LLM with Relation Classifier for Document-Level Relation Extraction

0

Sign in to get full access
Overview
- This paper presents a novel approach to document-level relation extraction using large language models (LLMs) and a relation classifier.
- The proposed method aims to improve upon existing techniques by leveraging the powerful language understanding capabilities of LLMs and a specialized relation classifier.
- The authors evaluate their model on several benchmark datasets and demonstrate its effectiveness in extracting complex relations from long-form text.
Plain English Explanation
In this paper, the researchers explore a new way to extract meaningful relationships between entities within a document. Extracting these document-level relations is an important task in natural language processing, with applications in areas like knowledge base construction and dialogue understanding.
The key innovation in this work is the use of a large language model (LLM) as the foundation, combined with a specialized relation classifier. LLMs are powerful AI models that can understand and generate human-like text. The authors leverage the LLM's strong language understanding capabilities to capture the nuanced relationships between entities in a document. The relation classifier is then used to identify and label the specific types of relations present.
This approach aims to improve upon previous techniques, which may have struggled with complex, long-form text. By combining the strengths of LLMs and a targeted relation classifier, the researchers hope to achieve better performance in extracting meaningful connections between entities at the document level.
Technical Explanation
The authors propose a LLM-based relation extraction model for document-level relation extraction. The key components of their approach are:
-
Large Language Model (LLM): The researchers use a pre-trained LLM, such as BERT or RoBERTa, as the foundation of their model. These LLMs are trained on vast amounts of text data and can effectively capture the semantic and syntactic nuances of language.
-
Relation Classifier: The authors augment the LLM with a specialized relation classifier. This component is responsible for identifying the specific types of relations between entities in the document.
-
Document-level Extraction: Unlike previous approaches that focused on sentence-level or paragraph-level relations, the proposed method operates at the document level. This allows the model to capture more complex and long-range dependencies between entities.
The authors evaluate their model on several benchmark datasets for document-level relation extraction and demonstrate its effectiveness in extracting a wide range of relations from complex, long-form text.
Critical Analysis
The paper presents a promising approach to document-level relation extraction, but it also acknowledges several limitations and potential areas for further research:
-
Dataset Bias: The authors note that the benchmark datasets used in their evaluation may suffer from dataset bias. This could limit the model's generalization to real-world scenarios.
-
Interpretability: While the LLM-based approach achieves strong performance, the inherent black-box nature of these models makes it challenging to understand the underlying reasoning behind their predictions.
-
Computational Complexity: The use of a large language model and a specialized relation classifier may incur significant computational overhead, which could limit the model's practical deployment in certain scenarios.
-
Handling Long-form Text: While the proposed method is designed to handle long-form text, the authors acknowledge that there may still be challenges in effectively capturing relations across very long documents.
Overall, the paper presents an innovative approach to document-level relation extraction that leverages the strengths of large language models and a targeted relation classifier. However, the researchers also identify areas for further improvement and investigation to enhance the model's robustness, interpretability, and efficiency.
Conclusion
This paper introduces a novel LLM-based relation extraction model for document-level relation extraction. By combining the powerful language understanding capabilities of large language models with a specialized relation classifier, the authors demonstrate the effectiveness of their approach in extracting complex relations from long-form text.
The research has important implications for various applications, such as knowledge base construction and dialogue understanding. While the paper identifies some limitations and areas for further investigation, the proposed method represents a significant advancement in the field of document-level relation extraction and could pave the way for more accurate and robust models in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLM with Relation Classifier for Document-Level Relation Extraction
Xingzuo Li, Kehai Chen, Yunfei Long, Min Zhang
Large language models (LLMs) create a new paradigm for natural language processing. Despite their advancement, LLM-based methods still lag behind traditional approaches in document-level relation extraction (DocRE), a critical task for understanding complex entity relations. This paper investigates the causes of this performance gap, identifying the dispersion of attention by LLMs due to entity pairs without relations as a primary factor. We then introduce a novel classifier-LLM approach to DocRE. The proposed approach begins with a classifier specifically designed to select entity pair candidates exhibiting potential relations and thereby feeds them to LLM for the final relation extraction. This method ensures that during inference, the LLM's focus is directed primarily at entity pairs with relations. Experiments on DocRE benchmarks reveal that our method significantly outperforms recent LLM-based DocRE models and achieves competitive performance with several leading traditional DocRE models.
Read more8/27/2024
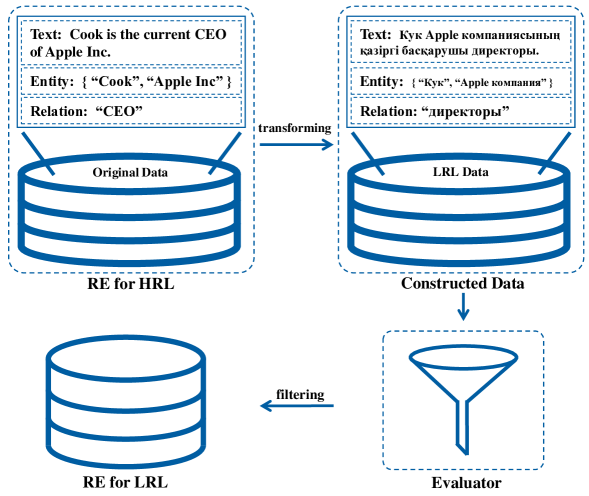
0
How Good are LLMs at Relation Extraction under Low-Resource Scenario? Comprehensive Evaluation
Dawulie Jinensibieke, Mieradilijiang Maimaiti, Wentao Xiao, Yuanhang Zheng, Xiaobo Wang
Relation Extraction (RE) serves as a crucial technology for transforming unstructured text into structured information, especially within the framework of Knowledge Graph development. Its importance is emphasized by its essential role in various downstream tasks. Besides the conventional RE methods which are based on neural networks and pre-trained language models, large language models (LLMs) are also utilized in the research field of RE. However, on low-resource languages (LRLs), both conventional RE methods and LLM-based methods perform poorly on RE due to the data scarcity issues. To this end, this paper constructs low-resource relation extraction datasets in 10 LRLs in three regions (Central Asia, Southeast Asia and Middle East). The corpora are constructed by translating the original publicly available English RE datasets (NYT10, FewRel and CrossRE) using an effective multilingual machine translation. Then, we use the language perplexity (PPL) to filter out the low-quality data from the translated datasets. Finally, we conduct an empirical study and validate the performance of several open-source LLMs on these generated LRL RE datasets.
Read more6/27/2024
⛏️
0
AutoRE: Document-Level Relation Extraction with Large Language Models
Lilong Xue, Dan Zhang, Yuxiao Dong, Jie Tang
Large Language Models (LLMs) have demonstrated exceptional abilities in comprehending and generating text, motivating numerous researchers to utilize them for Information Extraction (IE) purposes, including Relation Extraction (RE). Nonetheless, most existing methods are predominantly designed for Sentence-level Relation Extraction (SentRE) tasks, which typically encompass a restricted set of relations and triplet facts within a single sentence. Furthermore, certain approaches resort to treating relations as candidate choices integrated into prompt templates, leading to inefficient processing and suboptimal performance when tackling Document-Level Relation Extraction (DocRE) tasks, which entail handling multiple relations and triplet facts distributed across a given document, posing distinct challenges. To overcome these limitations, we introduce AutoRE, an end-to-end DocRE model that adopts a novel RE extraction paradigm named RHF (Relation-Head-Facts). Unlike existing approaches, AutoRE does not rely on the assumption of known relation options, making it more reflective of real-world scenarios. Additionally, we have developed an easily extensible RE framework using a Parameters Efficient Fine Tuning (PEFT) algorithm (QLoRA). Our experiments on the RE-DocRED dataset showcase AutoRE's best performance, achieving state-of-the-art results, surpassing TAG by 10.03% and 9.03% respectively on the dev and test set. The code is available at https://github.com/THUDM/AutoRE and the demonstration video is provided at https://www.youtube.com/watch?v=IhKRsZUAxKk.
Read more7/29/2024

0
Empirical Analysis of Dialogue Relation Extraction with Large Language Models
Guozheng Li, Zijie Xu, Ziyu Shang, Jiajun Liu, Ke Ji, Yikai Guo
Dialogue relation extraction (DRE) aims to extract relations between two arguments within a dialogue, which is more challenging than standard RE due to the higher person pronoun frequency and lower information density in dialogues. However, existing DRE methods still suffer from two serious issues: (1) hard to capture long and sparse multi-turn information, and (2) struggle to extract golden relations based on partial dialogues, which motivates us to discover more effective methods that can alleviate the above issues. We notice that the rise of large language models (LLMs) has sparked considerable interest in evaluating their performance across diverse tasks. To this end, we initially investigate the capabilities of different LLMs in DRE, considering both proprietary models and open-source models. Interestingly, we discover that LLMs significantly alleviate two issues in existing DRE methods. Generally, we have following findings: (1) scaling up model size substantially boosts the overall DRE performance and achieves exceptional results, tackling the difficulty of capturing long and sparse multi-turn information; (2) LLMs encounter with much smaller performance drop from entire dialogue setting to partial dialogue setting compared to existing methods; (3) LLMs deliver competitive or superior performances under both full-shot and few-shot settings compared to current state-of-the-art; (4) LLMs show modest performances on inverse relations but much stronger improvements on general relations, and they can handle dialogues of various lengths especially for longer sequences.
Read more4/30/2024