LLM-wrapper: Black-Box Semantic-Aware Adaptation of Vision-Language Foundation Models

0

Sign in to get full access
Overview
- The paper introduces "LLM-wrapper", a method for adapting Vision-Language (VL) foundation models to new tasks in a black-box fashion.
- LLM-wrapper leverages large language models (LLMs) to provide semantic-aware adaptation, without modifying the underlying VL model.
- The approach aims to enhance the performance of VL models on new tasks, without requiring access to the model's internals.
Plain English Explanation
The paper presents a new technique called LLM-wrapper that can improve the performance of Vision-Language (VL) models on new tasks. VL models are machine learning systems that can understand and process both visual and textual information.
The key idea behind LLM-wrapper is to use a large language model (LLM) to adapt the VL model to new tasks, without actually modifying the VL model itself. This is called "black-box" adaptation, because the LLM-wrapper can work with the VL model as a "black box" - it doesn't need to access or change the VL model's internal workings.
The LLM-wrapper leverages the semantic understanding of the LLM to guide the adaptation process. This "semantic-aware" adaptation helps the VL model perform better on new tasks, compared to simply fine-tuning the VL model directly.
The key advantage of this approach is that it allows users to enhance the performance of VL models without needing to know the details of how the VL model was built or trained. This makes it more accessible and usable for a wider range of applications and users.
Technical Explanation
The paper introduces a novel method called LLM-wrapper for adapting Vision-Language (VL) foundation models to new tasks in a "black-box" fashion. The key idea is to leverage a large language model (LLM) to provide semantic-aware adaptation, without modifying the underlying VL model.
The LLM-wrapper architecture consists of three main components:
- VL Foundation Model: The pre-trained VL model that needs to be adapted to a new task.
- LLM Prompt Encoder: A module that encodes the task-specific prompts and instructions into a semantic representation using an LLM.
- Adapter: A lightweight neural network that takes the VL model's outputs and the LLM-encoded prompts, and produces the final task-specific outputs.
During adaptation, the LLM Prompt Encoder captures the semantic understanding of the task, which is then used by the Adapter to guide the VL model's outputs. This "semantic-aware" adaptation allows the VL model to perform better on the new task, compared to standard fine-tuning approaches.
The key advantage of this LLM-wrapper approach is that it enables black-box adaptation of VL models, without requiring access to the model's internal architecture or training details. This makes the technique more accessible and applicable to a wider range of VL models and use cases.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the LLM-wrapper approach, considering multiple VL models, tasks, and LLMs. The results demonstrate consistent performance improvements over standard fine-tuning, validating the effectiveness of the semantic-aware adaptation.
One potential limitation of the LLM-wrapper approach is that it relies on the availability and quality of the LLM used for prompt encoding. If the LLM has limited semantic understanding or is not well-suited for the specific task, the adaptation process may not be as effective. The authors acknowledge this and suggest further research on LLM selection and prompt engineering for optimal performance.
Additionally, the paper does not explore the computational and memory efficiency of the LLM-wrapper approach compared to other adaptation techniques. This is an important consideration, especially for deployment in resource-constrained environments.
Overall, the LLM-wrapper method represents a promising direction for enhancing the performance of VL models on new tasks in a black-box and semantically-aware manner. The proposed approach opens up new possibilities for making advanced VL capabilities more accessible and usable for a wider range of applications and users.
Conclusion
The paper introduces LLM-wrapper, a novel method for adapting Vision-Language (VL) foundation models to new tasks in a black-box and semantic-aware fashion. By leveraging large language models (LLMs) to capture task-specific semantics, the LLM-wrapper approach can enhance the performance of VL models without requiring access to their internal details.
This work represents an important step towards making advanced VL capabilities more accessible and usable for a wider range of applications and users. The LLM-wrapper approach provides a flexible and versatile way to adapt VL models to new tasks, potentially unlocking new possibilities in areas such as multimodal reasoning, visual understanding, and language-guided interaction.
The promising results and the black-box nature of the LLM-wrapper method suggest that this technique could have a significant impact on the field of Vision-Language AI, enabling more widespread adoption and application of these powerful models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLM-wrapper: Black-Box Semantic-Aware Adaptation of Vision-Language Foundation Models
Amaia Cardiel, Eloi Zablocki, Oriane Sim'eoni, Elias Ramzi, Matthieu Cord
Vision Language Models (VLMs) have shown impressive performances on numerous tasks but their zero-shot capabilities can be limited compared to dedicated or fine-tuned models. Yet, fine-tuning VLMs comes with limitations as it requires `white-box' access to the model's architecture and weights as well as expertise to design the fine-tuning objectives and optimize the hyper-parameters, which are specific to each VLM and downstream task. In this work, we propose LLM-wrapper, a novel approach to adapt VLMs in a `black-box' manner by leveraging large language models (LLMs) so as to reason on their outputs. We demonstrate the effectiveness of LLM-wrapper on Referring Expression Comprehension (REC), a challenging open-vocabulary task that requires spatial and semantic reasoning. Our approach significantly boosts the performance of off-the-shelf models, resulting in competitive results when compared with classic fine-tuning.
Read more9/19/2024
💬
0
Language Models as Black-Box Optimizers for Vision-Language Models
Shihong Liu, Zhiqiu Lin, Samuel Yu, Ryan Lee, Tiffany Ling, Deepak Pathak, Deva Ramanan
Vision-language models (VLMs) pre-trained on web-scale datasets have demonstrated remarkable capabilities on downstream tasks when fine-tuned with minimal data. However, many VLMs rely on proprietary data and are not open-source, which restricts the use of white-box approaches for fine-tuning. As such, we aim to develop a black-box approach to optimize VLMs through natural language prompts, thereby avoiding the need to access model parameters, feature embeddings, or even output logits. We propose employing chat-based LLMs to search for the best text prompt for VLMs. Specifically, we adopt an automatic hill-climbing procedure that converges to an effective prompt by evaluating the performance of current prompts and asking LLMs to refine them based on textual feedback, all within a conversational process without human-in-the-loop. In a challenging 1-shot image classification setup, our simple approach surpasses the white-box continuous prompting method (CoOp) by an average of 1.5% across 11 datasets including ImageNet. Our approach also outperforms both human-engineered and LLM-generated prompts. We highlight the advantage of conversational feedback that incorporates both positive and negative prompts, suggesting that LLMs can utilize the implicit gradient direction in textual feedback for a more efficient search. In addition, we find that the text prompts generated through our strategy are not only more interpretable but also transfer well across different VLM architectures in a black-box manner. Lastly, we apply our framework to optimize the state-of-the-art black-box VLM (DALL-E 3) for text-to-image generation, prompt inversion, and personalization.
Read more5/15/2024
📈
0
Enhancing Model Performance: Another Approach to Vision-Language Instruction Tuning
Vedanshu, MM Tripathi, Bhavnesh Jaint
The integration of large language models (LLMs) with vision-language (VL) tasks has been a transformative development in the realm of artificial intelligence, highlighting the potential of LLMs as a versatile general-purpose chatbot. However, the current trend in this evolution focuses on the integration of vision and language to create models that can operate in more diverse and real-world contexts. We present a novel approach, termed Bottleneck Adapter, specifically crafted for enhancing the multimodal functionalities of these complex models, enabling joint optimization of the entire multimodal LLM framework through a process known as Multimodal Model Tuning (MMT). Our approach utilizes lightweight adapters to connect the image encoder and LLM without the need for large, complex neural networks. Unlike the conventional modular training schemes, our approach adopts an end-to-end optimization regime, which, when combined with the adapters, facilitates the joint optimization using a significantly smaller parameter set. Our method exhibits robust performance with 90.12% accuracy, outperforming both human-level performance (88.4%) and LaVIN-7B (89.41%).
Read more7/26/2024
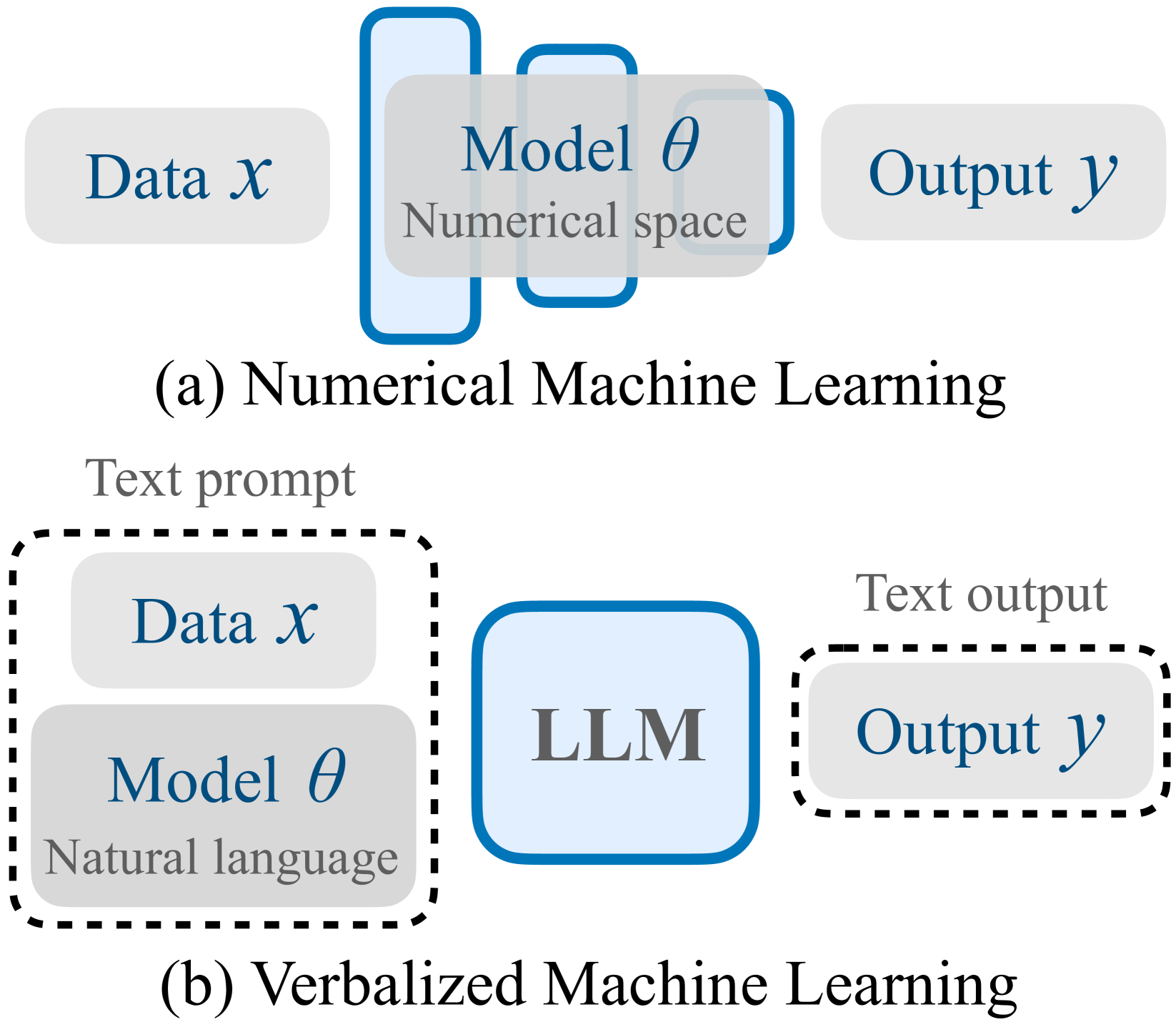
0
Verbalized Machine Learning: Revisiting Machine Learning with Language Models
Tim Z. Xiao, Robert Bamler, Bernhard Scholkopf, Weiyang Liu
Motivated by the large progress made by large language models (LLMs), we introduce the framework of verbalized machine learning (VML). In contrast to conventional machine learning models that are typically optimized over a continuous parameter space, VML constrains the parameter space to be human-interpretable natural language. Such a constraint leads to a new perspective of function approximation, where an LLM with a text prompt can be viewed as a function parameterized by the text prompt. Guided by this perspective, we revisit classical machine learning problems, such as regression and classification, and find that these problems can be solved by an LLM-parameterized learner and optimizer. The major advantages of VML include (1) easy encoding of inductive bias: prior knowledge about the problem and hypothesis class can be encoded in natural language and fed into the LLM-parameterized learner; (2) automatic model class selection: the optimizer can automatically select a concrete model class based on data and verbalized prior knowledge, and it can update the model class during training; and (3) interpretable learner updates: the LLM-parameterized optimizer can provide explanations for why each learner update is performed. We conduct several studies to empirically evaluate the effectiveness of VML, and hope that VML can serve as a stepping stone to stronger interpretability and trustworthiness in ML.
Read more6/7/2024