LOC-ZSON: Language-driven Object-Centric Zero-Shot Object Retrieval and Navigation

0
Sign in to get full access
Overview
- Proposes a novel approach called Language-driven Object-Centric Zero-Shot Object Retrieval and Navigation (LOC-ZSON) for zero-shot object retrieval and navigation
- Leverages language-driven object-centric representations to enable zero-shot recognition and navigation of unseen objects
- Demonstrated effective performance on challenging benchmark datasets for zero-shot object retrieval and navigation
Plain English Explanation
The paper introduces a new system called LOC-ZSON that allows robots and other AI systems to recognize and navigate to objects they've never seen before. This is an important capability, as real-world environments often contain many objects that a robot may not have been explicitly trained on.
LOC-ZSON works by using language-based representations of objects, rather than just visual features. This allows the system to reason about objects conceptually, rather than just matching visual patterns. For example, if the system knows what a "chair" is from language, it can recognize a new type of chair it's never seen before.
The key innovation is combining this language-driven, object-centric approach with the ability to do "zero-shot" learning - that is, recognizing and navigating to objects without any prior training examples. This allows the system to be much more flexible and adaptable to new environments.
The paper demonstrates that LOC-ZSON outperforms existing approaches on benchmark tasks for zero-shot object retrieval and navigation. This suggests the method could be valuable for real-world robotics and AI applications that need to operate in dynamic, unconstrained environments.
Technical Explanation
The paper proposes a novel framework called Language-driven Object-Centric Zero-Shot Object Retrieval and Navigation (LOC-ZSON) that leverages language-driven object-centric representations to enable zero-shot recognition and navigation of unseen objects.
The core innovation is the use of language-based object embeddings, which capture semantic and relational knowledge about objects. These embeddings are used to build an object-centric representation of the environment, rather than relying solely on visual features. This allows the system to reason about objects conceptually, enabling zero-shot recognition of novel objects.
The system is trained in two stages. First, it learns to map language descriptions to object embeddings. Second, it learns to use these embeddings for object retrieval and navigation tasks, without any direct training on the target objects.
Experiments on challenging benchmark datasets for zero-shot object retrieval and navigation demonstrate the effectiveness of the LOC-ZSON approach. It outperforms prior methods that rely on traditional, vision-only object representations.
Critical Analysis
The paper makes a compelling case for the value of language-driven, object-centric representations for zero-shot learning. The results on challenging benchmark tasks are promising and suggest LOC-ZSON could be a useful tool for real-world robotics and AI applications.
However, the paper does not address some potential limitations or areas for further research. For example, the performance of the system may degrade as the number of unseen objects increases, or it may struggle with objects that are difficult to describe in language. Additionally, the paper does not explore how the system would handle dynamic environments or partially occluded objects.
Further research could investigate ways to improve the robustness and scalability of the approach, such as by incorporating more sophisticated language understanding or by combining the language-driven representations with complementary visual features. Exploring how LOC-ZSON could be integrated with existing object detection and navigation systems would also be valuable.
Overall, the paper presents an interesting and potentially impactful approach to the challenge of zero-shot object recognition and navigation. Continued refinement and evaluation of the method could lead to significant advancements in real-world AI capabilities.
Conclusion
The LOC-ZSON framework introduced in this paper represents an innovative approach to the problem of zero-shot object retrieval and navigation. By leveraging language-driven, object-centric representations, the system is able to recognize and navigate to novel objects without any prior training.
The strong performance on benchmark tasks suggests LOC-ZSON could be a valuable tool for a wide range of real-world AI and robotics applications, where the ability to adapt to new environments and objects is crucial. Further research to address potential limitations and integrate the approach with other state-of-the-art techniques could lead to even more robust and capable zero-shot learning systems.
Overall, the paper makes an important contribution to the field of zero-shot learning, highlighting the power of language-based reasoning for bridging the gap between visual perception and conceptual understanding. As AI systems continue to advance, approaches like LOC-ZSON will be increasingly vital for enabling flexible, adaptable, and human-centric intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LOC-ZSON: Language-driven Object-Centric Zero-Shot Object Retrieval and Navigation
Tianrui Guan, Yurou Yang, Harry Cheng, Muyuan Lin, Richard Kim, Rajasimman Madhivanan, Arnie Sen, Dinesh Manocha
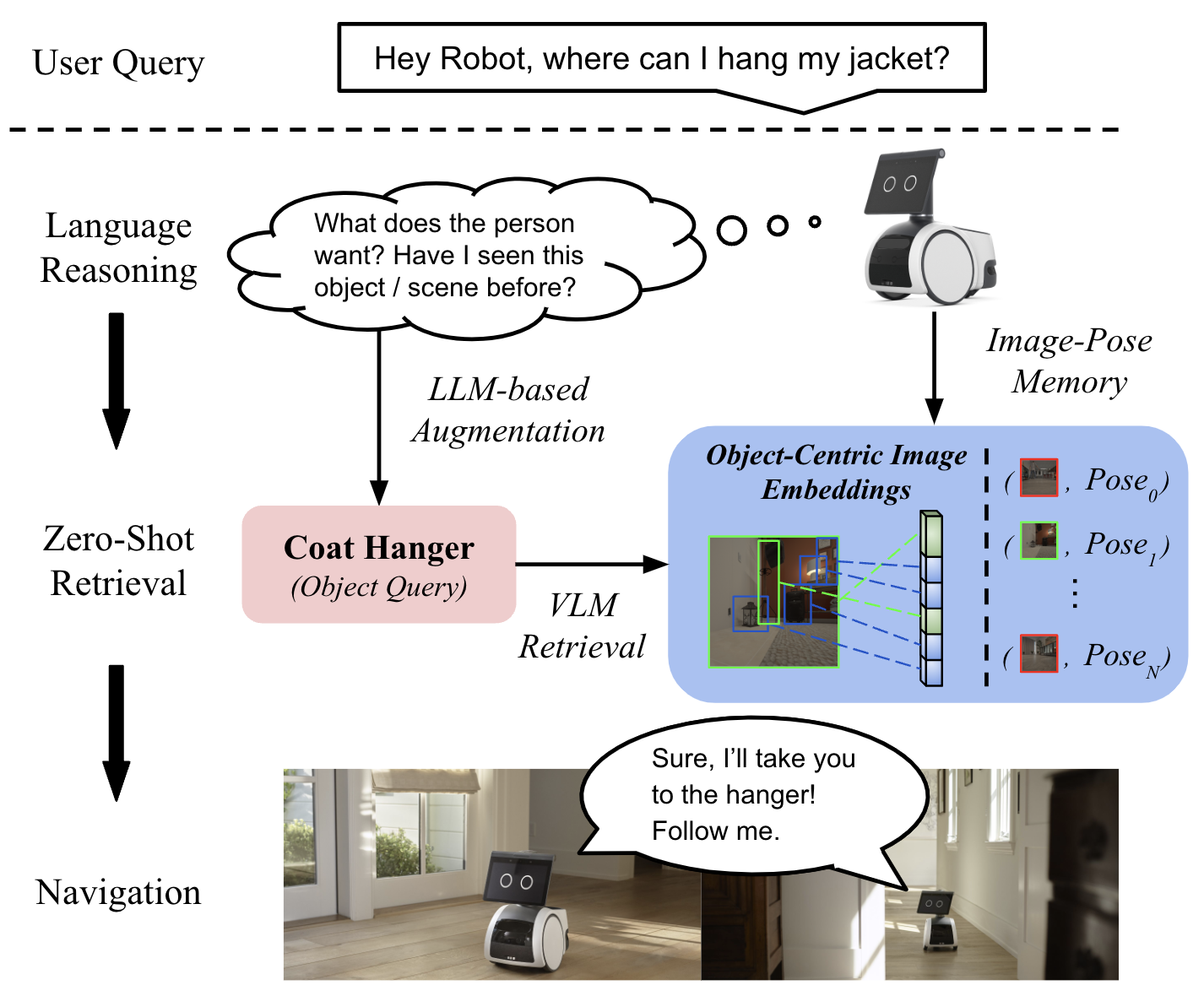
In this paper, we present LOC-ZSON, a novel Language-driven Object-Centric image representation for object navigation task within complex scenes. We propose an object-centric image representation and corresponding losses for visual-language model (VLM) fine-tuning, which can handle complex object-level queries. In addition, we design a novel LLM-based augmentation and prompt templates for stability during training and zero-shot inference. We implement our method on Astro robot and deploy it in both simulated and real-world environments for zero-shot object navigation. We show that our proposed method can achieve an improvement of 1.38 - 13.38% in terms of text-to-image recall on different benchmark settings for the retrieval task. For object navigation, we show the benefit of our approach in simulation and real world, showing 5% and 16.67% improvement in terms of navigation success rate, respectively.
Read more5/10/2024
🤿
0
Think, Act, and Ask: Open-World Interactive Personalized Robot Navigation
Yinpei Dai, Run Peng, Sikai Li, Joyce Chai
Zero-Shot Object Navigation (ZSON) enables agents to navigate towards open-vocabulary objects in unknown environments. The existing works of ZSON mainly focus on following individual instructions to find generic object classes, neglecting the utilization of natural language interaction and the complexities of identifying user-specific objects. To address these limitations, we introduce Zero-shot Interactive Personalized Object Navigation (ZIPON), where robots need to navigate to personalized goal objects while engaging in conversations with users. To solve ZIPON, we propose a new framework termed Open-woRld Interactive persOnalized Navigation (ORION), which uses Large Language Models (LLMs) to make sequential decisions to manipulate different modules for perception, navigation and communication. Experimental results show that the performance of interactive agents that can leverage user feedback exhibits significant improvement. However, obtaining a good balance between task completion and the efficiency of navigation and interaction remains challenging for all methods. We further provide more findings on the impact of diverse user feedback forms on the agents' performance. Code is available at https://github.com/sled-group/navchat.
Read more5/31/2024

0
Zero-Shot Object-Centric Representation Learning
Aniket Didolkar, Andrii Zadaianchuk, Anirudh Goyal, Mike Mozer, Yoshua Bengio, Georg Martius, Maximilian Seitzer
The goal of object-centric representation learning is to decompose visual scenes into a structured representation that isolates the entities. Recent successes have shown that object-centric representation learning can be scaled to real-world scenes by utilizing pre-trained self-supervised features. However, so far, object-centric methods have mostly been applied in-distribution, with models trained and evaluated on the same dataset. This is in contrast to the wider trend in machine learning towards general-purpose models directly applicable to unseen data and tasks. Thus, in this work, we study current object-centric methods through the lens of zero-shot generalization by introducing a benchmark comprising eight different synthetic and real-world datasets. We analyze the factors influencing zero-shot performance and find that training on diverse real-world images improves transferability to unseen scenarios. Furthermore, inspired by the success of task-specific fine-tuning in foundation models, we introduce a novel fine-tuning strategy to adapt pre-trained vision encoders for the task of object discovery. We find that the proposed approach results in state-of-the-art performance for unsupervised object discovery, exhibiting strong zero-shot transfer to unseen datasets.
Read more8/20/2024
0
From Words to Poses: Enhancing Novel Object Pose Estimation with Vision Language Models
Tessa Pulli, Stefan Thalhammer, Simon Schwaiger, Markus Vincze
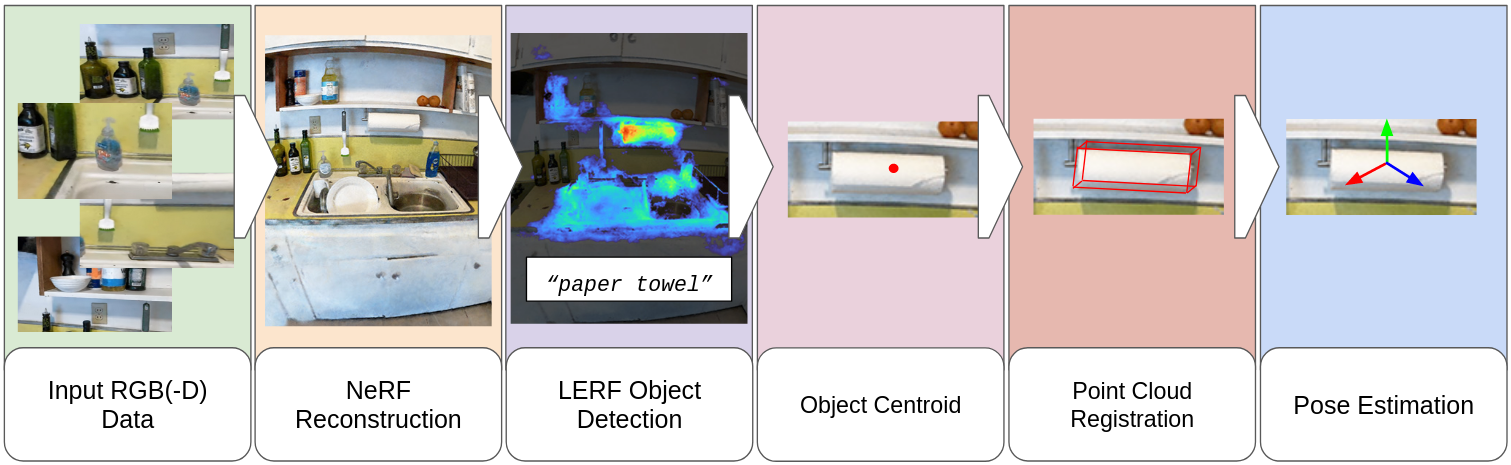
Robots are increasingly envisioned to interact in real-world scenarios, where they must continuously adapt to new situations. To detect and grasp novel objects, zero-shot pose estimators determine poses without prior knowledge. Recently, vision language models (VLMs) have shown considerable advances in robotics applications by establishing an understanding between language input and image input. In our work, we take advantage of VLMs zero-shot capabilities and translate this ability to 6D object pose estimation. We propose a novel framework for promptable zero-shot 6D object pose estimation using language embeddings. The idea is to derive a coarse location of an object based on the relevancy map of a language-embedded NeRF reconstruction and to compute the pose estimate with a point cloud registration method. Additionally, we provide an analysis of LERF's suitability for open-set object pose estimation. We examine hyperparameters, such as activation thresholds for relevancy maps and investigate the zero-shot capabilities on an instance- and category-level. Furthermore, we plan to conduct robotic grasping experiments in a real-world setting.
Read more9/10/2024