Best Practices and Lessons Learned on Synthetic Data for Language Models
2404.07503
0
0

Abstract
The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs. Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. We emphasize the need for responsible use of synthetic data to build more powerful, inclusive, and trustworthy language models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper discusses best practices and lessons learned in using synthetic data for training language models.
- It covers topics such as the reasoning behind using synthetic data, techniques for generating and incorporating it, and potential pitfalls to avoid.
- The paper aims to provide guidance for researchers and practitioners working with synthetic data in the field of natural language processing.
Plain English Explanation
Synthetic data is artificial information that is computer-generated, rather than coming from real-world sources. Researchers are increasingly using synthetic data to train language models, which are AI systems that can understand and generate human-like text.
The paper explores the benefits and challenges of incorporating synthetic data into language model training. One key reason to use synthetic data is that it can help fill gaps in real-world datasets, which may be limited or biased. Generating synthetic satellite imagery with deep learning is an example of how synthetic data can be useful.
However, the paper also cautions that synthetic data must be used carefully. For instance, if the synthetic data is not representative of real-world language, it could actually degrade the model's performance. The paper discusses techniques like iterative retraining of generative models to help ensure the synthetic data is high-quality.
Overall, the paper aims to provide guidance on best practices for researchers looking to leverage synthetic data to improve their language models, while avoiding potential pitfalls.
Technical Explanation
The paper examines the use of synthetic data in training language models, a common approach in natural language processing (NLP) research. One key motivation for using synthetic data is to address the limitations of real-world datasets, which may be biased, incomplete, or difficult to obtain. Experiments on how bad synthetic data can be for training provide insight into the potential trade-offs.
The paper discusses various techniques for generating and incorporating synthetic data, such as using deep learning to create synthetic satellite imagery that can supplement real-world datasets. It also explores potential pitfalls, such as the risk of the synthetic data diverging too far from real-world language patterns, which could undermine the model's performance.
To mitigate these risks, the paper recommends strategies like iterative retraining of generative models to ensure the synthetic data remains representative and high-quality. It also discusses the importance of carefully evaluating the synthetic data's impact on model performance, rather than simply assuming more data is better.
Critical Analysis
The paper provides a comprehensive overview of the current state of research on using synthetic data for language models, highlighting both the potential benefits and the challenges that researchers must navigate.
One limitation noted in the paper is the difficulty of ensuring the synthetic data is truly representative of real-world language patterns. While techniques like iterative retraining can help, there is always a risk of the synthetic data diverging from reality in ways that could undermine the model's performance. Investigations into the usefulness of synthetic images for transfer learning suggest this is a common issue that must be carefully managed.
Additionally, the paper does not delve deeply into the ethical considerations of using synthetic data, such as the potential for amplifying biases or creating "fake" language that could be used for malicious purposes. As the use of synthetic data becomes more widespread, it will be important for the research community to grapple with these larger societal implications.
Overall, the paper provides a valuable resource for researchers working with synthetic data in NLP, but there is still room for further exploration and refinement of best practices in this rapidly evolving field.
Conclusion
This paper offers a comprehensive look at the use of synthetic data in training language models, providing both practical guidance and critical analysis. It highlights the potential benefits of using synthetic data to address limitations in real-world datasets, as well as the importance of carefully managing the quality and representativeness of the synthetic data to avoid degrading model performance.
The insights and recommendations presented in this paper can serve as a valuable resource for researchers and practitioners working to leverage synthetic data to advance the field of natural language processing. By following the best practices outlined in the paper and remaining vigilant about potential pitfalls, the NLP community can continue to harness the power of synthetic data to drive innovation and improve the capabilities of language models.
Related Papers
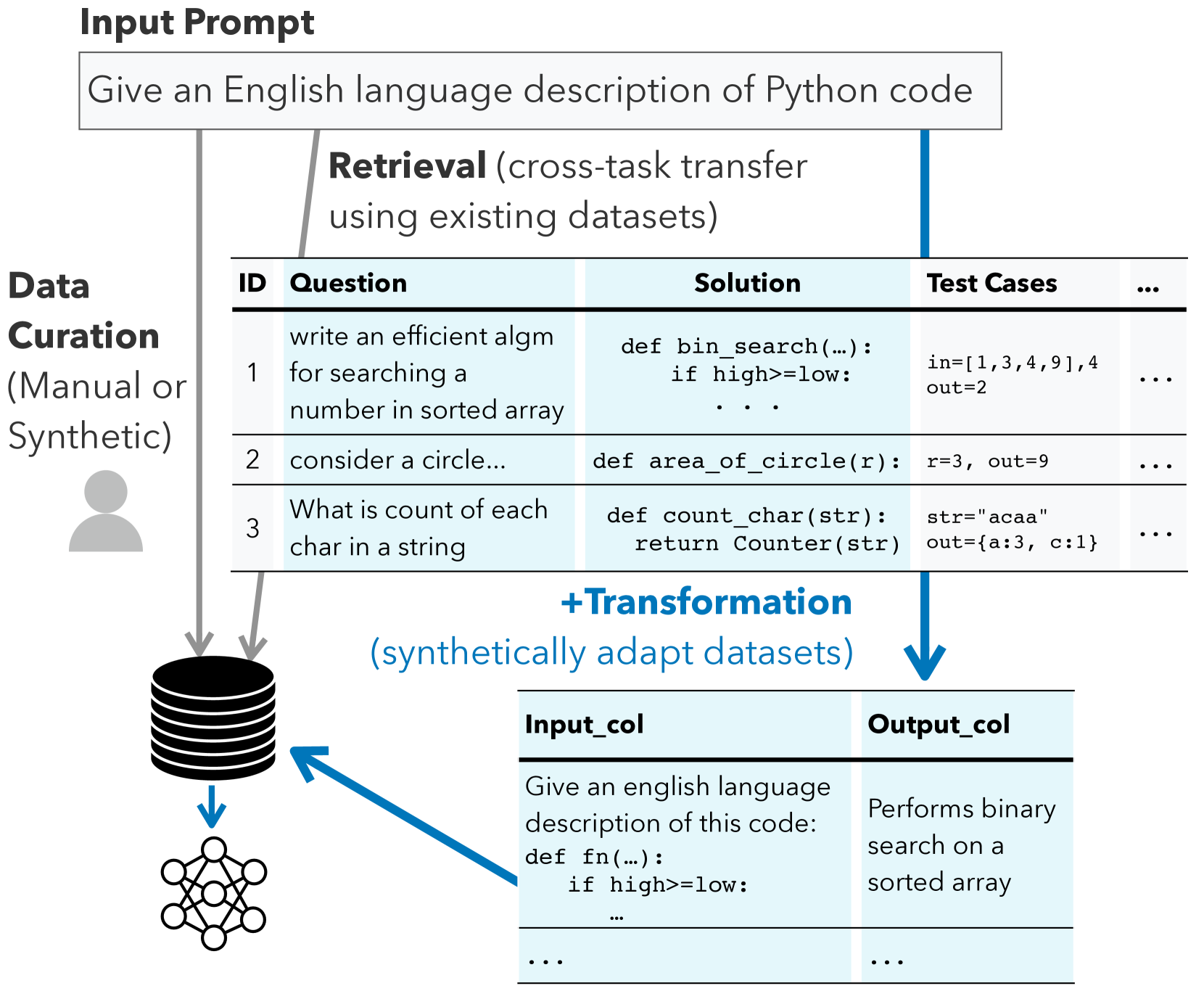
Better Synthetic Data by Retrieving and Transforming Existing Datasets
Saumya Gandhi, Ritu Gala, Vijay Viswanathan, Tongshuang Wu, Graham Neubig
0
0
Despite recent advances in large language models, building dependable and deployable NLP models typically requires abundant, high-quality training data. However, task-specific data is not available for many use cases, and manually curating task-specific data is labor-intensive. Recent work has studied prompt-driven synthetic data generation using large language models, but these generated datasets tend to lack complexity and diversity. To address these limitations, we introduce a method, DataTune, to make better use of existing, publicly available datasets to improve automatic dataset generation. DataTune performs dataset transformation, enabling the repurposing of publicly available datasets into a format that is directly aligned with the specific requirements of target tasks. On a diverse set of language-based tasks from the BIG-Bench benchmark, we find that finetuning language models via DataTune improves over a few-shot prompting baseline by 49% and improves over existing methods that use synthetic or retrieved training data by 34%. We find that dataset transformation significantly increases the diversity and difficulty of generated data on many tasks. We integrate DataTune into an open-source repository to make this method accessible to the community: https://github.com/neulab/prompt2model.
4/30/2024
🏅
Real Risks of Fake Data: Synthetic Data, Diversity-Washing and Consent Circumvention
Cedric Deslandes Whitney, Justin Norman
0
0
Machine learning systems require representations of the real world for training and testing - they require data, and lots of it. Collecting data at scale has logistical and ethical challenges, and synthetic data promises a solution to these challenges. Instead of needing to collect photos of real people's faces to train a facial recognition system, a model creator could create and use photo-realistic, synthetic faces. The comparative ease of generating this synthetic data rather than relying on collecting data has made it a common practice. We present two key risks of using synthetic data in model development. First, we detail the high risk of false confidence when using synthetic data to increase dataset diversity and representation. We base this in the examination of a real world use-case of synthetic data, where synthetic datasets were generated for an evaluation of facial recognition technology. Second, we examine how using synthetic data risks circumventing consent for data usage. We illustrate this by considering the importance of consent to the U.S. Federal Trade Commission's regulation of data collection and affected models. Finally, we discuss how these two risks exemplify how synthetic data complicates existing governance and ethical practice; by decoupling data from those it impacts, synthetic data is prone to consolidating power away those most impacted by algorithmically-mediated harm.
5/6/2024
🏋️
The Curious Decline of Linguistic Diversity: Training Language Models on Synthetic Text
Yanzhu Guo, Guokan Shang, Michalis Vazirgiannis, Chlo'e Clavel
0
0
This study investigates the consequences of training language models on synthetic data generated by their predecessors, an increasingly prevalent practice given the prominence of powerful generative models. Diverging from the usual emphasis on performance metrics, we focus on the impact of this training methodology on linguistic diversity, especially when conducted recursively over time. To assess this, we adapt and develop a set of novel metrics targeting lexical, syntactic, and semantic diversity, applying them in recursive finetuning experiments across various natural language generation tasks in English. Our findings reveal a consistent decrease in the diversity of the model outputs through successive iterations, especially remarkable for tasks demanding high levels of creativity. This trend underscores the potential risks of training language models on synthetic text, particularly concerning the preservation of linguistic richness. Our study highlights the need for careful consideration of the long-term effects of such training approaches on the linguistic capabilities of language models.
4/17/2024
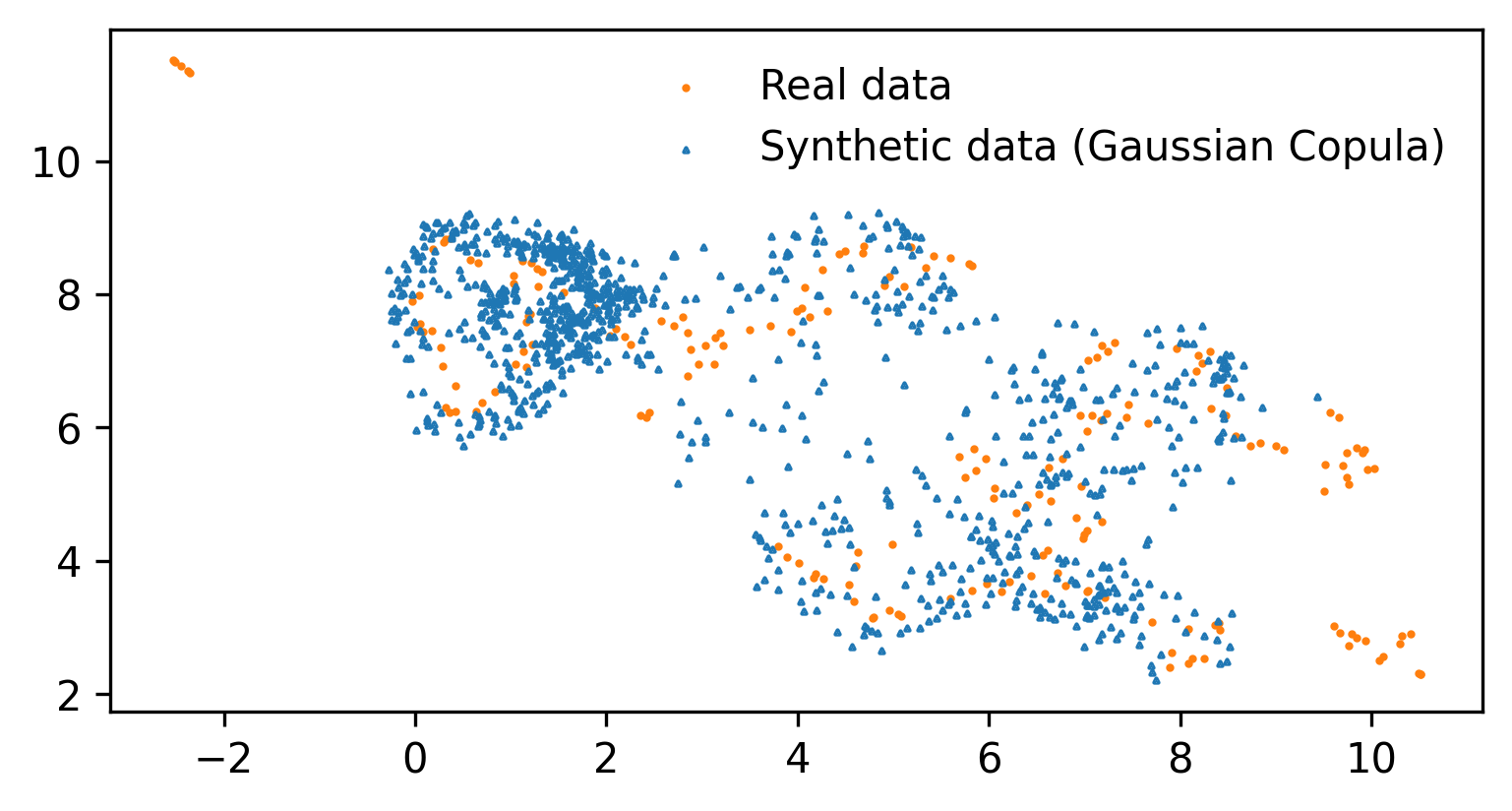
An evaluation framework for synthetic data generation models
Ioannis E. Livieris, Nikos Alimpertis, George Domalis, Dimitris Tsakalidis
0
0
Nowadays, the use of synthetic data has gained popularity as a cost-efficient strategy for enhancing data augmentation for improving machine learning models performance as well as addressing concerns related to sensitive data privacy. Therefore, the necessity of ensuring quality of generated synthetic data, in terms of accurate representation of real data, consists of primary importance. In this work, we present a new framework for evaluating synthetic data generation models' ability for developing high-quality synthetic data. The proposed approach is able to provide strong statistical and theoretical information about the evaluation framework and the compared models' ranking. Two use case scenarios demonstrate the applicability of the proposed framework for evaluating the ability of synthetic data generation models to generated high quality data. The implementation code can be found in https://github.com/novelcore/synthetic_data_evaluation_framework.
4/16/2024