LLS: Local Learning Rule for Deep Neural Networks Inspired by Neural Activity Synchronization

0
🤿
Sign in to get full access
Background
Overview
- The paper introduces a new local learning rule called LLS (Local Learning by Synchronization) for training deep neural networks.
- LLS is inspired by the synchronization of neural activity observed in biological neural networks.
- The authors propose that LLS can enable efficient learning without the need for global backpropagation, which is computationally expensive and biologically implausible.
Plain English Explanation
The human brain is an incredibly complex and efficient computing system, and researchers are constantly trying to understand how it works in order to build better artificial intelligence (AI) systems. One of the key challenges in AI is how to train deep neural networks, which are inspired by the human brain, in a way that is both effective and biologically plausible.
The traditional approach to training deep neural networks is called backpropagation, which involves computing gradients at the output layer and then propagating them back through the network to update the weights. However, this process is computationally expensive and may not reflect how learning actually happens in the brain.
The paper introduces a new approach called LLS (Local Learning by Synchronization) that is inspired by the synchronization of neural activity observed in biological neural networks. The idea is that instead of using global backpropagation, the neurons in the network can learn by simply adjusting their weights based on the activity of their neighbors. This local learning process is more efficient and may be closer to how the brain actually learns.
The authors show that LLS can enable effective learning in deep neural networks without the need for global backpropagation, which is a significant step forward in making AI systems more biologically plausible and computationally efficient.
Technical Explanation
The paper proposes a new local learning rule called LLS (Local Learning by Synchronization) for training deep neural networks. LLS is inspired by the observation that neurons in biological neural networks tend to synchronize their activity, and the authors hypothesize that this synchronization plays a key role in learning.
In the LLS framework, each neuron in the network adjusts its weights based on the activity of its neighbors, rather than using the computationally expensive global backpropagation algorithm. Specifically, the authors introduce a local learning rule where each neuron tries to maximize the synchronization between its output and the outputs of its neighbors. This is achieved by updating the neuron's weights to increase the correlation between its output and the outputs of its neighbors.
The authors demonstrate the effectiveness of LLS on several benchmark tasks, including image classification and language modeling. They show that LLS can achieve competitive performance compared to traditional backpropagation-based methods, while being more computationally efficient and potentially more biologically plausible.
The authors also provide theoretical analysis to understand the properties of LLS, and they discuss how the local learning process can contribute to the emergence of features and representations that are similar to those observed in biological neural networks.
Critical Analysis
The LLS learning rule proposed in the paper is a promising approach to training deep neural networks in a more biologically plausible and computationally efficient manner. The authors provide a solid theoretical foundation and demonstrate the effectiveness of LLS on several benchmark tasks.
However, there are a few potential limitations and areas for further research:
-
Scalability: While LLS is shown to work well on the tested benchmarks, it remains to be seen how it would scale to larger and more complex neural network architectures, such as those used in state-of-the-art AI systems.
-
Biological Plausibility: The authors argue that LLS is more biologically plausible than backpropagation, but there is still much uncertainty about the precise mechanisms of learning in the brain. Further research is needed to better understand the connection between LLS and biological neural networks.
-
Generalization: The paper focuses on the performance of LLS on specific tasks, but more research is needed to understand how well the learned representations and features generalize to other domains and tasks.
-
Interpretability: While LLS may be more biologically plausible, it is important to consider the interpretability and explainability of the learned models, which is an important consideration in many real-world applications of AI.
Overall, the LLS learning rule is a promising step forward in the quest to develop more biologically plausible and computationally efficient deep learning algorithms. However, further research is needed to address the potential limitations and to fully understand the implications of this approach for the field of AI.
Conclusion
The paper introduces a new local learning rule called LLS (Local Learning by Synchronization) that is inspired by the synchronization of neural activity observed in biological neural networks. LLS enables effective learning in deep neural networks without the need for computationally expensive global backpropagation, which is a significant step forward in making AI systems more biologically plausible and efficient.
The authors demonstrate the effectiveness of LLS on several benchmark tasks and provide a solid theoretical foundation for understanding the properties of the learning rule. While there are some potential limitations and areas for further research, the LLS approach represents an important contribution to the ongoing efforts to develop more powerful and biologically inspired AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
LLS: Local Learning Rule for Deep Neural Networks Inspired by Neural Activity Synchronization
Marco Paul E. Apolinario, Arani Roy, Kaushik Roy
Training deep neural networks (DNNs) using traditional backpropagation (BP) presents challenges in terms of computational complexity and energy consumption, particularly for on-device learning where computational resources are limited. Various alternatives to BP, including random feedback alignment, forward-forward, and local classifiers, have been explored to address these challenges. These methods have their advantages, but they can encounter difficulties when dealing with intricate visual tasks or demand considerable computational resources. In this paper, we propose a novel Local Learning rule inspired by neural activity Synchronization phenomena (LLS) observed in the brain. LLS utilizes fixed periodic basis vectors to synchronize neuron activity within each layer, enabling efficient training without the need for additional trainable parameters. We demonstrate the effectiveness of LLS and its variations, LLS-M and LLS-MxM, on multiple image classification datasets, achieving accuracy comparable to BP with reduced computational complexity and minimal additional parameters. Furthermore, the performance of LLS on the Visual Wake Word (VWW) dataset highlights its suitability for on-device learning tasks, making it a promising candidate for edge hardware implementations.
Read more5/28/2024

0
Overcoming the Limitations of Layer Synchronization in Spiking Neural Networks
Roel Koopman, Amirreza Yousefzadeh, Mahyar Shahsavari, Guangzhi Tang, Manolis Sifalakis
Currently, neural-network processing in machine learning applications relies on layer synchronization, whereby neurons in a layer aggregate incoming currents from all neurons in the preceding layer, before evaluating their activation function. This is practiced even in artificial Spiking Neural Networks (SNNs), which are touted as consistent with neurobiology, in spite of processing in the brain being, in fact asynchronous. A truly asynchronous system however would allow all neurons to evaluate concurrently their threshold and emit spikes upon receiving any presynaptic current. Omitting layer synchronization is potentially beneficial, for latency and energy efficiency, but asynchronous execution of models previously trained with layer synchronization may entail a mismatch in network dynamics and performance. We present a study that documents and quantifies this problem in three datasets on our simulation environment that implements network asynchrony, and we show that models trained with layer synchronization either perform sub-optimally in absence of the synchronization, or they will fail to benefit from any energy and latency reduction, when such a mechanism is in place. We then make ends meet and address the problem with unlayered backprop, a novel backpropagation-based training method, for learning models suitable for asynchronous processing. We train with it models that use different neuron execution scheduling strategies, and we show that although their neurons are more reactive, these models consistently exhibit lower overall spike density (up to 50%), reach a correct decision faster (up to 2x) without integrating all spikes, and achieve superior accuracy (up to 10% higher). Our findings suggest that asynchronous event-based (neuromorphic) AI computing is indeed more efficient, but we need to seriously rethink how we train our SNN models, to benefit from it.
Read more8/12/2024
🧠
0
EchoSpike Predictive Plasticity: An Online Local Learning Rule for Spiking Neural Networks
Lars Graf, Zhe Su, Giacomo Indiveri
The drive to develop artificial neural networks that efficiently utilize resources has generated significant interest in bio-inspired Spiking Neural Networks (SNNs). These networks are particularly attractive due to their potential in applications requiring low power and memory. This potential is further enhanced by the ability to perform online local learning, enabling them to adapt to dynamic environments. This requires the model to be adaptive in a self-supervised manner. While self-supervised learning has seen great success in many deep learning domains, its application for online local learning in multi-layer SNNs remains underexplored. In this paper, we introduce the EchoSpike Predictive Plasticity (ESPP) learning rule, a pioneering online local learning rule designed to leverage hierarchical temporal dynamics in SNNs through predictive and contrastive coding. We validate the effectiveness of this approach using benchmark datasets, demonstrating that it performs on par with current state-of-the-art supervised learning rules. The temporal and spatial locality of ESPP makes it particularly well-suited for low-cost neuromorphic processors, representing a significant advancement in developing biologically plausible self-supervised learning models for neuromorphic computing at the edge.
Read more5/28/2024
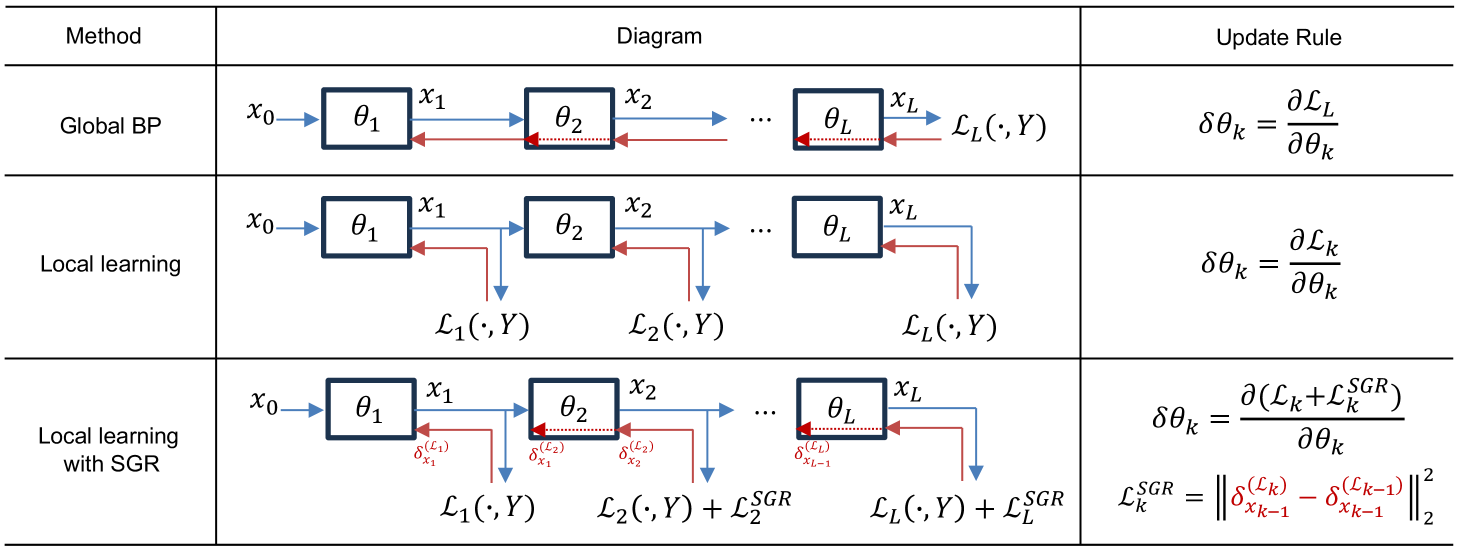
0
Towards Interpretable Deep Local Learning with Successive Gradient Reconciliation
Yibo Yang, Xiaojie Li, Motasem Alfarra, Hasan Hammoud, Adel Bibi, Philip Torr, Bernard Ghanem
Relieving the reliance of neural network training on a global back-propagation (BP) has emerged as a notable research topic due to the biological implausibility and huge memory consumption caused by BP. Among the existing solutions, local learning optimizes gradient-isolated modules of a neural network with local errors and has been proved to be effective even on large-scale datasets. However, the reconciliation among local errors has never been investigated. In this paper, we first theoretically study non-greedy layer-wise training and show that the convergence cannot be assured when the local gradient in a module w.r.t. its input is not reconciled with the local gradient in the previous module w.r.t. its output. Inspired by the theoretical result, we further propose a local training strategy that successively regularizes the gradient reconciliation between neighboring modules without breaking gradient isolation or introducing any learnable parameters. Our method can be integrated into both local-BP and BP-free settings. In experiments, we achieve significant performance improvements compared to previous methods. Particularly, our method for CNN and Transformer architectures on ImageNet is able to attain a competitive performance with global BP, saving more than 40% memory consumption.
Read more6/11/2024