Noisy Neighbors: Efficient membership inference attacks against LLMs
2406.16565
0
0

Abstract
The potential of transformer-based LLMs risks being hindered by privacy concerns due to their reliance on extensive datasets, possibly including sensitive information. Regulatory measures like GDPR and CCPA call for using robust auditing tools to address potential privacy issues, with Membership Inference Attacks (MIA) being the primary method for assessing LLMs' privacy risks. Differently from traditional MIA approaches, often requiring computationally intensive training of additional models, this paper introduces an efficient methodology that generates textit{noisy neighbors} for a target sample by adding stochastic noise in the embedding space, requiring operating the target model in inference mode only. Our findings demonstrate that this approach closely matches the effectiveness of employing shadow models, showing its usability in practical privacy auditing scenarios.
Create account to get full access
Overview
- This paper introduces a novel and efficient membership inference attack against large language models (LLMs) that can accurately determine whether a given input was used to train the model.
- The attack exploits the noisy behavior of LLMs, which can be observed through small perturbations to the input, to infer membership without requiring access to the model's internal parameters or training data.
- The researchers demonstrate the effectiveness of their attack on popular LLMs like GPT-2 and show that it outperforms previous membership inference techniques in both accuracy and efficiency.
Plain English Explanation
The paper presents a new way to figure out if a particular piece of text was used to train a large language model (LLM) like GPT-2. This is called a "membership inference attack," and it can reveal sensitive information about the model's training data.
The key insight is that LLMs behave in a slightly "noisy" or unpredictable way, even for small changes to the input text. By carefully observing these small differences in the model's outputs, the researchers found they could reliably determine if a given piece of text was part of the original training data or not. [This builds on prior work on membership inference attacks, such as <a href="https://aimodels.fyi/papers/arxiv/fundamental-limits-membership-inference-attacks-machine-learning">this paper</a> and <a href="https://aimodels.fyi/papers/arxiv/pandoras-white-box-precise-training-data-detection">this one</a>.]
Importantly, their attack doesn't require any special access to the model's internal workings or the actual training data. It just looks at the model's outputs in a clever way. This makes it more practical and efficient than previous membership inference techniques.
The researchers demonstrated their attack on popular LLMs like GPT-2, and showed it outperformed other approaches in both accuracy and speed. This highlights the potential privacy risks of these large language models, even when they're treated as "black boxes."
Technical Explanation
The paper introduces a novel and efficient membership inference attack against large language models (LLMs) that can accurately determine whether a given input was used to train the model.
At the core of the attack is the observation that LLMs exhibit a "noisy" behavior, where small perturbations to the input can lead to observable differences in the model's outputs. The researchers leverage this "noisy neighbor" effect to infer membership without requiring access to the model's internal parameters or training data.
Specifically, the attack works as follows:
- The attacker selects a target input and generates a set of perturbed versions of that input by making small, imperceptible changes.
- The attacker then queries the target LLM with both the original and perturbed inputs, and collects the model's outputs.
- By analyzing the differences in the model's responses to the original and perturbed inputs, the attacker can infer whether the target input was part of the LLM's training data or not.
The researchers demonstrate the effectiveness of their attack on popular LLMs like GPT-2 and show that it outperforms previous membership inference techniques, such as those described in <a href="https://aimodels.fyi/papers/arxiv/towards-black-box-membership-inference-attack-diffusion">this paper</a> and <a href="https://aimodels.fyi/papers/arxiv/low-cost-high-power-membership-inference-attacks">this one</a>, in both accuracy and efficiency.
Critical Analysis
The paper presents a compelling and practical membership inference attack against LLMs, but it's important to consider some of the potential caveats and limitations.
First, while the attack doesn't require access to the model's internal parameters or training data, it does rely on the ability to query the target LLM and observe its outputs. In a real-world scenario, this may not always be feasible, particularly if the model is deployed in a strict black-box setting.
Additionally, the researchers acknowledge that their attack may be less effective against models that have been specifically hardened against membership inference attacks, such as through the use of differential privacy techniques during training. Further research would be needed to understand the robustness of their approach in the face of such countermeasures.
It's also worth noting that the paper focuses on the technical aspects of the attack, without delving deeply into the broader societal implications and ethical considerations. As these types of attacks become more prevalent, it will be important for the research community to engage in thoughtful discussions about the responsible development and deployment of LLMs.
Conclusion
This paper presents a novel and efficient membership inference attack against large language models (LLMs) that can accurately determine whether a given input was used to train the model. By exploiting the noisy behavior of LLMs, the researchers demonstrate an attack that outperforms previous techniques in both accuracy and efficiency, highlighting the potential privacy risks of these powerful models.
While the attack is technically impressive, it's crucial to consider the broader implications and work towards developing LLMs that are more robust to such privacy-compromising attacks. As the field of AI continues to advance, maintaining the trust and safety of these systems will be an ongoing challenge that requires careful consideration of both the technical and ethical dimensions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LLM Dataset Inference: Did you train on my dataset?
Pratyush Maini, Hengrui Jia, Nicolas Papernot, Adam Dziedzic
0
0
The proliferation of large language models (LLMs) in the real world has come with a rise in copyright cases against companies for training their models on unlicensed data from the internet. Recent works have presented methods to identify if individual text sequences were members of the model's training data, known as membership inference attacks (MIAs). We demonstrate that the apparent success of these MIAs is confounded by selecting non-members (text sequences not used for training) belonging to a different distribution from the members (e.g., temporally shifted recent Wikipedia articles compared with ones used to train the model). This distribution shift makes membership inference appear successful. However, most MIA methods perform no better than random guessing when discriminating between members and non-members from the same distribution (e.g., in this case, the same period of time). Even when MIAs work, we find that different MIAs succeed at inferring membership of samples from different distributions. Instead, we propose a new dataset inference method to accurately identify the datasets used to train large language models. This paradigm sits realistically in the modern-day copyright landscape, where authors claim that an LLM is trained over multiple documents (such as a book) written by them, rather than one particular paragraph. While dataset inference shares many of the challenges of membership inference, we solve it by selectively combining the MIAs that provide positive signal for a given distribution, and aggregating them to perform a statistical test on a given dataset. Our approach successfully distinguishes the train and test sets of different subsets of the Pile with statistically significant p-values < 0.1, without any false positives.
6/11/2024
🤯
Fundamental Limits of Membership Inference Attacks on Machine Learning Models
Eric Aubinais, Elisabeth Gassiat, Pablo Piantanida
0
0
Membership inference attacks (MIA) can reveal whether a particular data point was part of the training dataset, potentially exposing sensitive information about individuals. This article provides theoretical guarantees by exploring the fundamental statistical limitations associated with MIAs on machine learning models. More precisely, we first derive the statistical quantity that governs the effectiveness and success of such attacks. We then theoretically prove that in a non-linear regression setting with overfitting algorithms, attacks may have a high probability of success. Finally, we investigate several situations for which we provide bounds on this quantity of interest. Interestingly, our findings indicate that discretizing the data might enhance the algorithm's security. Specifically, it is demonstrated to be limited by a constant, which quantifies the diversity of the underlying data distribution. We illustrate those results through two simple simulations.
6/12/2024
🏋️
Pandora's White-Box: Precise Training Data Detection and Extraction in Large Language Models
Jeffrey G. Wang, Jason Wang, Marvin Li, Seth Neel
0
0
In this paper we develop state-of-the-art privacy attacks against Large Language Models (LLMs), where an adversary with some access to the model tries to learn something about the underlying training data. Our headline results are new membership inference attacks (MIAs) against pretrained LLMs that perform hundreds of times better than baseline attacks, and a pipeline showing that over 50% (!) of the fine-tuning dataset can be extracted from a fine-tuned LLM in natural settings. We consider varying degrees of access to the underlying model, pretraining and fine-tuning data, and both MIAs and training data extraction. For pretraining data, we propose two new MIAs: a supervised neural network classifier that predicts training data membership on the basis of (dimensionality-reduced) model gradients, as well as a variant of this attack that only requires logit access to the model by leveraging recent model-stealing work on LLMs. To our knowledge this is the first MIA that explicitly incorporates model-stealing information. Both attacks outperform existing black-box baselines, and our supervised attack closes the gap between MIA attack success against LLMs and the strongest known attacks for other machine learning models. In fine-tuning, we find that a simple attack based on the ratio of the loss between the base and fine-tuned models is able to achieve near-perfect MIA performance; we then leverage our MIA to extract a large fraction of the fine-tuning dataset from fine-tuned Pythia and Llama models. Our code is available at github.com/safr-ai-lab/pandora-llm.
6/26/2024
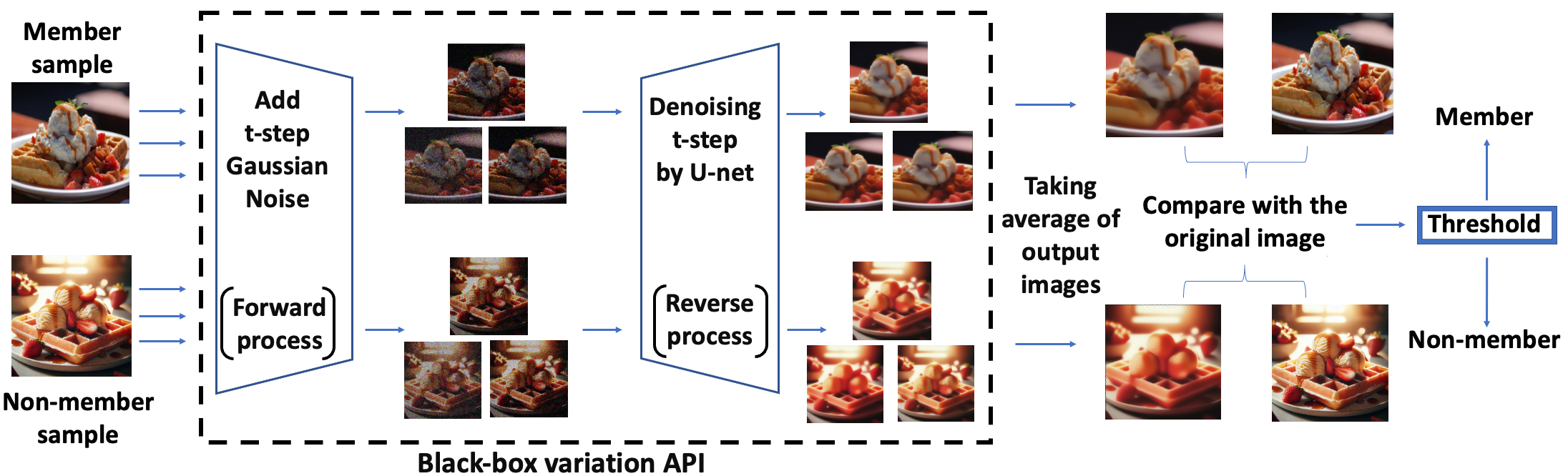
Towards Black-Box Membership Inference Attack for Diffusion Models
Jingwei Li, Jing Dong, Tianxing He, Jingzhao Zhang
0
0
Identifying whether an artwork was used to train a diffusion model is an important research topic, given the rising popularity of AI-generated art and the associated copyright concerns. The work approaches this problem from the membership inference attack (MIA) perspective. We first identify the limitations of applying existing MIA methods for copyright protection: the required access of internal U-nets and the choice of non-member datasets for evaluation. To address the above problems, we introduce a novel black-box membership inference attack method that operates without needing access to the model's internal U-net. We then construct a DALL-E generated dataset for a more comprehensive evaluation. We validate our method across various setups, and our experimental results outperform previous works.
6/3/2024