LLMs Will Always Hallucinate, and We Need to Live With This

194

Sign in to get full access
Overview
- Large language models (LLMs) are powerful AI systems that can generate human-like text, but they are prone to "hallucinations" - producing false or nonsensical information.
- Researchers argue that hallucination is an inherent limitation of LLMs and that we need to learn to live with and manage this issue rather than trying to eliminate it entirely.
- The paper explores the causes and characteristics of hallucination in LLMs, as well as strategies for detecting and mitigating its impact.
Plain English Explanation
Hallucination in Large Language Models
LLMs Will Always Hallucinate, and We Need to Live With This discusses the phenomenon of "hallucination" in large language models (LLMs) - the tendency of these AI systems to generate text that is factually incorrect or nonsensical, despite appearing plausible.
Causes of Hallucination LLMs are trained on vast amounts of online data, which can contain misinformation, biases, and inconsistencies. This leads the models to learn patterns that don't necessarily reflect reality. When generating new text, the models can then "hallucinate" - producing information that sounds convincing but is actually false or made up.
Characteristics of Hallucination Hallucinated text often appears coherent and fluent, but closer inspection reveals factual errors, logical inconsistencies, or a lack of grounding in reality. LLMs may confidently assert made-up facts or generate plausible-sounding but fictional content.
Accepting Hallucination The researchers argue that hallucination is an inherent limitation of LLMs and that we need to learn to live with and manage this issue, rather than trying to eliminate it entirely. Attempting to completely prevent hallucination may come at the cost of reducing the models' capabilities in other areas.
Strategies for Dealing with Hallucination
Detecting Hallucination Developing better techniques for automatically detecting hallucinated text, such as using fact-checking systems or analyzing the model's confidence levels, can help mitigate the impact of this issue.
Mitigating Hallucination Incorporating feedback loops, prompting users to verify information, and using multiple models to cross-check outputs are some strategies for reducing the influence of hallucinated content.
Accepting Limitations Ultimately, the researchers argue that we need to accept that LLMs will always have some degree of hallucination and focus on managing this limitation rather than trying to eliminate it entirely. This may involve being transparent about the models' capabilities and limitations, and developing applications that are designed to work within these constraints.
Technical Explanation
Causes of Hallucination in LLMs
The paper explains that LLMs are trained on large, diverse datasets from the internet, which can contain misinformation, biases, and inconsistencies. This leads the models to learn patterns that don't necessarily reflect reality. When generating new text, the models can then "hallucinate" - producing information that sounds convincing but is actually false or made up.
Characteristics of Hallucinated Text
The researchers found that hallucinated text often appears coherent and fluent, but closer inspection reveals factual errors, logical inconsistencies, or a lack of grounding in reality. LLMs may confidently assert made-up facts or generate plausible-sounding but fictional content.
Strategies for Detecting and Mitigating Hallucination
The paper discusses several approaches for dealing with hallucination in LLMs:
-
Detecting Hallucination: Developing better techniques for automatically detecting hallucinated text, such as using fact-checking systems or analyzing the model's confidence levels, can help mitigate the impact of this issue.
-
Mitigating Hallucination: Incorporating feedback loops, prompting users to verify information, and using multiple models to cross-check outputs are some strategies for reducing the influence of hallucinated content.
-
Accepting Limitations: The researchers argue that we need to accept that LLMs will always have some degree of hallucination and focus on managing this limitation rather than trying to eliminate it entirely. This may involve being transparent about the models' capabilities and limitations, and developing applications that are designed to work within these constraints.
Critical Analysis
The paper makes a compelling case that hallucination is an inherent limitation of LLMs that we must learn to live with and manage, rather than trying to eliminate entirely. The researchers provide a clear explanation of the causes and characteristics of hallucination, as well as practical strategies for detection and mitigation.
However, one potential issue not addressed in the paper is the ethical implications of relying on LLMs that are known to produce false or misleading information. While the researchers argue for transparency and managing expectations, there may be concerns around the use of these models in high-stakes applications, such as medical diagnosis or legal decision-making.
Additionally, the paper focuses primarily on textual hallucination, but LLMs are increasingly being used in multimodal tasks that involve generating images, video, and other media. The authors could have explored whether the hallucination problem extends to these other modalities and what additional challenges that might present.
Overall, the paper offers a well-reasoned and pragmatic approach to dealing with the limitations of LLMs, but further research may be needed to address the broader implications and challenges posed by hallucination in these powerful AI systems.
Conclusion
The paper "LLMs Will Always Hallucinate, and We Need to Live With This" argues that hallucination - the tendency of large language models (LLMs) to generate false or nonsensical information - is an inherent limitation of these AI systems that we must learn to live with and manage, rather than trying to eliminate entirely.
The researchers explain that LLMs' training on diverse online data, which can contain misinformation and biases, leads the models to learn patterns that don't necessarily reflect reality. When generating new text, the models can then "hallucinate" - producing information that sounds convincing but is actually factually incorrect or logically inconsistent.
While the paper discusses strategies for detecting and mitigating hallucination, such as using fact-checking systems and incorporating feedback loops, the researchers ultimately argue that we need to accept the limitations of LLMs and focus on developing applications and workflows that can operate effectively within these constraints. Transparency about the models' capabilities and limitations is key to managing the impact of hallucination.
This pragmatic approach to dealing with the inherent flaws of powerful AI systems like LLMs offers important lessons for the field of artificial intelligence as a whole. As these technologies continue to advance and become more widely adopted, understanding their limitations and developing appropriate safeguards and mitigation strategies will be crucial for ensuring their safe and responsible use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
194
LLMs Will Always Hallucinate, and We Need to Live With This
Sourav Banerjee, Ayushi Agarwal, Saloni Singla
As Large Language Models become more ubiquitous across domains, it becomes important to examine their inherent limitations critically. This work argues that hallucinations in language models are not just occasional errors but an inevitable feature of these systems. We demonstrate that hallucinations stem from the fundamental mathematical and logical structure of LLMs. It is, therefore, impossible to eliminate them through architectural improvements, dataset enhancements, or fact-checking mechanisms. Our analysis draws on computational theory and Godel's First Incompleteness Theorem, which references the undecidability of problems like the Halting, Emptiness, and Acceptance Problems. We demonstrate that every stage of the LLM process-from training data compilation to fact retrieval, intent classification, and text generation-will have a non-zero probability of producing hallucinations. This work introduces the concept of Structural Hallucination as an intrinsic nature of these systems. By establishing the mathematical certainty of hallucinations, we challenge the prevailing notion that they can be fully mitigated.
Read more9/10/2024
💬
0
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, Mike Zheng Shou
This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
Read more4/30/2024
1
Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models
Matthew Dahl, Varun Magesh, Mirac Suzgun, Daniel E. Ho
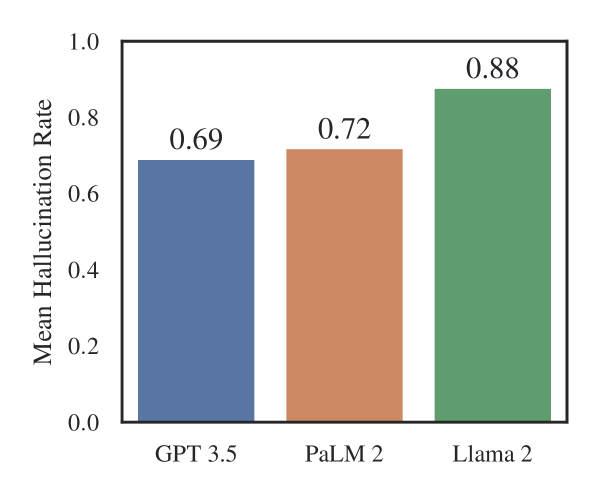
Do large language models (LLMs) know the law? These models are increasingly being used to augment legal practice, education, and research, yet their revolutionary potential is threatened by the presence of hallucinations -- textual output that is not consistent with legal facts. We present the first systematic evidence of these hallucinations, documenting LLMs' varying performance across jurisdictions, courts, time periods, and cases. Our work makes four key contributions. First, we develop a typology of legal hallucinations, providing a conceptual framework for future research in this area. Second, we find that legal hallucinations are alarmingly prevalent, occurring between 58% of the time with ChatGPT 4 and 88% with Llama 2, when these models are asked specific, verifiable questions about random federal court cases. Third, we illustrate that LLMs often fail to correct a user's incorrect legal assumptions in a contra-factual question setup. Fourth, we provide evidence that LLMs cannot always predict, or do not always know, when they are producing legal hallucinations. Taken together, our findings caution against the rapid and unsupervised integration of popular LLMs into legal tasks. Even experienced lawyers must remain wary of legal hallucinations, and the risks are highest for those who stand to benefit from LLMs the most -- pro se litigants or those without access to traditional legal resources.
Read more6/24/2024

0
A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
Read more5/7/2024