From Words to Poses: Enhancing Novel Object Pose Estimation with Vision Language Models

0
Sign in to get full access
Overview
- This paper presents a novel approach to enhancing object pose estimation using vision-language models.
- The key idea is to leverage language information to improve the performance of object pose estimation, especially for novel objects.
- The proposed method achieves state-of-the-art results on several object pose estimation benchmarks.
Plain English Explanation
The paper introduces a new way to estimate the poses (positions and orientations) of objects in images, especially objects that the model hasn't seen before. The core insight is to use language information, in addition to visual information, to improve the pose estimation.
Typically, object pose estimation models are trained on a limited set of objects and struggle to generalize to novel objects. To address this, the researchers combine a vision model (which processes the image) with a language model (which processes text descriptions of the objects). By integrating these two modalities, the model can learn richer representations that allow it to better estimate the poses of unfamiliar objects.
For example, if the model is shown an image of a new type of chair and also given a text description of the chair's appearance and function, it can use this combined information to more accurately determine the chair's position and orientation in the scene. The language data provides additional context that complements the visual data, leading to improved pose estimation performance.
The authors demonstrate the effectiveness of their approach on several standard object pose estimation benchmarks, where it outperforms previous state-of-the-art methods. This work highlights the potential of combining vision and language to tackle challenging computer vision problems, especially those involving novel or unseen objects.
Technical Explanation
The paper proposes a novel vision-language model for enhancing object pose estimation. The key components are:
- Vision Backbone: A convolutional neural network (CNN) that takes an image as input and extracts visual features.
- Language Encoder: A transformer-based language model that encodes textual descriptions of objects.
- Pose Estimation Head: A module that combines the visual and language features to predict the 6D pose (3D position and 3D orientation) of the object.
The vision and language components are trained jointly, allowing the model to learn cross-modal representations that capture the relationship between visual appearance and semantic information. This enables the model to better generalize to novel objects, whose poses can be estimated by leveraging the associated text descriptions.
The authors evaluate their approach on several object pose estimation benchmarks, including the LINEMOD and YCB-Video datasets. The results demonstrate that the vision-language model outperforms previous state-of-the-art methods, particularly on novel object instances.
Critical Analysis
The paper presents a promising approach to leveraging language information for improving object pose estimation, an important computer vision task. The key strengths of the work include:
- Innovative Combination of Vision and Language: Integrating vision and language models is a powerful way to enhance object understanding, as the complementary information can lead to more robust representations.
- Strong Empirical Results: The proposed method achieves state-of-the-art performance on several challenging benchmarks, indicating its practical relevance.
- Potential for Generalization: The vision-language approach could be applied to other computer vision problems beyond pose estimation, such as object detection and scene understanding.
However, the paper also has some potential limitations:
- Dependency on Text Descriptions: The method relies on having access to accurate text descriptions of the objects, which may not always be available in real-world scenarios.
- Scalability to Large-Scale Datasets: The experiments were conducted on relatively small datasets, and it's unclear how the approach would scale to larger, more diverse datasets.
- Interpretability of Cross-Modal Representations: The paper does not provide much insight into how the vision-language model learns the cross-modal associations, which could be valuable for understanding the model's behavior.
Overall, this work demonstrates the promising potential of vision-language models for enhancing object pose estimation and opens up avenues for further research in this direction.
Conclusion
This paper presents a novel approach to object pose estimation that leverages vision-language models to improve performance, especially on novel object instances. By combining visual and semantic information, the proposed method can learn more robust representations that enable better generalization. The strong empirical results on standard benchmarks highlight the practical relevance of this work and its potential to advance the field of computer vision. While the approach has some limitations, it represents an important step towards developing more versatile and capable object understanding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
From Words to Poses: Enhancing Novel Object Pose Estimation with Vision Language Models
Tessa Pulli, Stefan Thalhammer, Simon Schwaiger, Markus Vincze
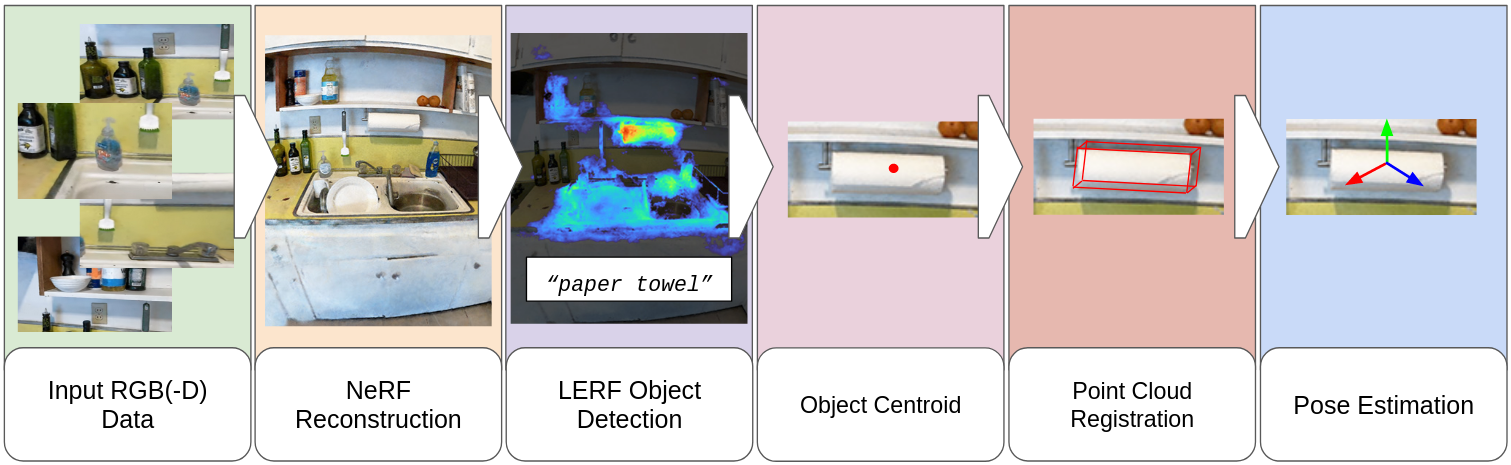
Robots are increasingly envisioned to interact in real-world scenarios, where they must continuously adapt to new situations. To detect and grasp novel objects, zero-shot pose estimators determine poses without prior knowledge. Recently, vision language models (VLMs) have shown considerable advances in robotics applications by establishing an understanding between language input and image input. In our work, we take advantage of VLMs zero-shot capabilities and translate this ability to 6D object pose estimation. We propose a novel framework for promptable zero-shot 6D object pose estimation using language embeddings. The idea is to derive a coarse location of an object based on the relevancy map of a language-embedded NeRF reconstruction and to compute the pose estimate with a point cloud registration method. Additionally, we provide an analysis of LERF's suitability for open-set object pose estimation. We examine hyperparameters, such as activation thresholds for relevancy maps and investigate the zero-shot capabilities on an instance- and category-level. Furthermore, we plan to conduct robotic grasping experiments in a real-world setting.
Read more9/10/2024

0
High-resolution open-vocabulary object 6D pose estimation
Jaime Corsetti, Davide Boscaini, Francesco Giuliari, Changjae Oh, Andrea Cavallaro, Fabio Poiesi
The generalisation to unseen objects in the 6D pose estimation task is very challenging. While Vision-Language Models (VLMs) enable using natural language descriptions to support 6D pose estimation of unseen objects, these solutions underperform compared to model-based methods. In this work we present Horyon, an open-vocabulary VLM-based architecture that addresses relative pose estimation between two scenes of an unseen object, described by a textual prompt only. We use the textual prompt to identify the unseen object in the scenes and then obtain high-resolution multi-scale features. These features are used to extract cross-scene matches for registration. We evaluate our model on a benchmark with a large variety of unseen objects across four datasets, namely REAL275, Toyota-Light, Linemod, and YCB-Video. Our method achieves state-of-the-art performance on all datasets, outperforming by 12.6 in Average Recall the previous best-performing approach.
Read more7/12/2024
📉
0
Dream2Real: Zero-Shot 3D Object Rearrangement with Vision-Language Models
Ivan Kapelyukh, Yifei Ren, Ignacio Alzugaray, Edward Johns
We introduce Dream2Real, a robotics framework which integrates vision-language models (VLMs) trained on 2D data into a 3D object rearrangement pipeline. This is achieved by the robot autonomously constructing a 3D representation of the scene, where objects can be rearranged virtually and an image of the resulting arrangement rendered. These renders are evaluated by a VLM, so that the arrangement which best satisfies the user instruction is selected and recreated in the real world with pick-and-place. This enables language-conditioned rearrangement to be performed zero-shot, without needing to collect a training dataset of example arrangements. Results on a series of real-world tasks show that this framework is robust to distractors, controllable by language, capable of understanding complex multi-object relations, and readily applicable to both tabletop and 6-DoF rearrangement tasks.
Read more7/31/2024

0
Reflectance Estimation for Proximity Sensing by Vision-Language Models: Utilizing Distributional Semantics for Low-Level Cognition in Robotics
Masashi Osada, Gustavo A. Garcia Ricardez, Yosuke Suzuki, Tadahiro Taniguchi
Large language models (LLMs) and vision-language models (VLMs) have been increasingly used in robotics for high-level cognition, but their use for low-level cognition, such as interpreting sensor information, remains underexplored. In robotic grasping, estimating the reflectance of objects is crucial for successful grasping, as it significantly impacts the distance measured by proximity sensors. We investigate whether LLMs can estimate reflectance from object names alone, leveraging the embedded human knowledge in distributional semantics, and if the latent structure of language in VLMs positively affects image-based reflectance estimation. In this paper, we verify that 1) LLMs such as GPT-3.5 and GPT-4 can estimate an object's reflectance using only text as input; and 2) VLMs such as CLIP can increase their generalization capabilities in reflectance estimation from images. Our experiments show that GPT-4 can estimate an object's reflectance using only text input with a mean error of 14.7%, lower than the image-only ResNet. Moreover, CLIP achieved the lowest mean error of 11.8%, while GPT-3.5 obtained a competitive 19.9% compared to ResNet's 17.8%. These results suggest that the distributional semantics in LLMs and VLMs increases their generalization capabilities, and the knowledge acquired by VLMs benefits from the latent structure of language.
Read more4/15/2024