LLM-Powered Text Simulation Attack Against ID-Free Recommender Systems

0

Sign in to get full access
Overview
- The paper explores a novel attack on ID-free recommender systems using large language models (LLMs) to simulate malicious user profiles.
- The attack aims to manipulate the recommendations generated by these systems without requiring individual user identities.
- Experiments demonstrate the attack's effectiveness in poisoning recommendations and the challenges in defending against it.
Plain English Explanation
The paper focuses on a new type of attack that can be used against recommender systems - computer programs that suggest products, content, or information to users based on their preferences.
In a typical recommender system, each user has a unique identifier (like an account) that the system uses to track their behavior and make personalized recommendations. However, the paper examines a new class of "ID-free" recommender systems that don't rely on these individual user identities.
The researchers discovered a vulnerability in these ID-free systems that allows attackers to manipulate the recommendations without needing to access or impersonate real user accounts. They developed a technique that uses large language models (powerful AI systems trained on vast amounts of text data) to automatically generate fake user profiles and insert them into the recommender system.
By carefully crafting these simulated user profiles, the attackers can steer the system's recommendations in a desired direction - for example, promoting certain products or content over others. The paper demonstrates through experiments that this "text simulation attack" can be highly effective at poisoning the recommendations, even when the system is designed to be secure.
This research highlights a concerning weakness in ID-free recommender systems and the challenges in defending against such attacks, especially as AI language models become more sophisticated. The findings underscore the importance of developing robust security measures to protect these types of systems from manipulation.
Technical Explanation
The paper investigates the security of ID-free recommender systems, which forgo the use of individual user identities in favor of more privacy-preserving approaches. The researchers propose a novel attack vector that leverages large language models (LLMs) to simulate malicious user profiles and inject them into the recommender system.
The key steps of the attack are:
- User Profile Simulation: The attackers use an LLM to automatically generate plausible user profiles, including textual content like reviews, product descriptions, and personal information.
- Profile Injection: The simulated user profiles are inserted into the recommender system, either by directly adding them to the dataset or by manipulating the system's inputs.
- Recommendation Poisoning: The presence of the malicious profiles skews the system's recommendations, promoting certain items or content over others, as the system attempts to provide personalized suggestions to these fake users.
The researchers conduct experiments on several ID-free recommender system architectures, including content-based and hybrid approaches, to assess the attack's effectiveness. They find that the text simulation attack can significantly degrade the quality of the recommendations, even when the systems employ various defense mechanisms.
The paper also discusses the challenges in defending against such attacks, as the use of LLMs makes the simulated profiles highly realistic and difficult to detect. Potential countermeasures, such as anomaly detection or adversarial training, are highlighted as areas for future research.
Critical Analysis
The paper presents a compelling and well-designed study on the vulnerabilities of ID-free recommender systems. The researchers have identified a critical weakness in these systems and demonstrated the potential impact of attacks using sophisticated language models.
One notable aspect of the research is the level of technical sophistication involved in the attack, which highlights the ongoing arms race between attackers and defenders in the field of AI security. As language models continue to advance, the ability to generate highly realistic user profiles will only become more challenging to detect and defend against.
However, the paper also acknowledges the limitations of the study, such as the use of specific dataset and system configurations. Exploring the attack's effectiveness across a wider range of recommender system architectures and real-world deployments would help strengthen the generalizability of the findings.
Additionally, while the paper discusses potential countermeasures, more in-depth analysis of their feasibility and effectiveness would be valuable. Investigating novel defense strategies, such as using textual ID learning or personalized recommendation via prompting, could provide further insights.
Overall, this research represents an important contribution to the ongoing discussions around the security and privacy implications of AI-powered recommender systems. The findings highlight the need for continued vigilance and innovation in developing robust defenses against evolving attack vectors.
Conclusion
The paper presents a novel attack that leverages large language models to simulate malicious user profiles and manipulate the recommendations generated by ID-free recommender systems. The researchers demonstrate the effectiveness of this text simulation attack, which can significantly degrade the quality of recommendations without requiring access to individual user identities.
The study underscores the security challenges posed by the increasing sophistication of language models and the need for robust defense mechanisms to protect AI-powered systems. As recommender systems continue to play a crucial role in shaping user experiences and content discovery, addressing these vulnerabilities will be crucial for maintaining the integrity and trustworthiness of these important technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLM-Powered Text Simulation Attack Against ID-Free Recommender Systems
Zongwei Wang, Min Gao, Junliang Yu, Xinyi Gao, Quoc Viet Hung Nguyen, Shazia Sadiq, Hongzhi Yin
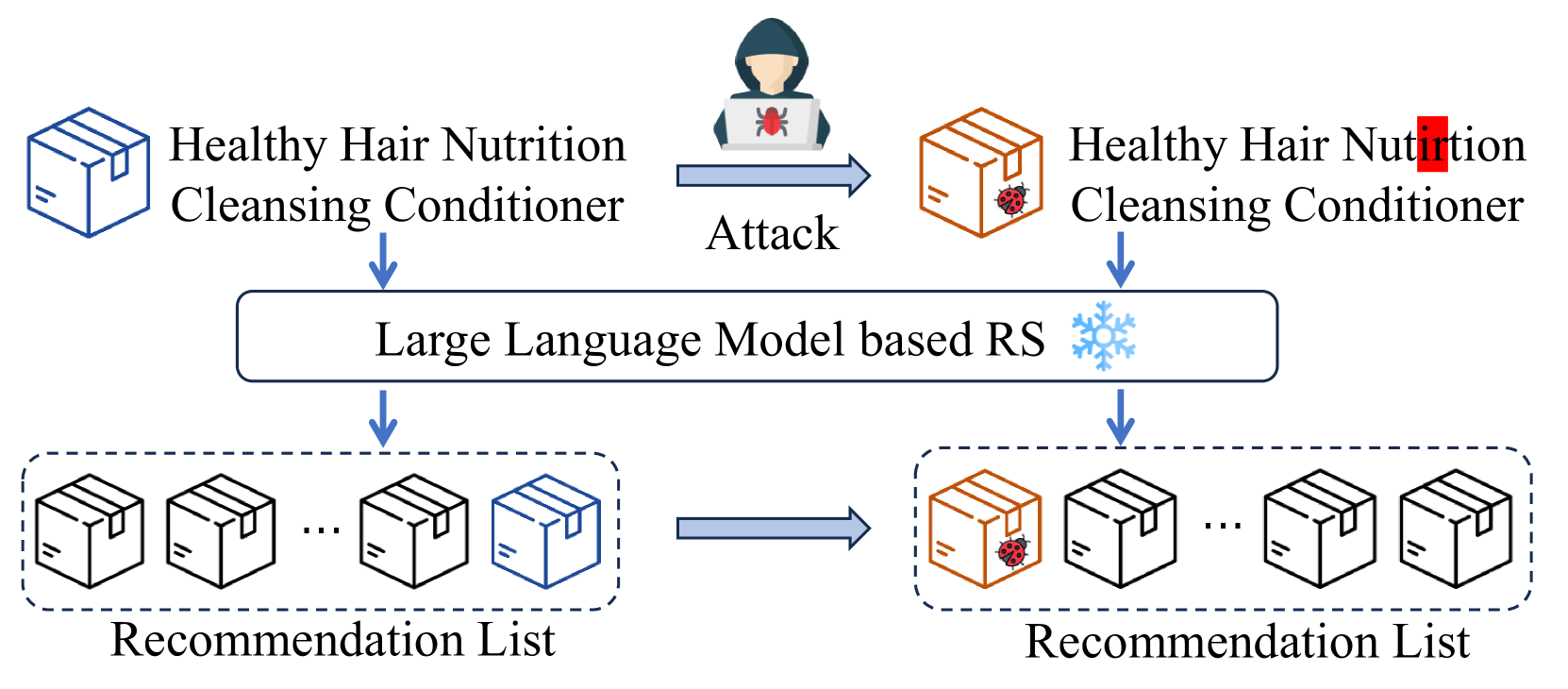
The ID-free recommendation paradigm has been proposed to address the limitation that traditional recommender systems struggle to model cold-start users or items with new IDs. Despite its effectiveness, this study uncovers that ID-free recommender systems are vulnerable to the proposed Text Simulation attack (TextSimu) which aims to promote specific target items. As a novel type of text poisoning attack, TextSimu exploits large language models (LLM) to alter the textual information of target items by simulating the characteristics of popular items. It operates effectively in both black-box and white-box settings, utilizing two key components: a unified popularity extraction module, which captures the essential characteristics of popular items, and an N-persona consistency simulation strategy, which creates multiple personas to collaboratively synthesize refined promotional textual descriptions for target items by simulating the popular items. To withstand TextSimu-like attacks, we further explore the detection approach for identifying LLM-generated promotional text. Extensive experiments conducted on three datasets demonstrate that TextSimu poses a more significant threat than existing poisoning attacks, while our defense method can detect malicious text of target items generated by TextSimu. By identifying the vulnerability, we aim to advance the development of more robust ID-free recommender systems.
Read more9/20/2024
0
Stealthy Attack on Large Language Model based Recommendation
Jinghao Zhang, Yuting Liu, Qiang Liu, Shu Wu, Guibing Guo, Liang Wang
Recently, the powerful large language models (LLMs) have been instrumental in propelling the progress of recommender systems (RS). However, while these systems have flourished, their susceptibility to security threats has been largely overlooked. In this work, we reveal that the introduction of LLMs into recommendation models presents new security vulnerabilities due to their emphasis on the textual content of items. We demonstrate that attackers can significantly boost an item's exposure by merely altering its textual content during the testing phase, without requiring direct interference with the model's training process. Additionally, the attack is notably stealthy, as it does not affect the overall recommendation performance and the modifications to the text are subtle, making it difficult for users and platforms to detect. Our comprehensive experiments across four mainstream LLM-based recommendation models demonstrate the superior efficacy and stealthiness of our approach. Our work unveils a significant security gap in LLM-based recommendation systems and paves the way for future research on protecting these systems.
Read more6/6/2024

0
Adversarial Text Rewriting for Text-aware Recommender Systems
Sejoon Oh, Gaurav Verma, Srijan Kumar
Text-aware recommender systems incorporate rich textual features, such as titles and descriptions, to generate item recommendations for users. The use of textual features helps mitigate cold-start problems, and thus, such recommender systems have attracted increased attention. However, we argue that the dependency on item descriptions makes the recommender system vulnerable to manipulation by adversarial sellers on e-commerce platforms. In this paper, we explore the possibility of such manipulation by proposing a new text rewriting framework to attack text-aware recommender systems. We show that the rewriting attack can be exploited by sellers to unfairly uprank their products, even though the adversarially rewritten descriptions are perceived as realistic by human evaluators. Methodologically, we investigate two different variations to carry out text rewriting attacks: (1) two-phase fine-tuning for greater attack performance, and (2) in-context learning for higher text rewriting quality. Experiments spanning 3 different datasets and 4 existing approaches demonstrate that recommender systems exhibit vulnerability against the proposed text rewriting attack. Our work adds to the existing literature around the robustness of recommender systems, while highlighting a new dimension of vulnerability in the age of large-scale automated text generation.
Read more8/2/2024

0
IDGenRec: LLM-RecSys Alignment with Textual ID Learning
Juntao Tan, Shuyuan Xu, Wenyue Hua, Yingqiang Ge, Zelong Li, Yongfeng Zhang
Generative recommendation based on Large Language Models (LLMs) have transformed the traditional ranking-based recommendation style into a text-to-text generation paradigm. However, in contrast to standard NLP tasks that inherently operate on human vocabulary, current research in generative recommendations struggles to effectively encode recommendation items within the text-to-text framework using concise yet meaningful ID representations. To better align LLMs with recommendation needs, we propose IDGen, representing each item as a unique, concise, semantically rich, platform-agnostic textual ID using human language tokens. This is achieved by training a textual ID generator alongside the LLM-based recommender, enabling seamless integration of personalized recommendations into natural language generation. Notably, as user history is expressed in natural language and decoupled from the original dataset, our approach suggests the potential for a foundational generative recommendation model. Experiments show that our framework consistently surpasses existing models in sequential recommendation under standard experimental setting. Then, we explore the possibility of training a foundation recommendation model with the proposed method on data collected from 19 different datasets and tested its recommendation performance on 6 unseen datasets across different platforms under a completely zero-shot setting. The results show that the zero-shot performance of the pre-trained foundation model is comparable to or even better than some traditional recommendation models based on supervised training, showing the potential of the IDGen paradigm serving as the foundation model for generative recommendation. Code and data are open-sourced at https://github.com/agiresearch/IDGenRec.
Read more5/20/2024