Towards Interpretable Deep Local Learning with Successive Gradient Reconciliation
2406.05222
0
0
Abstract
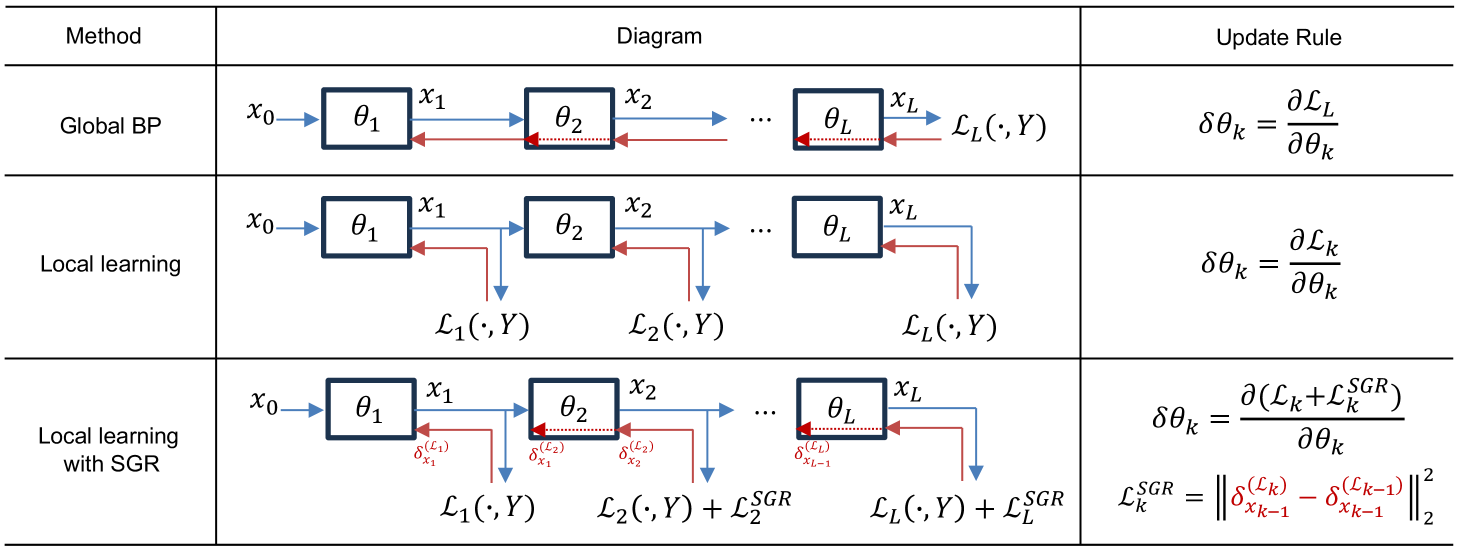
Relieving the reliance of neural network training on a global back-propagation (BP) has emerged as a notable research topic due to the biological implausibility and huge memory consumption caused by BP. Among the existing solutions, local learning optimizes gradient-isolated modules of a neural network with local errors and has been proved to be effective even on large-scale datasets. However, the reconciliation among local errors has never been investigated. In this paper, we first theoretically study non-greedy layer-wise training and show that the convergence cannot be assured when the local gradient in a module w.r.t. its input is not reconciled with the local gradient in the previous module w.r.t. its output. Inspired by the theoretical result, we further propose a local training strategy that successively regularizes the gradient reconciliation between neighboring modules without breaking gradient isolation or introducing any learnable parameters. Our method can be integrated into both local-BP and BP-free settings. In experiments, we achieve significant performance improvements compared to previous methods. Particularly, our method for CNN and Transformer architectures on ImageNet is able to attain a competitive performance with global BP, saving more than 40% memory consumption.
Create account to get full access
Overview
- The paper proposes a new approach called Successive Gradient Reconciliation (SGR) to improve the interpretability of deep learning models.
- SGR aims to reconcile the global and local learning objectives of deep neural networks, allowing for better understanding of the model's decision-making process.
- The authors demonstrate the effectiveness of SGR on various tasks, including image classification and natural language processing.
Plain English Explanation
Deep learning models have become incredibly powerful, but they can also be opaque "black boxes" that are difficult to understand. This paper introduces a new technique called Successive Gradient Reconciliation (SGR) that tries to make these models more interpretable.
The key idea behind SGR is to better align the global and local objectives of the deep neural network during training. Typically, deep models are trained to optimize a single, overall performance metric. But SGR introduces a way to also consider the individual "local" decisions made by different parts of the network. By reconciling these global and local objectives, the model becomes more transparent - we can better understand why it's making the decisions it does.
The authors show that SGR leads to improved performance on a variety of tasks, from image classification to natural language processing. This suggests that the added interpretability doesn't come at the cost of accuracy.
Technical Explanation
The paper proposes a new training algorithm called Successive Gradient Reconciliation (SGR) that aims to reconcile the global and local learning objectives of deep neural networks. Typically, deep models are trained to optimize an overall performance metric, like classification accuracy. But this global objective can conflict with the "local" decisions made by individual components of the network.
SGR addresses this by introducing an additional term in the loss function that encourages alignment between the global and local gradients. Specifically, it computes the gradients with respect to the local and global objectives separately, then minimizes the difference between them. This "gradient reconciliation" process is applied successively throughout training.
The authors evaluate SGR on several benchmark tasks, including image classification and natural language processing. They find that SGR leads to improved performance compared to standard training, while also producing more interpretable models. The models trained with SGR allow for better understanding of which input features are driving the final predictions.
Critical Analysis
The paper provides a compelling approach to improving the interpretability of deep learning models. By reconciling the global and local objectives, SGR seems to produce models that are more transparent and easier to understand.
However, the authors do not provide a detailed analysis of the computational overhead or training time required for SGR compared to standard training. This is an important practical consideration, as the added interpretability should not come at an unacceptable cost in terms of training efficiency.
Additionally, the paper only evaluates SGR on a limited set of benchmark tasks. More research is needed to understand how well the method generalizes to a wider range of applications and problem domains. The authors also do not discuss potential issues or failure cases where SGR may not be effective.
Overall, the work represents an interesting step towards more interpretable deep learning, but further research and real-world evaluation is needed to fully assess the merits and limitations of the Successive Gradient Reconciliation approach.
Conclusion
This paper introduces a novel training algorithm called Successive Gradient Reconciliation (SGR) that aims to make deep learning models more interpretable. By aligning the global and local objectives of the network during training, SGR produces models that allow for better understanding of the decision-making process.
The authors demonstrate the effectiveness of SGR on several benchmark tasks, showing improved performance and interpretability compared to standard training methods. This suggests that SGR could be a valuable tool for developing deep learning systems that are more transparent and trustworthy.
As AI becomes increasingly pervasive in our lives, techniques like SGR that enhance model interpretability will be crucial for building robust and accountable intelligent systems. The work presented in this paper represents an important step towards that goal.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
LLS: Local Learning Rule for Deep Neural Networks Inspired by Neural Activity Synchronization
Marco Paul E. Apolinario, Arani Roy, Kaushik Roy
0
0
Training deep neural networks (DNNs) using traditional backpropagation (BP) presents challenges in terms of computational complexity and energy consumption, particularly for on-device learning where computational resources are limited. Various alternatives to BP, including random feedback alignment, forward-forward, and local classifiers, have been explored to address these challenges. These methods have their advantages, but they can encounter difficulties when dealing with intricate visual tasks or demand considerable computational resources. In this paper, we propose a novel Local Learning rule inspired by neural activity Synchronization phenomena (LLS) observed in the brain. LLS utilizes fixed periodic basis vectors to synchronize neuron activity within each layer, enabling efficient training without the need for additional trainable parameters. We demonstrate the effectiveness of LLS and its variations, LLS-M and LLS-MxM, on multiple image classification datasets, achieving accuracy comparable to BP with reduced computational complexity and minimal additional parameters. Furthermore, the performance of LLS on the Visual Wake Word (VWW) dataset highlights its suitability for on-device learning tasks, making it a promising candidate for edge hardware implementations.
5/28/2024

ReconBoost: Boosting Can Achieve Modality Reconcilement
Cong Hua, Qianqian Xu, Shilong Bao, Zhiyong Yang, Qingming Huang
0
0
This paper explores a novel multi-modal alternating learning paradigm pursuing a reconciliation between the exploitation of uni-modal features and the exploration of cross-modal interactions. This is motivated by the fact that current paradigms of multi-modal learning tend to explore multi-modal features simultaneously. The resulting gradient prohibits further exploitation of the features in the weak modality, leading to modality competition, where the dominant modality overpowers the learning process. To address this issue, we study the modality-alternating learning paradigm to achieve reconcilement. Specifically, we propose a new method called ReconBoost to update a fixed modality each time. Herein, the learning objective is dynamically adjusted with a reconcilement regularization against competition with the historical models. By choosing a KL-based reconcilement, we show that the proposed method resembles Friedman's Gradient-Boosting (GB) algorithm, where the updated learner can correct errors made by others and help enhance the overall performance. The major difference with the classic GB is that we only preserve the newest model for each modality to avoid overfitting caused by ensembling strong learners. Furthermore, we propose a memory consolidation scheme and a global rectification scheme to make this strategy more effective. Experiments over six multi-modal benchmarks speak to the efficacy of the method. We release the code at https://github.com/huacong/ReconBoost.
5/16/2024
New!Semi-adaptive Synergetic Two-way Pseudoinverse Learning System
Binghong Liu, Ziqi Zhao, Shupan Li, Ke Wang
0
0
Deep learning has become a crucial technology for making breakthroughs in many fields. Nevertheless, it still faces two important challenges in theoretical and applied aspects. The first lies in the shortcomings of gradient descent based learning schemes which are time-consuming and difficult to determine the learning control hyperparameters. Next, the architectural design of the model is usually tricky. In this paper, we propose a semi-adaptive synergetic two-way pseudoinverse learning system, wherein each subsystem encompasses forward learning, backward learning, and feature concatenation modules. The whole system is trained using a non-gradient descent learning algorithm. It simplifies the hyperparameter tuning while improving the training efficiency. The architecture of the subsystems is designed using a data-driven approach that enables automated determination of the depth of the subsystems. We compare our method with the baselines of mainstream non-gradient descent based methods and the results demonstrate the effectiveness of our proposed method. The source code for this paper is available at http://github.com/B-berrypie/Semi-adaptive-Synergetic-Two-way-Pseudoinverse-Learning-System}{http://github.com/B-berrypie/Semi-adaptive-Synergetic-Two-way-Pseudoinverse-Learning-System.
6/28/2024

GLCAN: Global-Local Collaborative Auxiliary Network for Local Learning
Feiyu Zhu, Yuming Zhang, Changpeng Cai, Guinan Guo, Jiao Li, Xiuyuan Guo, Quanwei Zhang, Peizhe Wang, Chenghao He, Junhao Su
0
0
Traditional deep neural networks typically use end-to-end backpropagation, which often places a big burden on GPU memory. Another promising training method is local learning, which involves splitting the network into blocks and training them in parallel with the help of an auxiliary network. Local learning has been widely studied and applied to image classification tasks, and its performance is comparable to that of end-to-end method. However, different image tasks often rely on different feature representations, which is difficult for typical auxiliary networks to adapt to. To solve this problem, we propose the construction method of Global-Local Collaborative Auxiliary Network (GLCAN), which provides a macroscopic design approach for auxiliary networks. This is the first demonstration that local learning methods can be successfully applied to other tasks such as object detection and super-resolution. GLCAN not only saves a lot of GPU memory, but also has comparable performance to an end-to-end approach on data sets for multiple different tasks.
6/4/2024