LLM-Powered Grapheme-to-Phoneme Conversion: Benchmark and Case Study

0

Sign in to get full access
Overview
- This paper evaluates the use of large language models (LLMs) for the task of grapheme-to-phoneme (G2P) conversion.
- G2P conversion is the process of transforming written words (graphemes) into their corresponding pronunciations (phonemes).
- The authors benchmark several LLM-based approaches on a diverse dataset and provide a case study on the model's performance.
Plain English Explanation
The paper explores using large language models to convert written words into their pronunciations. This process, called grapheme-to-phoneme (G2P) conversion, is important for applications like text-to-speech and voice recognition.
The researchers tested several LLM-based approaches on a wide range of words to see how well they could perform this task. They found that LLMs can be effective for G2P conversion, but there are still some limitations and challenges to address.
For example, LLMs may struggle with context-sensitive pronunciations, where the same written word can have different pronunciations depending on the surrounding words. The paper provides a detailed case study examining these types of issues.
Overall, the research suggests that LLMs hold promise for G2P conversion, but there is still room for improvement, especially when it comes to handling the nuances of language and pronunciation.
Technical Explanation
The paper presents a benchmark and case study on using large language models (LLMs) for the task of grapheme-to-phoneme (G2P) conversion.
The authors evaluate several LLM-based approaches on a diverse dataset covering multiple languages and accents. They assess the models' performance on both overall accuracy and specific cases like context-sensitive phonemes.
The case study delves deeper into the LLM's handling of context-sensitive pronunciations, where the same written word can have different phoneme representations depending on the surrounding words. The researchers analyze failure cases and discuss the challenges involved.
The results indicate that LLMs can be effective for G2P conversion, but there are still some limitations. The models may struggle with rare words, ambiguous pronunciations, and accounting for contextual information. The paper highlights areas for further research and improvements in this domain.
Critical Analysis
The paper provides a thorough benchmark and case study on the use of LLMs for grapheme-to-phoneme conversion, which is an important task for various language-related applications. The researchers' approach of testing the models on a diverse dataset and delving into specific failure cases is commendable.
One potential limitation of the study is the scope of the dataset and languages covered. While the dataset is diverse, it may not fully represent the breadth of pronunciations and linguistic nuances found in the real world. Expanding the evaluation to include more languages, regional dialects, and edge cases could further validate the findings.
Additionally, the paper does not explore the potential impact of model size, training data, or other architectural choices on the LLMs' performance. Investigating these factors could yield valuable insights for developing more robust and versatile G2P systems.
The case study on context-sensitive phonemes is particularly relevant, as it highlights a key challenge in G2P conversion that requires further research. Exploring techniques to better incorporate contextual information and handle ambiguous pronunciations could lead to significant improvements in the field.
Overall, the paper presents a solid benchmark and valuable insights into the capabilities and limitations of LLMs for grapheme-to-phoneme conversion. The findings can inform future research and development in this domain, contributing to the advancement of text-to-speech, voice recognition, and other language-based technologies.
Conclusion
This paper examines the use of large language models for the task of grapheme-to-phoneme conversion, which is crucial for applications like text-to-speech and voice recognition.
The researchers benchmark several LLM-based approaches on a diverse dataset, evaluating both overall accuracy and specific challenges like context-sensitive pronunciations. The case study delves deeper into these context-sensitive issues, highlighting the limitations of current LLM-based G2P systems.
The findings suggest that LLMs hold promise for G2P conversion, but there are still areas for improvement, particularly in handling the nuances of language and pronunciation. Expanding the dataset, exploring model architectures, and further investigating context-sensitive phonemes could lead to more robust and versatile G2P solutions.
This research contributes valuable insights to the ongoing efforts in developing advanced language processing capabilities, which have far-reaching implications for a wide range of applications in the field of human-computer interaction and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLM-Powered Grapheme-to-Phoneme Conversion: Benchmark and Case Study
Mahta Fetrat Qharabagh, Zahra Dehghanian, Hamid R. Rabiee
Grapheme-to-phoneme (G2P) conversion is critical in speech processing, particularly for applications like speech synthesis. G2P systems must possess linguistic understanding and contextual awareness of languages with polyphone words and context-dependent phonemes. Large language models (LLMs) have recently demonstrated significant potential in various language tasks, suggesting that their phonetic knowledge could be leveraged for G2P. In this paper, we evaluate the performance of LLMs in G2P conversion and introduce prompting and post-processing methods that enhance LLM outputs without additional training or labeled data. We also present a benchmarking dataset designed to assess G2P performance on sentence-level phonetic challenges of the Persian language. Our results show that by applying the proposed methods, LLMs can outperform traditional G2P tools, even in an underrepresented language like Persian, highlighting the potential of developing LLM-aided G2P systems.
Read more9/16/2024

0
PhonologyBench: Evaluating Phonological Skills of Large Language Models
Ashima Suvarna, Harshita Khandelwal, Nanyun Peng
Phonology, the study of speech's structure and pronunciation rules, is a critical yet often overlooked component in Large Language Model (LLM) research. LLMs are widely used in various downstream applications that leverage phonology such as educational tools and poetry generation. Moreover, LLMs can potentially learn imperfect associations between orthographic and phonological forms from the training data. Thus, it is imperative to benchmark the phonological skills of LLMs. To this end, we present PhonologyBench, a novel benchmark consisting of three diagnostic tasks designed to explicitly test the phonological skills of LLMs in English: grapheme-to-phoneme conversion, syllable counting, and rhyme word generation. Despite having no access to speech data, LLMs showcased notable performance on the PhonologyBench tasks. However, we observe a significant gap of 17% and 45% on Rhyme Word Generation and Syllable counting, respectively, when compared to humans. Our findings underscore the importance of studying LLM performance on phonological tasks that inadvertently impact real-world applications. Furthermore, we encourage researchers to choose LLMs that perform well on the phonological task that is closely related to the downstream application since we find that no single model consistently outperforms the others on all the tasks.
Read more4/8/2024
0
Benchmarking Large Language Models for Persian: A Preliminary Study Focusing on ChatGPT
Amirhossein Abaskohi, Sara Baruni, Mostafa Masoudi, Nesa Abbasi, Mohammad Hadi Babalou, Ali Edalat, Sepehr Kamahi, Samin Mahdizadeh Sani, Nikoo Naghavian, Danial Namazifard, Pouya Sadeghi, Yadollah Yaghoobzadeh
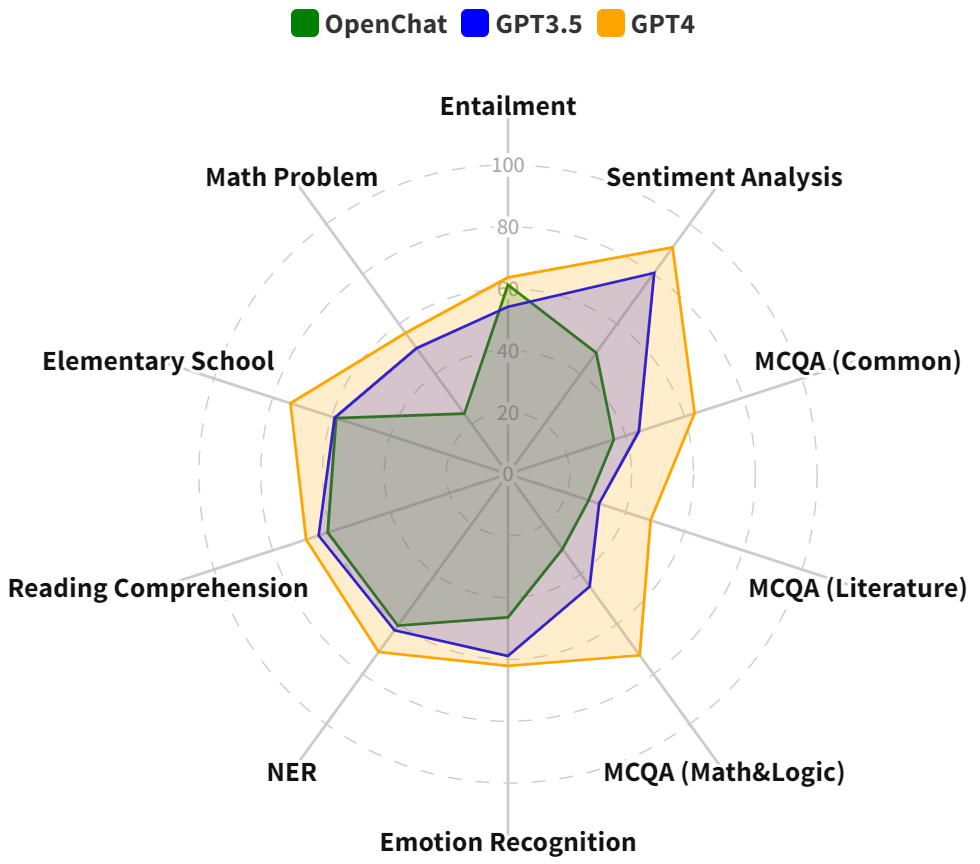
This paper explores the efficacy of large language models (LLMs) for Persian. While ChatGPT and consequent LLMs have shown remarkable performance in English, their efficiency for more low-resource languages remains an open question. We present the first comprehensive benchmarking study of LLMs across diverse Persian language tasks. Our primary focus is on GPT-3.5-turbo, but we also include GPT-4 and OpenChat-3.5 to provide a more holistic evaluation. Our assessment encompasses a diverse set of tasks categorized into classic, reasoning, and knowledge-based domains. To enable a thorough comparison, we evaluate LLMs against existing task-specific fine-tuned models. Given the limited availability of Persian datasets for reasoning tasks, we introduce two new benchmarks: one based on elementary school math questions and another derived from the entrance exams for 7th and 10th grades. Our findings reveal that while LLMs, especially GPT-4, excel in tasks requiring reasoning abilities and a broad understanding of general knowledge, they often lag behind smaller pre-trained models fine-tuned specifically for particular tasks. Additionally, we observe improved performance when test sets are translated to English before inputting them into GPT-3.5. These results highlight the significant potential for enhancing LLM performance in the Persian language. This is particularly noteworthy due to the unique attributes of Persian, including its distinct alphabet and writing styles.
Read more4/4/2024
💬
0
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, Lei Li
Large language models (LLMs) have demonstrated remarkable potential in handling multilingual machine translation (MMT). In this paper, we systematically investigate the advantages and challenges of LLMs for MMT by answering two questions: 1) How well do LLMs perform in translating massive languages? 2) Which factors affect LLMs' performance in translation? We thoroughly evaluate eight popular LLMs, including ChatGPT and GPT-4. Our empirical results show that translation capabilities of LLMs are continually involving. GPT-4 has beat the strong supervised baseline NLLB in 40.91% of translation directions but still faces a large gap towards the commercial translation system like Google Translate, especially on low-resource languages. Through further analysis, we discover that LLMs exhibit new working patterns when used for MMT. First, LLM can acquire translation ability in a resource-efficient way and generate moderate translation even on zero-resource languages. Second, instruction semantics can surprisingly be ignored when given in-context exemplars. Third, cross-lingual exemplars can provide better task guidance for low-resource translation than exemplars in the same language pairs. Code will be released at: https://github.com/NJUNLP/MMT-LLM.
Read more6/17/2024