Localized Distributional Robustness in Submodular Multi-Task Subset Selection
2404.03759
0
0
Abstract
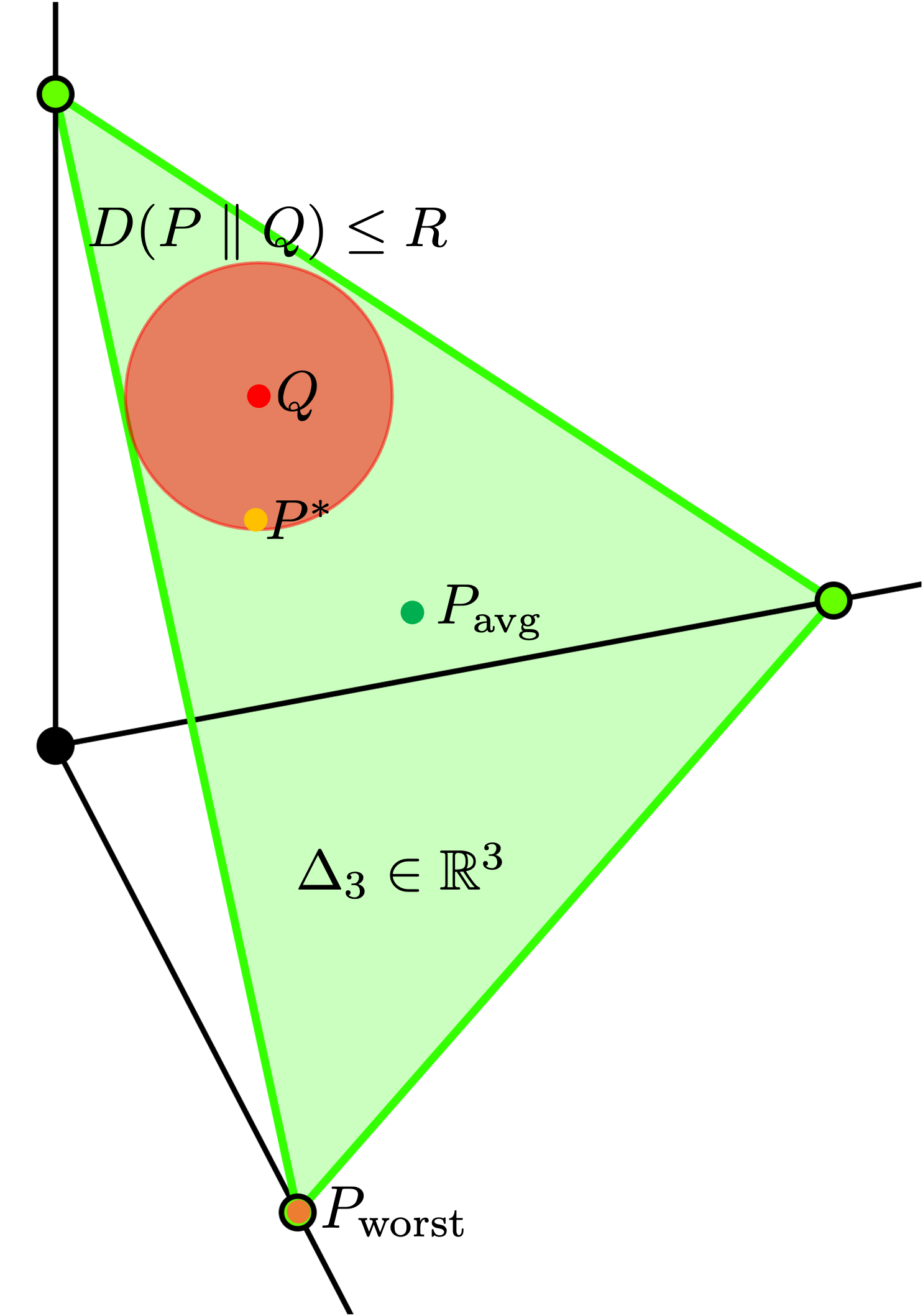
In this work, we approach the problem of multi-task submodular optimization with the perspective of local distributional robustness, within the neighborhood of a reference distribution which assigns an importance score to each task. We initially propose to introduce a regularization term which makes use of the relative entropy to the standard multi-task objective. We then demonstrate through duality that this novel formulation itself is equivalent to the maximization of a submodular function, which may be efficiently carried out through standard greedy selection methods. This approach bridges the existing gap in the optimization of performance-robustness trade-offs in multi-task subset selection. To numerically validate our theoretical results, we test the proposed method in two different setting, one involving the selection of satellites in low Earth orbit constellations in the context of a sensor selection problem, and the other involving an image summarization task using neural networks. Our method is compared with two other algorithms focused on optimizing the performance of the worst-case task, and on directly optimizing the performance on the reference distribution itself. We conclude that our novel formulation produces a solution that is locally distributional robust, and computationally inexpensive.
Create account to get full access
Overview
- This paper introduces a novel approach to submodular multi-task subset selection that is robust to distributional shifts in the data.
- The researchers propose a localized distributional robustness (LDR) framework that can handle uncertainty in the underlying data distributions across multiple tasks.
- The LDR approach is applied to the problem of selecting a subset of features or items that maximize a submodular function, while ensuring the selected subset performs well even when the data distribution changes.
Plain English Explanation
The paper tackles the challenge of selecting a subset of items or features that work well across multiple different tasks or situations. This is a common problem in machine learning, where you might want to choose a subset of the most relevant features to use in a predictive model, or select a subset of items to display to users in an online recommendation system.
The key idea is to make the selection robust to changes in the underlying data distribution. In the real world, the data we use to train our models often doesn't perfectly match the data we encounter when deploying the model. The researchers' <a href="https://aimodels.fyi/papers/arxiv/distributionally-robust-reinforcement-learning-interactive-data-collection">localized distributional robustness (LDR) framework</a> aims to find a subset of items that performs well even as the data distribution shifts.
Rather than optimizing for performance on a single fixed data distribution, the LDR approach seeks a subset that maintains good performance across a range of plausible data distributions. This makes the selected subset more reliable and less sensitive to changes in the real-world environment.
The researchers apply this LDR framework to the problem of <a href="https://aimodels.fyi/papers/arxiv/scalable-distributed-algorithms-size-constrained-submodular-maximization">submodular multi-task subset selection</a>. Submodular functions are a class of set functions that exhibit a diminishing returns property, making them useful for modeling various optimization problems in machine learning and beyond.
By combining the LDR approach with submodular optimization, the researchers develop a method that can efficiently select a robust subset of items or features, even when faced with uncertainty about the true data distributions across multiple tasks.
Technical Explanation
The paper introduces a novel localized distributional robustness (LDR) framework for the problem of submodular multi-task subset selection. The key idea is to find a subset of items or features that maximizes a submodular function while being robust to potential shifts in the underlying data distributions across multiple tasks.
Formally, the researchers consider a setting with m tasks, each with an associated submodular function f_i and a nominal data distribution P_i. The goal is to select a k-sized subset S that maximizes the localized distributional robust (LDR) objective:
<a href="https://aimodels.fyi/papers/arxiv/demand-sampling-learning-optimally-from-multiple-distributions">max_S min_Q Σ_i w_i * f_i(S)</a>
where Q is a set of plausible data distributions and w_i are task-specific weights. This objective encourages finding a subset S that performs well across the range of possible data distributions, rather than optimizing for a single fixed distribution.
The researchers develop an efficient greedy algorithm to approximately solve this LDR optimization problem, with strong theoretical guarantees on the solution quality. They also show how the LDR framework can be extended to handle correlated tasks and budget constraints on the subset size.
Experiments on real-world datasets demonstrate the effectiveness of the LDR approach compared to baseline methods that do not explicitly account for distributional robustness. The LDR-based subset selection outperforms alternatives in terms of maintaining high performance across a range of test distributions, showcasing the practical benefits of this new framework.
Critical Analysis
The paper makes a compelling case for the importance of distributional robustness in subset selection problems, particularly in the context of submodular multi-task optimization. The LDR framework provides a principled way to find subsets that are reliable and less sensitive to changes in the data environment.
One potential limitation is the computational complexity of the greedy algorithm, which may become prohibitive for very large-scale problems. The researchers mention that further scalability improvements could be an area for future work.
Additionally, the paper focuses on the case of known nominal distributions P_i for each task. In practice, these distributions may not be fully known, and the framework would need to be extended to handle more general uncertainty models.
Another avenue for future research could be to explore the connections between the LDR approach and other robust optimization techniques, such as <a href="https://aimodels.fyi/papers/arxiv/distributionally-robust-policy-lyapunov-certificate-learning">distributionally robust reinforcement learning</a> or <a href="https://aimodels.fyi/papers/arxiv/resource-aware-collaborative-monte-carlo-localization-distribution">resource-aware collaborative localization</a>. Combining insights from these related areas could lead to further advancements in the field of robust subset selection.
Conclusion
This paper presents a novel localized distributional robustness (LDR) framework for submodular multi-task subset selection, a problem with important applications in machine learning and beyond. By optimizing for performance across a range of plausible data distributions, the LDR approach can find subsets that are more reliable and less sensitive to real-world distributional shifts.
The researchers demonstrate the effectiveness of their approach through theoretical analysis and experiments, showcasing the practical benefits of this new framework. The LDR technique represents an important step forward in developing robust and adaptable machine learning systems that can maintain high performance in the face of changing environments and data distributions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Taking a Moment for Distributional Robustness
Jabari Hastings, Christopher Jung, Charlotte Peale, Vasilis Syrgkanis
0
0
A rich line of recent work has studied distributionally robust learning approaches that seek to learn a hypothesis that performs well, in the worst-case, on many different distributions over a population. We argue that although the most common approaches seek to minimize the worst-case loss over distributions, a more reasonable goal is to minimize the worst-case distance to the true conditional expectation of labels given each covariate. Focusing on the minmax loss objective can dramatically fail to output a solution minimizing the distance to the true conditional expectation when certain distributions contain high levels of label noise. We introduce a new min-max objective based on what is known as the adversarial moment violation and show that minimizing this objective is equivalent to minimizing the worst-case $ell_2$-distance to the true conditional expectation if we take the adversary's strategy space to be sufficiently rich. Previous work has suggested minimizing the maximum regret over the worst-case distribution as a way to circumvent issues arising from differential noise levels. We show that in the case of square loss, minimizing the worst-case regret is also equivalent to minimizing the worst-case $ell_2$-distance to the true conditional expectation. Although their objective and our objective both minimize the worst-case distance to the true conditional expectation, we show that our approach provides large empirical savings in computational cost in terms of the number of groups, while providing the same noise-oblivious worst-distribution guarantee as the minimax regret approach, thus making positive progress on an open question posed by Agarwal and Zhang (2022).
5/10/2024
Consistent Submodular Maximization
Paul Dutting, Federico Fusco, Silvio Lattanzi, Ashkan Norouzi-Fard, Morteza Zadimoghaddam
0
0
Maximizing monotone submodular functions under cardinality constraints is a classic optimization task with several applications in data mining and machine learning. In this paper we study this problem in a dynamic environment with consistency constraints: elements arrive in a streaming fashion and the goal is maintaining a constant approximation to the optimal solution while having a stable solution (i.e., the number of changes between two consecutive solutions is bounded). We provide algorithms in this setting with different trade-offs between consistency and approximation quality. We also complement our theoretical results with an experimental analysis showing the effectiveness of our algorithms in real-world instances.
5/31/2024
🗣️
Stackelberg Games with $k$-Submodular Function under Distributional Risk-Receptiveness and Robustness
Seonghun Park, Manish Bansal
0
0
We study submodular optimization in adversarial context, applicable to machine learning problems such as feature selection using data susceptible to uncertainties and attacks. We focus on Stackelberg games between an attacker (or interdictor) and a defender where the attacker aims to minimize the defender's objective of maximizing a $k$-submodular function. We allow uncertainties arising from the success of attacks and inherent data noise, and address challenges due to incomplete knowledge of the probability distribution of random parameters. Specifically, we introduce Distributionally Risk-Averse $k$-Submodular Interdiction Problem (DRA $k$-SIP) and Distributionally Risk-Receptive $k$-Submodular Interdiction Problem (DRR $k$-SIP) along with finitely convergent exact algorithms for solving them. The DRA $k$-SIP solution allows risk-averse interdictor to develop robust strategies for real-world uncertainties. Conversely, DRR $k$-SIP solution suggests aggressive tactics for attackers, willing to embrace (distributional) risk to inflict maximum damage, identifying critical vulnerable components, which can be used for the defender's defensive strategies. The optimal values derived from both DRA $k$-SIP and DRR $k$-SIP offer a confidence interval-like range for the expected value of the defender's objective function, capturing distributional ambiguity. We conduct computational experiments using instances of feature selection and sensor placement problems, and Wisconsin breast cancer data and synthetic data, respectively.
7/2/2024
🧪
Submodular Information Selection for Hypothesis Testing with Misclassification Penalties
Jayanth Bhargav, Mahsa Ghasemi, Shreyas Sundaram
0
0
We consider the problem of selecting an optimal subset of information sources for a hypothesis testing/classification task where the goal is to identify the true state of the world from a finite set of hypotheses, based on finite observation samples from the sources. In order to characterize the learning performance, we propose a misclassification penalty framework, which enables nonuniform treatment of different misclassification errors. In a centralized Bayesian learning setting, we study two variants of the subset selection problem: (i) selecting a minimum cost information set to ensure that the maximum penalty of misclassifying the true hypothesis is below a desired bound and (ii) selecting an optimal information set under a limited budget to minimize the maximum penalty of misclassifying the true hypothesis. Under certain assumptions, we prove that the objective (or constraints) of these combinatorial optimization problems are weak (or approximate) submodular, and establish high-probability performance guarantees for greedy algorithms. Further, we propose an alternate metric for information set selection which is based on the total penalty of misclassification. We prove that this metric is submodular and establish near-optimal guarantees for the greedy algorithms for both the information set selection problems. Finally, we present numerical simulations to validate our theoretical results over several randomly generated instances.
7/1/2024