing field of AI transparency and accountability, empowering dataset owners to better understand how their data is being used in the development of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
Inherent Challenges of Post-Hoc Membership Inference for Large Language Models
Matthieu Meeus, Shubham Jain, Marek Rei, Yves-Alexandre de Montjoye
0
0
Large Language Models (LLMs) are often trained on vast amounts of undisclosed data, motivating the development of post-hoc Membership Inference Attacks (MIAs) to gain insight into their training data composition. However, in this paper, we identify inherent challenges in post-hoc MIA evaluation due to potential distribution shifts between collected member and non-member datasets. Using a simple bag-of-words classifier, we demonstrate that datasets used in recent post-hoc MIAs suffer from significant distribution shifts, in some cases achieving near-perfect distinction between members and non-members. This implies that previously reported high MIA performance may be largely attributable to these shifts rather than model memorization. We confirm that randomized, controlled setups eliminate such shifts and thus enable the development and fair evaluation of new MIAs. However, we note that such randomized setups are rarely available for the latest LLMs, making post-hoc data collection still required to infer membership for real-world LLMs. As a potential solution, we propose a Regression Discontinuity Design (RDD) approach for post-hoc data collection, which substantially mitigates distribution shifts. Evaluating various MIA methods on this RDD setup yields performance barely above random guessing, in stark contrast to previously reported results. Overall, our findings highlight the challenges in accurately measuring LLM memorization and the need for careful experimental design in (post-hoc) membership inference tasks.
6/27/2024
🏋️
Pandora's White-Box: Precise Training Data Detection and Extraction in Large Language Models
Jeffrey G. Wang, Jason Wang, Marvin Li, Seth Neel
0
0
In this paper we develop state-of-the-art privacy attacks against Large Language Models (LLMs), where an adversary with some access to the model tries to learn something about the underlying training data. Our headline results are new membership inference attacks (MIAs) against pretrained LLMs that perform hundreds of times better than baseline attacks, and a pipeline showing that over 50% (!) of the fine-tuning dataset can be extracted from a fine-tuned LLM in natural settings. We consider varying degrees of access to the underlying model, pretraining and fine-tuning data, and both MIAs and training data extraction. For pretraining data, we propose two new MIAs: a supervised neural network classifier that predicts training data membership on the basis of (dimensionality-reduced) model gradients, as well as a variant of this attack that only requires logit access to the model by leveraging recent model-stealing work on LLMs. To our knowledge this is the first MIA that explicitly incorporates model-stealing information. Both attacks outperform existing black-box baselines, and our supervised attack closes the gap between MIA attack success against LLMs and the strongest known attacks for other machine learning models. In fine-tuning, we find that a simple attack based on the ratio of the loss between the base and fine-tuned models is able to achieve near-perfect MIA performance; we then leverage our MIA to extract a large fraction of the fine-tuning dataset from fine-tuned Pythia and Llama models. Our code is available at github.com/safr-ai-lab/pandora-llm.
6/26/2024
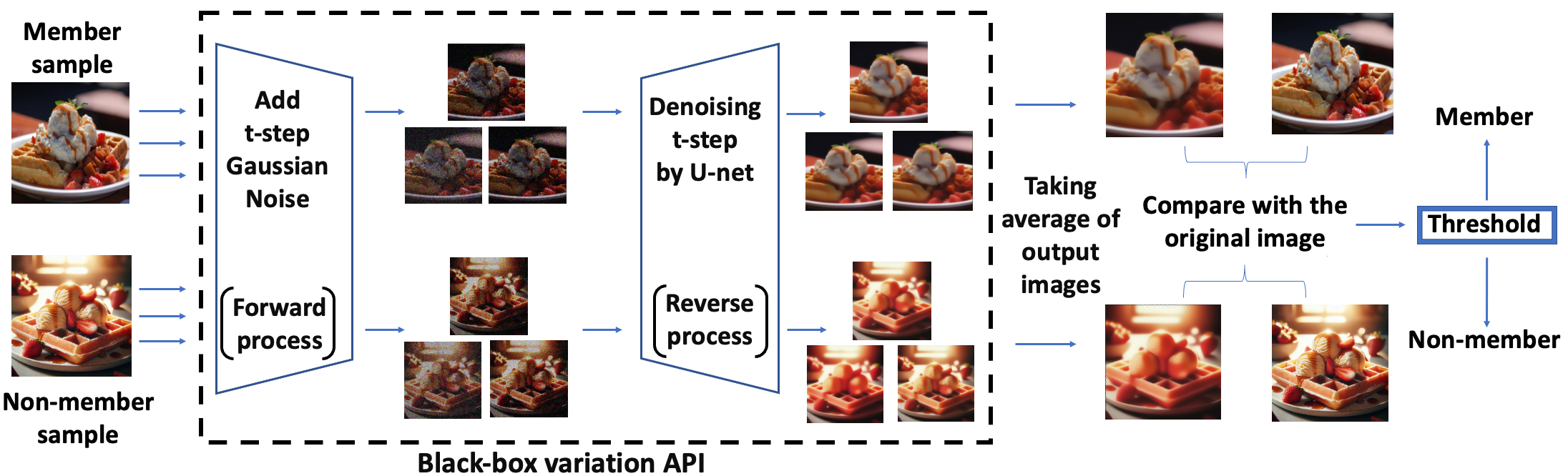
Towards Black-Box Membership Inference Attack for Diffusion Models
Jingwei Li, Jing Dong, Tianxing He, Jingzhao Zhang
0
0
Identifying whether an artwork was used to train a diffusion model is an important research topic, given the rising popularity of AI-generated art and the associated copyright concerns. The work approaches this problem from the membership inference attack (MIA) perspective. We first identify the limitations of applying existing MIA methods for copyright protection: the required access of internal U-nets and the choice of non-member datasets for evaluation. To address the above problems, we introduce a novel black-box membership inference attack method that operates without needing access to the model's internal U-net. We then construct a DALL-E generated dataset for a more comprehensive evaluation. We validate our method across various setups, and our experimental results outperform previous works.
6/3/2024

Noisy Neighbors: Efficient membership inference attacks against LLMs
Filippo Galli, Luca Melis, Tommaso Cucinotta
0
0
The potential of transformer-based LLMs risks being hindered by privacy concerns due to their reliance on extensive datasets, possibly including sensitive information. Regulatory measures like GDPR and CCPA call for using robust auditing tools to address potential privacy issues, with Membership Inference Attacks (MIA) being the primary method for assessing LLMs' privacy risks. Differently from traditional MIA approaches, often requiring computationally intensive training of additional models, this paper introduces an efficient methodology that generates textit{noisy neighbors} for a target sample by adding stochastic noise in the embedding space, requiring operating the target model in inference mode only. Our findings demonstrate that this approach closely matches the effectiveness of employing shadow models, showing its usability in practical privacy auditing scenarios.
6/26/2024