LLM-RankFusion: Mitigating Intrinsic Inconsistency in LLM-based Ranking

0
Sign in to get full access
Overview
- This paper presents LLM-RankFusion, a method to mitigate the intrinsic inconsistency in large language model (LLM)-based ranking systems.
- LLMs can exhibit inconsistent behavior when ranking items, leading to sub-optimal performance.
- LLM-RankFusion aims to improve ranking consistency by combining multiple LLM-based ranking models.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. These models have been applied to various ranking tasks, such as search engine results or product recommendations. However, LLMs can sometimes be inconsistent when ranking items, producing different rankings for the same query.
The LLM-RankFusion approach addresses this issue by combining multiple LLM-based ranking models. The idea is that by aggregating the predictions from several models, the inconsistencies in individual models can be mitigated, leading to more stable and reliable rankings.
The paper demonstrates that LLM-RankFusion outperforms using a single LLM model for ranking, particularly on tasks where the LLMs exhibit high levels of inconsistency. This suggests that the fusion of multiple LLM-based models can be an effective way to improve the quality and consistency of rankings produced by these powerful AI systems.
Technical Explanation
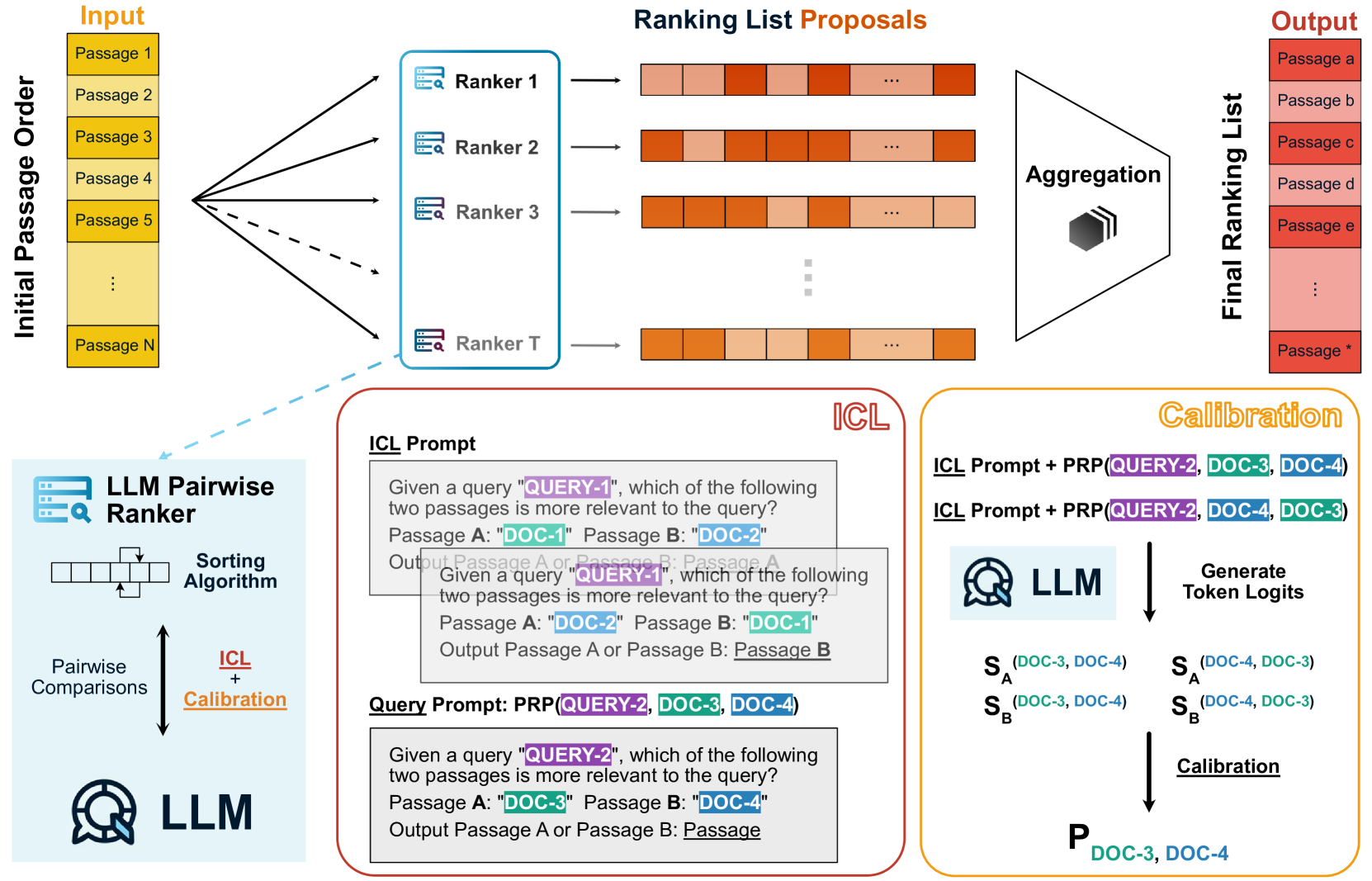
The key idea behind LLM-RankFusion is to combine the predictions of multiple LLM-based ranking models to mitigate their individual inconsistencies. The authors propose several fusion methods, including simple averaging, learned weighting, and permutation-based fusion.
The paper evaluates LLM-RankFusion on several benchmark ranking datasets, including information retrieval and recommendation tasks. The experiments show that LLM-RankFusion outperforms using a single LLM model, particularly in scenarios where the LLMs exhibit high levels of internal inconsistency.
The authors also analyze the properties of LLM-RankFusion, such as its ability to capture diverse ranking signals and its robustness to noisy or biased inputs. Additionally, they discuss the trade-offs between different fusion methods and provide guidelines for practitioners on selecting the most appropriate approach for their specific use case.
Critical Analysis
The paper presents a well-designed and thorough investigation of the LLM-RankFusion approach. The authors acknowledge that while LLMs have shown impressive performance in various tasks, their intrinsic inconsistency can be a significant limitation, particularly in high-stakes ranking applications.
One potential limitation of the research is the reliance on benchmark datasets, which may not fully capture the complexities of real-world ranking scenarios. Further evaluation on more diverse and challenging datasets could provide additional insights into the practical applicability of LLM-RankFusion.
Additionally, the paper does not explore the potential trade-offs between ranking consistency and other desirable properties, such as diversity or personalization. Investigating these trade-offs could help researchers and practitioners better understand the broader implications of the LLM-RankFusion approach.
Conclusion
The LLM-RankFusion method presented in this paper offers a promising approach to mitigating the intrinsic inconsistency in LLM-based ranking systems. By combining multiple LLM models, the authors demonstrate that it is possible to achieve more stable and reliable rankings, particularly in scenarios where individual LLMs exhibit high levels of inconsistency.
The findings of this research have significant implications for the development of robust and trustworthy ranking systems, which are crucial in domains such as search, recommendation, and decision support. As LLMs continue to advance and gain wider adoption, techniques like LLM-RankFusion will likely play an increasingly important role in ensuring the reliability and fairness of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLM-RankFusion: Mitigating Intrinsic Inconsistency in LLM-based Ranking
Yifan Zeng, Ojas Tendolkar, Raymond Baartmans, Qingyun Wu, Huazheng Wang, Lizhong Chen
Ranking passages by prompting a large language model (LLM) can achieve promising performance in modern information retrieval (IR) systems. A common approach is to sort the ranking list by prompting LLMs for pairwise comparison. However, sorting-based methods require consistent comparisons to correctly sort the passages, which we show that LLMs often violate. We identify two kinds of intrinsic inconsistency in LLM-based pairwise comparisons: order inconsistency which leads to conflicting results when switching the passage order, and transitive inconsistency which leads to non-transitive triads among all preference pairs. In this paper, we propose LLM-RankFusion, an LLM-based ranking framework that mitigates these inconsistencies and produces a robust ranking list. LLM-RankFusion mitigates order inconsistency using in-context learning (ICL) to demonstrate order-agnostic comparisons and calibration to estimate the underlying preference probability between two passages. We then address transitive inconsistency by aggregating the ranking results from multiple rankers. In our experiments, we empirically show that LLM-RankFusion can significantly reduce inconsistent pairwise comparison results, and improve the ranking quality by making the final ranking list more robust.
Read more6/4/2024

0
LLM-enhanced Reranking in Recommender Systems
Jingtong Gao, Bo Chen, Xiangyu Zhao, Weiwen Liu, Xiangyang Li, Yichao Wang, Zijian Zhang, Wanyu Wang, Yuyang Ye, Shanru Lin, Huifeng Guo, Ruiming Tang
Reranking is a critical component in recommender systems, playing an essential role in refining the output of recommendation algorithms. Traditional reranking models have focused predominantly on accuracy, but modern applications demand consideration of additional criteria such as diversity and fairness. Existing reranking approaches often fail to harmonize these diverse criteria effectively at the model level. Moreover, these models frequently encounter challenges with scalability and personalization due to their complexity and the varying significance of different reranking criteria in diverse scenarios. In response, we introduce a comprehensive reranking framework enhanced by LLM, designed to seamlessly integrate various reranking criteria while maintaining scalability and facilitating personalized recommendations. This framework employs a fully connected graph structure, allowing the LLM to simultaneously consider multiple aspects such as accuracy, diversity, and fairness through a coherent Chain-of-Thought (CoT) process. A customizable input mechanism is also integrated, enabling the tuning of the language model's focus to meet specific reranking needs. We validate our approach using three popular public datasets, where our framework demonstrates superior performance over existing state-of-the-art reranking models in balancing multiple criteria. The code for this implementation is publicly available.
Read more6/21/2024
0
TourRank: Utilizing Large Language Models for Documents Ranking with a Tournament-Inspired Strategy
Yiqun Chen, Qi Liu, Yi Zhang, Weiwei Sun, Daiting Shi, Jiaxin Mao, Dawei Yin
Large Language Models (LLMs) are increasingly employed in zero-shot documents ranking, yielding commendable results. However, several significant challenges still persist in LLMs for ranking: (1) LLMs are constrained by limited input length, precluding them from processing a large number of documents simultaneously; (2) The output document sequence is influenced by the input order of documents, resulting in inconsistent ranking outcomes; (3) Achieving a balance between cost and ranking performance is quite challenging. To tackle these issues, we introduce a novel documents ranking method called TourRank, which is inspired by the tournament mechanism. This approach alleviates the impact of LLM's limited input length through intelligent grouping, while the tournament-like points system ensures robust ranking, mitigating the influence of the document input sequence. We test TourRank with different LLMs on the TREC DL datasets and the BEIR benchmark. Experimental results show that TourRank achieves state-of-the-art performance at a reasonable cost.
Read more6/18/2024
🔗
0
Generating Diverse Criteria On-the-Fly to Improve Point-wise LLM Rankers
Fang Guo, Wenyu Li, Honglei Zhuang, Yun Luo, Yafu Li, Qi Zhu, Le Yan, Yue Zhang
The most recent pointwise Large Language Model (LLM) rankers have achieved remarkable ranking results. However, these rankers are hindered by two major drawbacks: (1) they fail to follow a standardized comparison guidance during the ranking process, and (2) they struggle with comprehensive considerations when dealing with complicated passages. To address these shortcomings, we propose to build a ranker that generates ranking scores based on a set of criteria from various perspectives. These criteria are intended to direct each perspective in providing a distinct yet synergistic evaluation. Our research, which examines eight datasets from the BEIR benchmark demonstrates that incorporating this multi-perspective criteria ensemble approach markedly enhanced the performance of pointwise LLM rankers.
Read more6/11/2024