LMT-Net: Lane Model Transformer Network for Automated HD Mapping from Sparse Vehicle Observations

0

Sign in to get full access
Overview
- Presents the LMT-Net, a novel lane model transformer network for automated HD mapping from sparse vehicle observations
- Leverages a transformer-based architecture to effectively capture long-range dependencies in lane structures
- Achieves state-of-the-art performance on benchmark datasets for high-definition (HD) lane mapping
Plain English Explanation
The research paper introduces the LMT-Net, a new deep learning model that can create detailed maps of road lanes from limited vehicle sensor data. Current methods for building these high-definition (HD) maps often require extensive data collection and processing, which can be time-consuming and expensive.
The LMT-Net takes a different approach by using a transformer-based architecture. Transformers are a type of neural network that excel at understanding long-range relationships in data, which is crucial for accurately modeling the complex structure of road lanes. By leveraging this transformer-based design, the LMT-Net can generate high-quality HD maps from sparse vehicle observations, reducing the need for extensive data collection.
The researchers demonstrate that the LMT-Net outperforms existing methods on standard benchmarks for HD lane mapping. This suggests the model could enable more efficient and cost-effective methods for creating and maintaining detailed road maps, which are essential for the development of autonomous driving systems and advanced driver assistance features.
Technical Explanation
The core innovation of the LMT-Net is its use of a transformer-based architecture to effectively capture the long-range dependencies inherent in lane structures. Traditional convolutional neural networks (CNNs) have difficulty modeling these complex spatial relationships, but transformers are well-suited for the task.
The LMT-Net takes as input a sparse set of vehicle observations, such as lane markings or vehicle trajectories, and outputs a detailed HD map of the road lanes. The transformer-based design allows the model to learn rich, global representations of the lane structure, which are then used to generate an accurate lane topology.
Key components of the LMT-Net architecture include:
- Spatial Encoding Module: Encodes the input vehicle observations into a spatial grid representation
- Transformer Encoder: Applies a series of transformer layers to capture long-range dependencies in the lane structure
- Lane Prediction Head: Generates the final HD lane map from the transformer-encoded features
The researchers evaluate the LMT-Net on several benchmark datasets for HD lane mapping and demonstrate state-of-the-art performance, outperforming existing CNN-based approaches. This highlights the effectiveness of the transformer-based design for this task.
Critical Analysis
The LMT-Net represents a promising step forward in the development of efficient and accurate methods for HD lane mapping. By leveraging a transformer-based architecture, the model is able to overcome limitations of traditional CNN-based approaches and generate high-quality lane maps from sparse vehicle data.
However, the paper does not address several potential limitations and areas for further research:
- Generalization: The evaluation is limited to a few benchmark datasets, and it's unclear how well the LMT-Net would generalize to diverse real-world environments and road configurations.
- Computational Efficiency: Transformer-based models can be computationally intensive, which may limit their deployment in resource-constrained autonomous driving systems.
- Explainability: As with many deep learning models, the inner workings of the LMT-Net may be difficult to interpret, which could hinder trust and adoption.
Addressing these challenges through further research and experimentation would help solidify the LMT-Net's potential for real-world applications in automated HD mapping and autonomous driving.
Conclusion
The LMT-Net presents a novel approach to automated HD mapping that leverages the power of transformer-based deep learning. By effectively capturing the long-range dependencies inherent in lane structures, the model can generate high-quality lane maps from sparse vehicle data, potentially enabling more efficient and cost-effective methods for building and maintaining detailed road maps.
The promising performance of the LMT-Net on benchmark datasets suggests it could play an important role in the development of advanced autonomous driving systems and other applications that rely on accurate, up-to-date road information. Further research to address potential limitations and explore real-world deployment scenarios would help solidify the impact of this innovative approach to automated HD mapping.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!LMT-Net: Lane Model Transformer Network for Automated HD Mapping from Sparse Vehicle Observations
Michael Mink, Thomas Monninger, Steffen Staab
In autonomous driving, High Definition (HD) maps provide a complete lane model that is not limited by sensor range and occlusions. However, the generation and upkeep of HD maps involves periodic data collection and human annotations, limiting scalability. To address this, we investigate automating the lane model generation and the use of sparse vehicle observations instead of dense sensor measurements. For our approach, a pre-processing step generates polylines by aligning and aggregating observed lane boundaries. Aligned driven traces are used as starting points for predicting lane pairs defined by the left and right boundary points. We propose Lane Model Transformer Network (LMT-Net), an encoder-decoder neural network architecture that performs polyline encoding and predicts lane pairs and their connectivity. A lane graph is formed by using predicted lane pairs as nodes and predicted lane connectivity as edges. We evaluate the performance of LMT-Net on an internal dataset that consists of multiple vehicle observations as well as human annotations as Ground Truth (GT). The evaluation shows promising results and demonstrates superior performance compared to the implemented baseline on both highway and non-highway Operational Design Domain (ODD).
Read more9/20/2024

0
LGmap: Local-to-Global Mapping Network for Online Long-Range Vectorized HD Map Construction
Kuang Wu, Sulei Nian, Can Shen, Chuan Yang, Zhanbin Li
This report introduces the first-place winning solution for the Autonomous Grand Challenge 2024 - Mapless Driving. In this report, we introduce a novel online mapping pipeline LGmap, which adept at long-range temporal model. Firstly, we propose symmetric view transformation(SVT), a hybrid view transformation module. Our approach overcomes the limitations of forward sparse feature representation and utilizing depth perception and SD prior information. Secondly, we propose hierarchical temporal fusion(HTF) module. It employs temporal information from local to global, which empowers the construction of long-range HD map with high stability. Lastly, we propose a novel ped-crossing resampling. The simplified ped crossing representation accelerates the instance attention based decoder convergence performance. Our method achieves 0.66 UniScore in the Mapless Driving OpenLaneV2 test set.
Read more6/21/2024
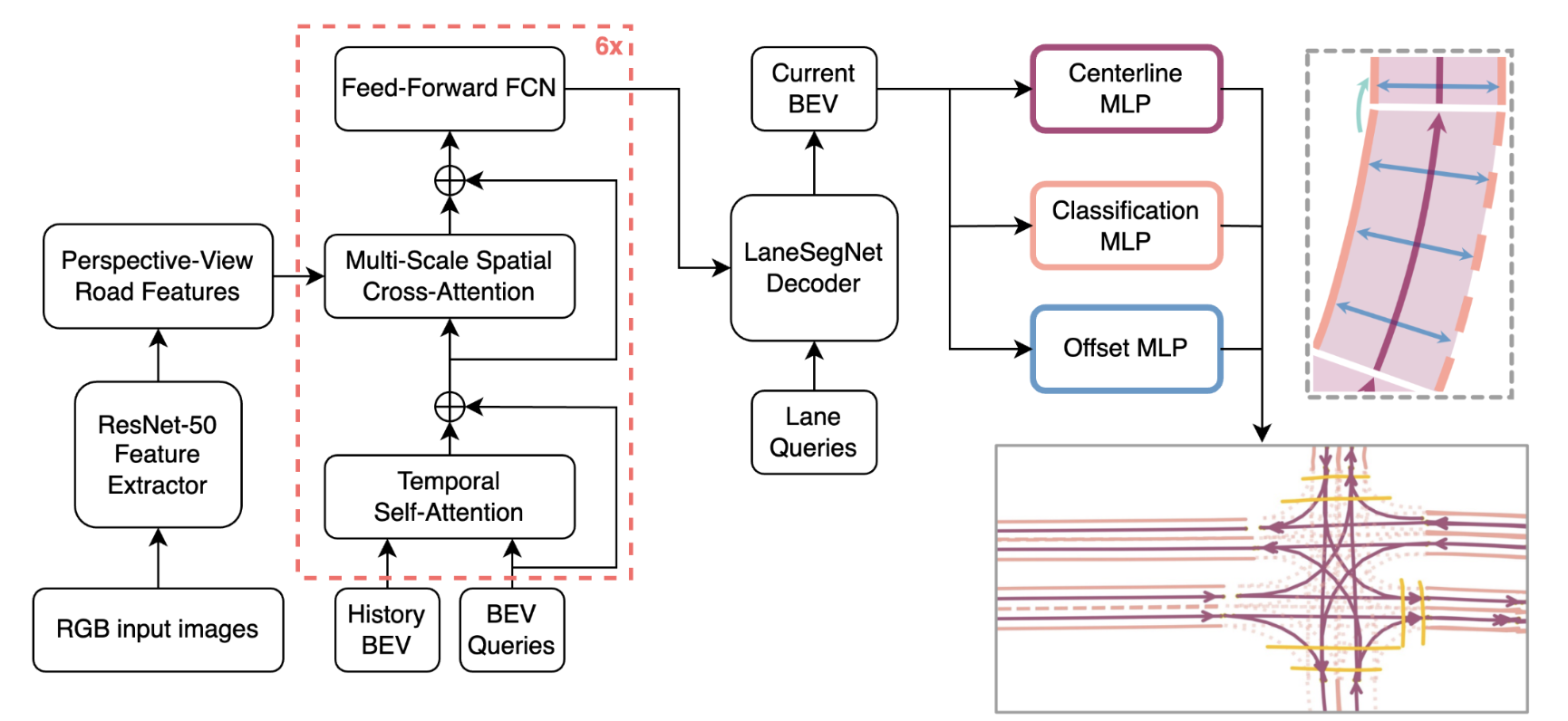
0
LaneSegNet Design Study
William Stevens, Vishal Urs, Karthik Selvaraj, Gabriel Torres, Gaurish Lakhanpal
With the increasing prevalence of autonomous vehicles, it is essential for computer vision algorithms to accurately assess road features in real-time. This study explores the LaneSegNet architecture, a new approach to lane topology prediction which integrates topological information with lane-line data to provide a more contextual understanding of road environments. The LaneSegNet architecture includes a feature extractor, lane encoder, lane decoder, and prediction head, leveraging components from ResNet-50, BEVFormer, and various attention mechanisms. We experimented with optimizations to the LaneSegNet architecture through feature extractor modification and transformer encoder-decoder stack modification. We found that modifying the encoder and decoder stacks offered an interesting tradeoff between training time and prediction accuracy, with certain combinations showing promising results. Our implementation, trained on a single NVIDIA Tesla A100 GPU, found that a 2:4 ratio reduced training time by 22.3% with only a 7.1% drop in mean average precision, while a 4:8 ratio increased training time by only 11.1% but improved mean average precision by a significant 23.7%. These results indicate that strategic hyperparameter tuning can yield substantial improvements depending on the resources of the user. This study provides valuable insights for optimizing LaneSegNet according to available computation power, making it more accessible for users with limited resources and increasing the capabilities for users with more powerful resources.
Read more8/1/2024
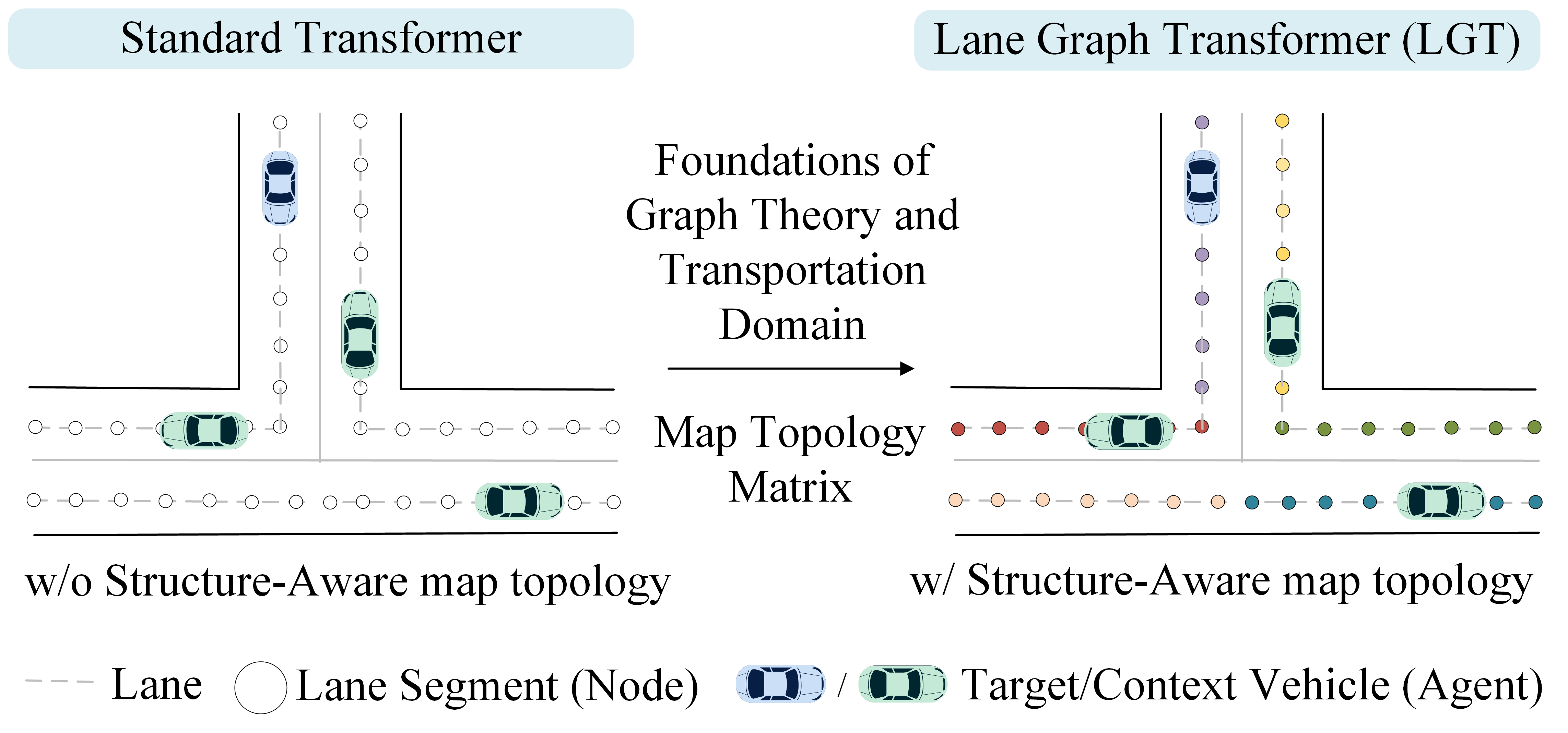
0
A Structure-Aware Lane Graph Transformer Model for Vehicle Trajectory Prediction
Sun Zhanbo, Dong Caiyin, Ji Ang, Zhao Ruibin, Zhao Yu
Accurate prediction of future trajectories for surrounding vehicles is vital for the safe operation of autonomous vehicles. This study proposes a Lane Graph Transformer (LGT) model with structure-aware capabilities. Its key contribution lies in encoding the map topology structure into the attention mechanism. To address variations in lane information from different directions, four Relative Positional Encoding (RPE) matrices are introduced to capture the local details of the map topology structure. Additionally, two Shortest Path Distance (SPD) matrices are employed to capture distance information between two accessible lanes. Numerical results indicate that the proposed LGT model achieves a significantly higher prediction performance on the Argoverse 2 dataset. Specifically, the minFDE$_6$ metric was decreased by 60.73% compared to the Argoverse 2 baseline model (Nearest Neighbor) and the b-minFDE$_6$ metric was reduced by 2.65% compared to the baseline LaneGCN model. Furthermore, ablation experiments demonstrated that the consideration of map topology structure led to a 4.24% drop in the b-minFDE$_6$ metric, validating the effectiveness of this model.
Read more5/31/2024