LLM-Generated Tips Rival Expert-Created Tips in Helping Students Answer Quantum-Computing Questions

0

Sign in to get full access
Overview
- The provided paper examines how well large language models (LLMs) can generate tips to help students answer quantum computing questions, compared to tips created by human experts.
- The researchers had students answer quantum computing questions and provided them with either LLM-generated tips or expert-created tips.
- They found that the LLM-generated tips were just as effective as the expert-created tips in helping students answer the questions correctly.
Plain English Explanation
The researchers were interested in seeing if large language models could be used to generate helpful tips for students learning about quantum computing. Quantum computing is a complex and challenging topic, so the researchers wanted to see if an AI system could provide advice that was just as useful as tips created by human experts.
To test this, they had a group of students try to answer some questions about quantum computing. Some of the students were given tips generated by a large language model to help them, while other students received tips that were created by quantum computing experts.
The researchers found that the students who got the LLM-generated tips performed just as well on the questions as the students who received the expert-created tips. This suggests that the AI system was able to produce advice that was equally helpful for the students, even though it didn't have the same deep understanding of quantum computing that the human experts did.
This is an interesting finding because it shows that large language models can be used to create educational content that is just as effective as content created by human experts. This could be very useful, as LLMs can generate a lot of content quickly and at a lower cost than having experts create it. The researchers think this approach could be applied to other complex topics beyond just quantum computing.
Technical Explanation
The researchers conducted an experiment to compare the effectiveness of LLM-generated tips and expert-created tips in helping students answer quantum computing questions. They recruited a group of students and had them answer a set of quantum computing questions.
Some of the students were randomly assigned to receive LLM-generated tips to help them with the questions. These tips were generated by fine-tuning a large language model on a dataset of quantum computing explanations and then using the model to produce helpful tips.
The other students received tips that were created by human experts in quantum computing. These expert-created tips were designed to provide the same type of guidance and assistance as the LLM-generated tips.
After the students answered the questions, the researchers analyzed the results. They found that there was no significant difference in the performance of the students who received the LLM-generated tips versus the students who received the expert-created tips. Both groups were able to answer the questions equally well.
This suggests that the LLM-generated tips were just as effective as the expert-created tips in helping the students understand and apply the quantum computing concepts needed to answer the questions correctly. The researchers believe this demonstrates the potential for large language models to be used for generating high-quality educational content in complex domains like quantum computing.
Critical Analysis
The researchers acknowledge several limitations and caveats to their study. First, the sample size was relatively small, with only about 50 students participating in the experiment. A larger study with more participants could help confirm the robustness of the findings.
Additionally, the researchers only tested the tips on a single set of quantum computing questions. It's possible that the LLM-generated tips may perform differently on other types of questions or problem sets. Further research is needed to assess the generalizability of the results.
The researchers also note that the expert-created tips were designed to be as similar as possible to the LLM-generated tips in terms of content and format. This raises the question of whether the expert tips were truly representative of the full breadth and depth of guidance an expert could provide.
It's also worth considering whether the performance metric used - simply answering the questions correctly - fully captures the value of the educational tips. Factors like student engagement, conceptual understanding, and long-term retention could also be important to assess.
Overall, while the results are promising, additional research is needed to more thoroughly evaluate the capabilities of LLMs in generating effective educational content, especially for highly technical and complex topics like quantum computing.
Conclusion
This study provides initial evidence that large language models can generate educational tips that are just as helpful for students as tips created by human experts. This suggests that LLMs could be a powerful tool for creating high-quality educational content at scale, which could democratize access to learning materials and reduce the burden on expert subject matter creators.
However, the researchers acknowledge important limitations and areas for further investigation. Larger, more diverse studies are needed to fully assess the generalizability and robustness of these findings. Additionally, more nuanced metrics of educational effectiveness beyond just test performance should be considered.
If these results hold up under further scrutiny, the implications could be significant for the future of education and learning. LLM-generated content could make it easier and more cost-effective to provide tailored educational support to students, potentially improving learning outcomes across a wide range of domains. This is an exciting area of research with important real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLM-Generated Tips Rival Expert-Created Tips in Helping Students Answer Quantum-Computing Questions
Lars Krupp, Jonas Bley, Isacco Gobbi, Alexander Geng, Sabine Muller, Sungho Suh, Ali Moghiseh, Arcesio Castaneda Medina, Valeria Bartsch, Artur Widera, Herwig Ott, Paul Lukowicz, Jakob Karolus, Maximilian Kiefer-Emmanouilidis
Individual teaching is among the most successful ways to impart knowledge. Yet, this method is not always feasible due to large numbers of students per educator. Quantum computing serves as a prime example facing this issue, due to the hype surrounding it. Alleviating high workloads for teachers, often accompanied with individual teaching, is crucial for continuous high quality education. Therefore, leveraging Large Language Models (LLMs) such as GPT-4 to generate educational content can be valuable. We conducted two complementary studies exploring the feasibility of using GPT-4 to automatically generate tips for students. In the first one students (N=46) solved four multiple-choice quantum computing questions with either the help of expert-created or LLM-generated tips. To correct for possible biases towards LLMs, we introduced two additional conditions, making some participants believe that they were given expert-created tips, when they were given LLM-generated tips and vice versa. Our second study (N=23) aimed to directly compare the LLM-generated and expert-created tips, evaluating their quality, correctness and helpfulness, with both experienced educators and students participating. Participants in our second study found that the LLM-generated tips were significantly more helpful and pointed better towards relevant concepts than the expert-created tips, while being more prone to be giving away the answer. While participants in the first study performed significantly better in answering the quantum computing questions when given tips labeled as LLM-generated, even if they were created by an expert. This phenomenon could be a placebo effect induced by the participants' biases for LLM-generated content. Ultimately, we find that LLM-generated tips are good enough to be used instead of expert tips in the context of quantum computing basics.
Read more7/25/2024

0
Quantum Many-Body Physics Calculations with Large Language Models
Haining Pan, Nayantara Mudur, Will Taranto, Maria Tikhanovskaya, Subhashini Venugopalan, Yasaman Bahri, Michael P. Brenner, Eun-Ah Kim
Large language models (LLMs) have demonstrated an unprecedented ability to perform complex tasks in multiple domains, including mathematical and scientific reasoning. We demonstrate that with carefully designed prompts, LLMs can accurately carry out key calculations in research papers in theoretical physics. We focus on a broadly used approximation method in quantum physics: the Hartree-Fock method, requiring an analytic multi-step calculation deriving approximate Hamiltonian and corresponding self-consistency equations. To carry out the calculations using LLMs, we design multi-step prompt templates that break down the analytic calculation into standardized steps with placeholders for problem-specific information. We evaluate GPT-4's performance in executing the calculation for 15 research papers from the past decade, demonstrating that, with correction of intermediate steps, it can correctly derive the final Hartree-Fock Hamiltonian in 13 cases and makes minor errors in 2 cases. Aggregating across all research papers, we find an average score of 87.5 (out of 100) on the execution of individual calculation steps. Overall, the requisite skill for doing these calculations is at the graduate level in quantum condensed matter theory. We further use LLMs to mitigate the two primary bottlenecks in this evaluation process: (i) extracting information from papers to fill in templates and (ii) automatic scoring of the calculation steps, demonstrating good results in both cases. The strong performance is the first step for developing algorithms that automatically explore theoretical hypotheses at an unprecedented scale.
Read more8/26/2024
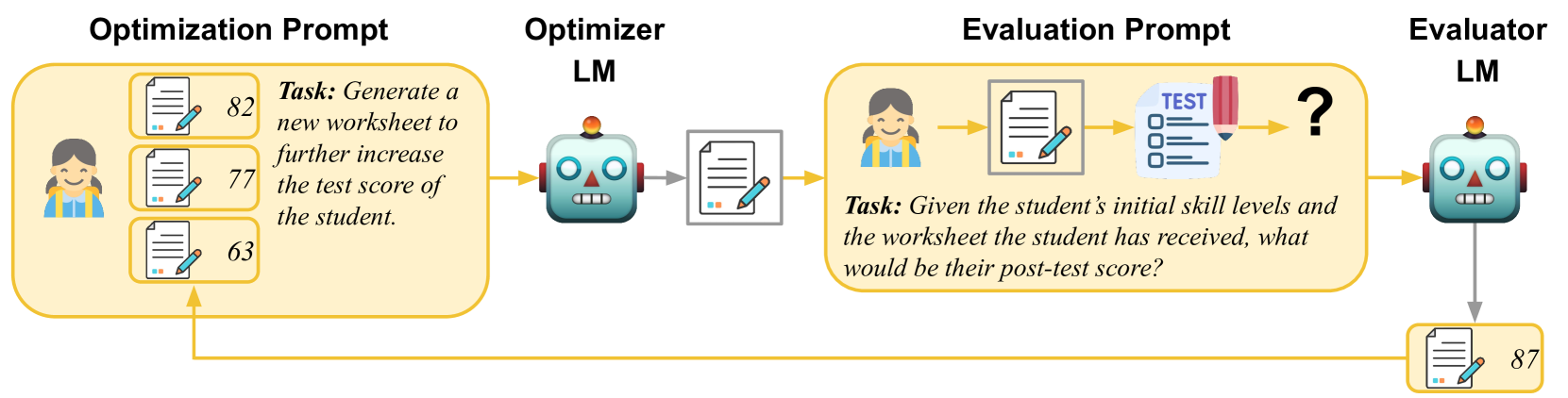
0
Evaluating and Optimizing Educational Content with Large Language Model Judgments
Joy He-Yueya, Noah D. Goodman, Emma Brunskill
Creating effective educational materials generally requires expensive and time-consuming studies of student learning outcomes. To overcome this barrier, one idea is to build computational models of student learning and use them to optimize instructional materials. However, it is difficult to model the cognitive processes of learning dynamics. We propose an alternative approach that uses Language Models (LMs) as educational experts to assess the impact of various instructions on learning outcomes. Specifically, we use GPT-3.5 to evaluate the overall effect of instructional materials on different student groups and find that it can replicate well-established educational findings such as the Expertise Reversal Effect and the Variability Effect. This demonstrates the potential of LMs as reliable evaluators of educational content. Building on this insight, we introduce an instruction optimization approach in which one LM generates instructional materials using the judgments of another LM as a reward function. We apply this approach to create math word problem worksheets aimed at maximizing student learning gains. Human teachers' evaluations of these LM-generated worksheets show a significant alignment between the LM judgments and human teacher preferences. We conclude by discussing potential divergences between human and LM opinions and the resulting pitfalls of automating instructional design.
Read more5/7/2024
🏋️
0
Qiskit Code Assistant: Training LLMs for generating Quantum Computing Code
Nicolas Dupuis, Luca Buratti, Sanjay Vishwakarma, Aitana Viudes Forrat, David Kremer, Ismael Faro, Ruchir Puri, Juan Cruz-Benito
Code Large Language Models (Code LLMs) have emerged as powerful tools, revolutionizing the software development landscape by automating the coding process and reducing time and effort required to build applications. This paper focuses on training Code LLMs to specialize in the field of quantum computing. We begin by discussing the unique needs of quantum computing programming, which differ significantly from classical programming approaches or languages. A Code LLM specializing in quantum computing requires a foundational understanding of quantum computing and quantum information theory. However, the scarcity of available quantum code examples and the rapidly evolving field, which necessitates continuous dataset updates, present significant challenges. Moreover, we discuss our work on training Code LLMs to produce high-quality quantum code using the Qiskit library. This work includes an examination of the various aspects of the LLMs used for training and the specific training conditions, as well as the results obtained with our current models. To evaluate our models, we have developed a custom benchmark, similar to HumanEval, which includes a set of tests specifically designed for the field of quantum computing programming using Qiskit. Our findings indicate that our model outperforms existing state-of-the-art models in quantum computing tasks. We also provide examples of code suggestions, comparing our model to other relevant code LLMs. Finally, we introduce a discussion on the potential benefits of Code LLMs for quantum computing computational scientists, researchers, and practitioners. We also explore various features and future work that could be relevant in this context.
Read more5/31/2024