Are LLMs Naturally Good at Synthetic Tabular Data Generation?

1
Sign in to get full access
Overview
• This paper explores whether large language models (LLMs) are naturally adept at generating synthetic tabular data, which is important for data augmentation and privacy-preserving data sharing. • The authors highlight the challenges that current LLM architectures face in effectively generating synthetic tabular data, which requires understanding complex data distributions and relationships. • The paper suggests that specialized techniques and architectural changes may be necessary to enable LLMs to excel at this task.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown impressive capabilities in natural language processing, but generating high-quality synthetic tabular data is a different challenge. Tabular data, such as spreadsheets or databases, often contains complex relationships between columns and rows that are difficult for current LLMs to capture.
The authors of this paper argue that while LLMs can perform well on tabular data prediction tasks, generating entirely new, realistic-looking tabular data is a much harder problem. LLMs may struggle to understand the underlying data distributions and dependencies that are crucial for producing coherent and plausible synthetic tables.
The paper suggests that specialized techniques and architectural changes may be needed to enable LLMs to excel at synthetic tabular data generation, similar to how generative adversarial networks (GANs) have been used to improve the ability of LLMs to generate realistic images.
Technical Explanation
The paper examines the challenges that current LLM architectures face in effectively generating synthetic tabular data. The authors argue that while LLMs have shown impressive performance on tabular data prediction tasks, generating entirely new, realistic-looking tabular data is a much harder problem.
Tabular data often contains complex relationships between columns and rows, which can be difficult for LLMs to capture. The authors suggest that LLMs may struggle to understand the underlying data distributions and dependencies that are crucial for producing coherent and plausible synthetic tables.
The paper explores potential solutions, such as specialized techniques and architectural changes that could enable LLMs to excel at this task. The authors draw parallels to the development of generative adversarial networks (GANs) for image generation, which have been shown to improve the ability of LLMs to generate realistic visual outputs.
Critical Analysis
The paper raises important points about the limitations of current LLM architectures in the context of synthetic tabular data generation. The authors acknowledge that while LLMs have shown impressive capabilities in natural language processing and even some tabular data prediction tasks, generating high-quality synthetic tables remains a significant challenge.
One potential limitation of the research is that it does not provide a detailed analysis of the specific challenges and architectural shortcomings that hinder LLMs' ability to generate synthetic tabular data. The paper could have delved deeper into the underlying reasons for these limitations, such as the difficulty in modeling complex data distributions and relationships, or the lack of suitable architectural components for this task.
Additionally, the paper does not offer a comprehensive evaluation of potential solutions, such as the specialized techniques and architectural changes the authors suggest. While the parallels drawn to GAN-based approaches for image generation are intriguing, the paper could have provided more concrete examples or proposals for how such solutions could be implemented and evaluated for synthetic tabular data generation.
Overall, the paper raises an important and timely question about the limitations of current LLM architectures, and it suggests that further research and innovation may be necessary to enable LLMs to excel at synthetic tabular data generation, a task with significant practical applications in areas such as data augmentation and privacy-preserving data sharing.
Conclusion
This paper highlights the challenges that current large language models (LLMs) face in generating high-quality synthetic tabular data, a task that requires understanding complex data distributions and relationships. The authors argue that while LLMs have shown impressive capabilities in natural language processing and even some tabular data prediction tasks, generating entirely new, realistic-looking tables remains a significant challenge.
The paper suggests that specialized techniques and architectural changes may be necessary to enable LLMs to excel at this task, drawing parallels to the development of generative adversarial networks (GANs) for image generation. The research raises important questions about the limitations of current LLM architectures and the need for further innovation to unlock the full potential of these powerful language models in the context of synthetic data generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Are LLMs Naturally Good at Synthetic Tabular Data Generation?
Shengzhe Xu, Cho-Ting Lee, Mandar Sharma, Raquib Bin Yousuf, Nikhil Muralidhar, Naren Ramakrishnan
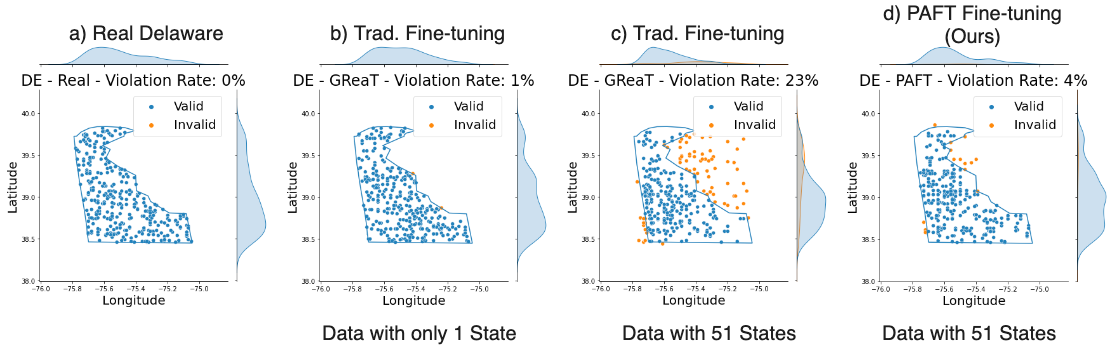
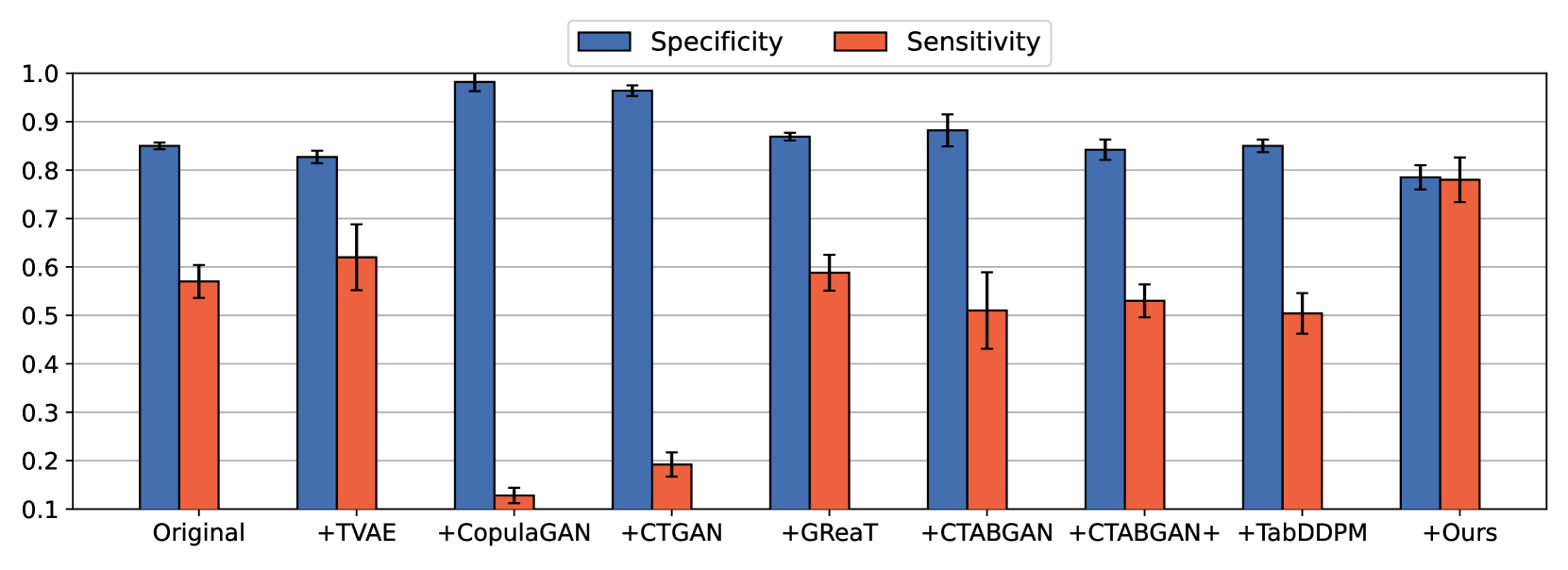
Large language models (LLMs) have demonstrated their prowess in generating synthetic text and images; however, their potential for generating tabular data -- arguably the most common data type in business and scientific applications -- is largely underexplored. This paper demonstrates that LLMs, used as-is, or after traditional fine-tuning, are severely inadequate as synthetic table generators. Due to the autoregressive nature of LLMs, fine-tuning with random order permutation runs counter to the importance of modeling functional dependencies, and renders LLMs unable to model conditional mixtures of distributions (key to capturing real world constraints). We showcase how LLMs can be made to overcome some of these deficiencies by making them permutation-aware.
Read more6/24/2024
0
Group-wise Prompting for Synthetic Tabular Data Generation using Large Language Models
Jinhee Kim, Taesung Kim, Jaegul Choo
Large language models (LLMs) have demonstrated impressive in-context learning capabilities across various domains. Inspired by this, our study explores the effectiveness of LLMs in generating realistic tabular data to mitigate class imbalance. We investigate and identify key prompt design elements such as data format, class presentation, and variable mapping to optimize the generation performance. Our findings indicate that using CSV format, balancing classes, and employing unique variable mapping produces realistic and reliable data, significantly enhancing machine learning performance for minor classes in imbalanced datasets. Additionally, these approaches improve the stability and efficiency of LLM data generation. We validate our approach using six real-world datasets and a toy dataset, achieving state-of-the-art performance in classification tasks. The code is available at: https://github.com/seharanul17/synthetic-tabular-LLM
Read more5/28/2024

0
Anomaly Detection of Tabular Data Using LLMs
Aodong Li, Yunhan Zhao, Chen Qiu, Marius Kloft, Padhraic Smyth, Maja Rudolph, Stephan Mandt
Large language models (LLMs) have shown their potential in long-context understanding and mathematical reasoning. In this paper, we study the problem of using LLMs to detect tabular anomalies and show that pre-trained LLMs are zero-shot batch-level anomaly detectors. That is, without extra distribution-specific model fitting, they can discover hidden outliers in a batch of data, demonstrating their ability to identify low-density data regions. For LLMs that are not well aligned with anomaly detection and frequently output factual errors, we apply simple yet effective data-generating processes to simulate synthetic batch-level anomaly detection datasets and propose an end-to-end fine-tuning strategy to bring out the potential of LLMs in detecting real anomalies. Experiments on a large anomaly detection benchmark (ODDS) showcase i) GPT-4 has on-par performance with the state-of-the-art transductive learning-based anomaly detection methods and ii) the efficacy of our synthetic dataset and fine-tuning strategy in aligning LLMs to this task.
Read more6/26/2024

1
Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey
Xi Fang, Weijie Xu, Fiona Anting Tan, Jiani Zhang, Ziqing Hu, Yanjun Qi, Scott Nickleach, Diego Socolinsky, Srinivasan Sengamedu, Christos Faloutsos
Recent breakthroughs in large language modeling have facilitated rigorous exploration of their application in diverse tasks related to tabular data modeling, such as prediction, tabular data synthesis, question answering, and table understanding. Each task presents unique challenges and opportunities. However, there is currently a lack of comprehensive review that summarizes and compares the key techniques, metrics, datasets, models, and optimization approaches in this research domain. This survey aims to address this gap by consolidating recent progress in these areas, offering a thorough survey and taxonomy of the datasets, metrics, and methodologies utilized. It identifies strengths, limitations, unexplored territories, and gaps in the existing literature, while providing some insights for future research directions in this vital and rapidly evolving field. It also provides relevant code and datasets references. Through this comprehensive review, we hope to provide interested readers with pertinent references and insightful perspectives, empowering them with the necessary tools and knowledge to effectively navigate and address the prevailing challenges in the field.
Read more6/26/2024