Adversarial Text Rewriting for Text-aware Recommender Systems

0

Sign in to get full access
Overview
- This paper presents a novel adversarial text rewriting attack that can evade text-aware recommender systems.
- The attack leverages large language models to generate semantically similar yet adversarial text that can mislead the recommender system.
- The proposed approach demonstrates the vulnerability of current text-aware recommender systems and highlights the need for improved model robustness.
Plain English Explanation
Recommender systems are algorithms that suggest products, content, or services to users based on their preferences and behaviors. Some of these systems use the actual text of user reviews, descriptions, or other content to inform their recommendations. This can make them more accurate, but it also makes them vulnerable to a new type of attack.
The researchers in this paper developed a way to trick these text-aware recommender systems. By using large language models, they can automatically generate text that is very similar to the original, but with small changes that cause the recommender system to make different recommendations. This is an "adversarial attack" - the generated text is designed specifically to fool the system.
The key insight is that the language models can produce text that is semantically similar (meaning it conveys the same ideas) but with subtle differences that change how the recommender system perceives the content. This highlights a weakness in current recommender systems - they can be misled by small changes to the text they analyze.
The researchers show that this attack can be effective, demonstrating the need for recommender systems to become more robust and resistant to this type of manipulation. Improving the reliability and security of these systems is an important challenge as they become more widely used.
Technical Explanation
The paper introduces a novel adversarial text rewriting attack that targets text-aware recommender systems. The core idea is to leverage large language models to generate semantically similar yet adversarial text that can effectively mislead the recommender system.
The proposed attack framework consists of two key components:
-
Text Rewriting Module: This module uses a pre-trained language model to generate adversarial text that is semantically similar to the original input but with subtle differences. The goal is to produce text that will be perceived differently by the target recommender system.
-
Recommender Oriented Optimization: The generated adversarial text is further optimized to minimize the desired recommendation score, effectively causing the recommender system to make different suggestions.
The authors evaluate their approach on real-world datasets and demonstrate its effectiveness against various text-aware recommender models. The results show that the proposed attack can significantly degrade the performance of the target recommender systems, highlighting their vulnerability to this type of adversarial text manipulation.
Critical Analysis
The paper provides a thorough investigation of the proposed adversarial text rewriting attack and its impact on text-aware recommender systems. However, the authors acknowledge several limitations and areas for further research:
- The attack assumes white-box access to the target recommender system, which may not always be the case in real-world deployments.
- The evaluation is limited to certain types of recommender models and datasets, and the generalizability of the results to other domains and architectures is unclear.
- The paper does not address potential countermeasures or defense mechanisms that could be developed to mitigate this attack.
- The long-term societal implications of such adversarial attacks on recommender systems, such as the potential for manipulation and the spread of misinformation, are not fully explored.
Further research is needed to address these limitations and explore more robust and secure approaches to building text-aware recommender systems that are resilient to adversarial attacks.
Conclusion
This paper presents a novel adversarial text rewriting attack that can effectively mislead text-aware recommender systems. By leveraging large language models to generate semantically similar yet adversarial text, the proposed approach demonstrates the vulnerability of current recommender systems to this type of attack.
The findings highlight the importance of developing more robust and secure text-aware recommender systems that can withstand such adversarial manipulations. As these systems become more prevalent in various applications, ensuring their reliability and trustworthiness is crucial to prevent potential misuse and negative societal impacts.
The research in this paper contributes to the ongoing efforts to improve the security and resilience of AI-powered recommendation systems, which are increasingly shaping the information and content that users are exposed to. Continued advancements in this area will be essential for building more trustworthy and responsible AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adversarial Text Rewriting for Text-aware Recommender Systems
Sejoon Oh, Gaurav Verma, Srijan Kumar
Text-aware recommender systems incorporate rich textual features, such as titles and descriptions, to generate item recommendations for users. The use of textual features helps mitigate cold-start problems, and thus, such recommender systems have attracted increased attention. However, we argue that the dependency on item descriptions makes the recommender system vulnerable to manipulation by adversarial sellers on e-commerce platforms. In this paper, we explore the possibility of such manipulation by proposing a new text rewriting framework to attack text-aware recommender systems. We show that the rewriting attack can be exploited by sellers to unfairly uprank their products, even though the adversarially rewritten descriptions are perceived as realistic by human evaluators. Methodologically, we investigate two different variations to carry out text rewriting attacks: (1) two-phase fine-tuning for greater attack performance, and (2) in-context learning for higher text rewriting quality. Experiments spanning 3 different datasets and 4 existing approaches demonstrate that recommender systems exhibit vulnerability against the proposed text rewriting attack. Our work adds to the existing literature around the robustness of recommender systems, while highlighting a new dimension of vulnerability in the age of large-scale automated text generation.
Read more8/2/2024
0
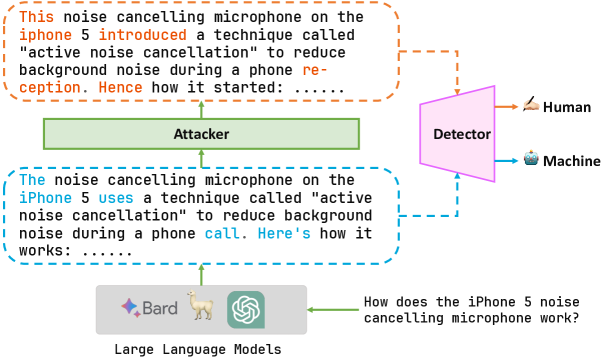
Humanizing Machine-Generated Content: Evading AI-Text Detection through Adversarial Attack
Ying Zhou, Ben He, Le Sun
With the development of large language models (LLMs), detecting whether text is generated by a machine becomes increasingly challenging in the face of malicious use cases like the spread of false information, protection of intellectual property, and prevention of academic plagiarism. While well-trained text detectors have demonstrated promising performance on unseen test data, recent research suggests that these detectors have vulnerabilities when dealing with adversarial attacks such as paraphrasing. In this paper, we propose a framework for a broader class of adversarial attacks, designed to perform minor perturbations in machine-generated content to evade detection. We consider two attack settings: white-box and black-box, and employ adversarial learning in dynamic scenarios to assess the potential enhancement of the current detection model's robustness against such attacks. The empirical results reveal that the current detection models can be compromised in as little as 10 seconds, leading to the misclassification of machine-generated text as human-written content. Furthermore, we explore the prospect of improving the model's robustness over iterative adversarial learning. Although some improvements in model robustness are observed, practical applications still face significant challenges. These findings shed light on the future development of AI-text detectors, emphasizing the need for more accurate and robust detection methods.
Read more4/3/2024
🔮
0
Semantic Stealth: Adversarial Text Attacks on NLP Using Several Methods
Roopkatha Dey, Aivy Debnath, Sayak Kumar Dutta, Kaustav Ghosh, Arijit Mitra, Arghya Roy Chowdhury, Jaydip Sen
In various real-world applications such as machine translation, sentiment analysis, and question answering, a pivotal role is played by NLP models, facilitating efficient communication and decision-making processes in domains ranging from healthcare to finance. However, a significant challenge is posed to the robustness of these natural language processing models by text adversarial attacks. These attacks involve the deliberate manipulation of input text to mislead the predictions of the model while maintaining human interpretability. Despite the remarkable performance achieved by state-of-the-art models like BERT in various natural language processing tasks, they are found to remain vulnerable to adversarial perturbations in the input text. In addressing the vulnerability of text classifiers to adversarial attacks, three distinct attack mechanisms are explored in this paper using the victim model BERT: BERT-on-BERT attack, PWWS attack, and Fraud Bargain's Attack (FBA). Leveraging the IMDB, AG News, and SST2 datasets, a thorough comparative analysis is conducted to assess the effectiveness of these attacks on the BERT classifier model. It is revealed by the analysis that PWWS emerges as the most potent adversary, consistently outperforming other methods across multiple evaluation scenarios, thereby emphasizing its efficacy in generating adversarial examples for text classification. Through comprehensive experimentation, the performance of these attacks is assessed and the findings indicate that the PWWS attack outperforms others, demonstrating lower runtime, higher accuracy, and favorable semantic similarity scores. The key insight of this paper lies in the assessment of the relative performances of three prevalent state-of-the-art attack mechanisms.
Read more4/9/2024
✅
0
Text-CRS: A Generalized Certified Robustness Framework against Textual Adversarial Attacks
Xinyu Zhang, Hanbin Hong, Yuan Hong, Peng Huang, Binghui Wang, Zhongjie Ba, Kui Ren
The language models, especially the basic text classification models, have been shown to be susceptible to textual adversarial attacks such as synonym substitution and word insertion attacks. To defend against such attacks, a growing body of research has been devoted to improving the model robustness. However, providing provable robustness guarantees instead of empirical robustness is still widely unexplored. In this paper, we propose Text-CRS, a generalized certified robustness framework for natural language processing (NLP) based on randomized smoothing. To our best knowledge, existing certified schemes for NLP can only certify the robustness against $ell_0$ perturbations in synonym substitution attacks. Representing each word-level adversarial operation (i.e., synonym substitution, word reordering, insertion, and deletion) as a combination of permutation and embedding transformation, we propose novel smoothing theorems to derive robustness bounds in both permutation and embedding space against such adversarial operations. To further improve certified accuracy and radius, we consider the numerical relationships between discrete words and select proper noise distributions for the randomized smoothing. Finally, we conduct substantial experiments on multiple language models and datasets. Text-CRS can address all four different word-level adversarial operations and achieve a significant accuracy improvement. We also provide the first benchmark on certified accuracy and radius of four word-level operations, besides outperforming the state-of-the-art certification against synonym substitution attacks.
Read more6/12/2024