Submodular Information Selection for Hypothesis Testing with Misclassification Penalties
2405.10930
0
0
🧪
Abstract
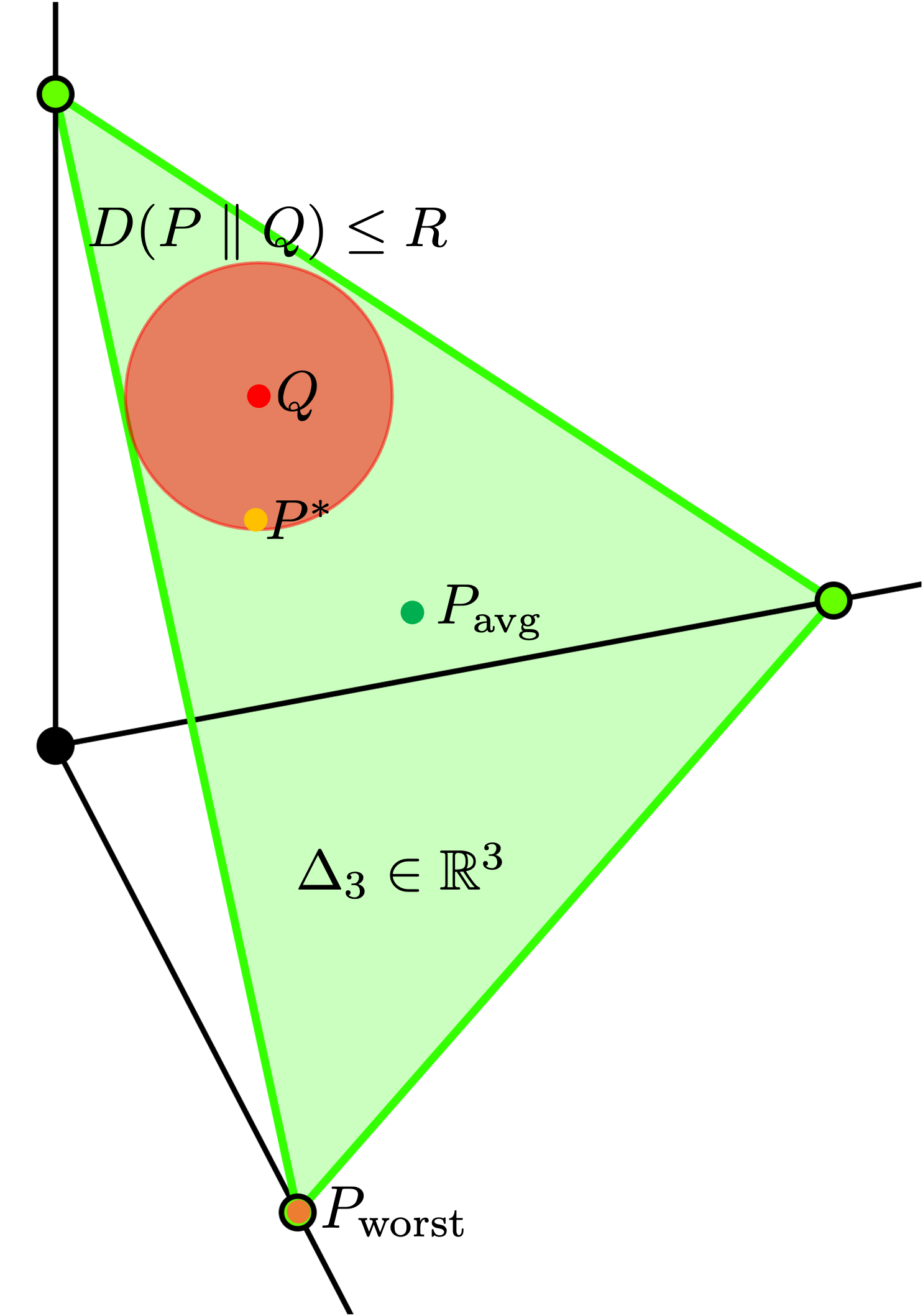
We consider the problem of selecting an optimal subset of information sources for a hypothesis testing/classification task where the goal is to identify the true state of the world from a finite set of hypotheses, based on finite observation samples from the sources. In order to characterize the learning performance, we propose a misclassification penalty framework, which enables nonuniform treatment of different misclassification errors. In a centralized Bayesian learning setting, we study two variants of the subset selection problem: (i) selecting a minimum cost information set to ensure that the maximum penalty of misclassifying the true hypothesis is below a desired bound and (ii) selecting an optimal information set under a limited budget to minimize the maximum penalty of misclassifying the true hypothesis. Under certain assumptions, we prove that the objective (or constraints) of these combinatorial optimization problems are weak (or approximate) submodular, and establish high-probability performance guarantees for greedy algorithms. Further, we propose an alternate metric for information set selection which is based on the total penalty of misclassification. We prove that this metric is submodular and establish near-optimal guarantees for the greedy algorithms for both the information set selection problems. Finally, we present numerical simulations to validate our theoretical results over several randomly generated instances.
Create account to get full access
Overview
- The paper addresses the problem of selecting an optimal subset of information sources for a hypothesis testing or classification task.
- The goal is to identify the true state of the world from a finite set of hypotheses, based on finite observation samples from the information sources.
- The authors propose a misclassification penalty framework to characterize the learning performance, which allows for non-uniform treatment of different misclassification errors.
- In a centralized Bayesian learning setting, two variants of the subset selection problem are studied: (i) selecting a minimum cost information set to bound the maximum penalty of misclassifying the true hypothesis, and (ii) selecting an optimal information set under a limited budget to minimize the maximum penalty of misclassification.
Plain English Explanation
Imagine you're trying to figure out the true state of the world (e.g., the weather, a disease outbreak, or the state of the economy) from a limited set of possible hypotheses. You have access to various information sources (e.g., weather reports, medical tests, economic indicators) that can provide you with samples or observations to help you make this determination.
The challenge is that some misclassification errors (e.g., wrongly identifying a pandemic as the flu) may be more costly than others (e.g., mistaking a light rain for a drizzle). The researchers in this paper propose a way to account for these different costs, or "penalties," of making the wrong decision.
They then look at two specific problems: 1) Finding the minimum set of information sources needed to ensure the maximum penalty of a wrong decision is bounded, and 2) Selecting the optimal set of information sources under a limited budget to minimize the maximum penalty of a wrong decision.
The researchers show that these problems have certain mathematical properties that allow them to use efficient "greedy" algorithms to solve them. They also propose an alternative metric based on the total penalty of all misclassifications, which they prove is even more well-behaved mathematically.
Technical Explanation
The paper presents a Bayesian learning framework for the problem of selecting an optimal subset of information sources for hypothesis testing or classification. The authors introduce a misclassification penalty function that allows for non-uniform treatment of different types of errors.
In the centralized setting, two variants of the subset selection problem are studied. The first is to select a minimum cost information set that ensures the maximum penalty of misclassifying the true hypothesis is bounded. The second is to select an optimal information set under a limited budget to minimize the maximum penalty of misclassification.
The authors prove that the objective (or constraints) of these combinatorial optimization problems are weak (or approximate) submodular. This allows them to establish high-probability performance guarantees for greedy algorithms in solving these problems.
Additionally, the paper proposes an alternative metric based on the total penalty of misclassification, which is shown to be submodular. This leads to near-optimal guarantees for greedy algorithms in both information set selection problems.
The theoretical results are validated through numerical simulations on randomly generated instances.
Critical Analysis
The paper presents a well-structured and theoretically rigorous approach to the problem of optimal information source selection for hypothesis testing and classification. The use of the misclassification penalty framework is a clever way to capture the nuanced costs of different types of errors, which is an important practical consideration.
One potential limitation is the assumption of a centralized Bayesian learning setting, which may not always be realistic in real-world scenarios. It would be interesting to see how the proposed methods could be extended to decentralized or adversarial settings.
Additionally, the paper focuses on establishing mathematical guarantees for the greedy algorithms, but does not provide much insight into the practical performance of these algorithms compared to other potential approaches. It would be valuable to see a more comprehensive empirical evaluation, perhaps on real-world datasets, to better understand the strengths and limitations of the proposed techniques.
Finally, the authors mention the possibility of extending the framework to handle correlated sources, which could be an important direction for future research, as real-world information sources are often not independent.
Conclusion
This paper presents a novel framework for optimal information source selection in hypothesis testing and classification tasks, with a focus on accounting for non-uniform misclassification penalties. The authors establish strong theoretical guarantees for greedy algorithms in solving the corresponding combinatorial optimization problems, and also propose an alternative submodular metric that leads to near-optimal solutions.
The techniques developed in this paper could have significant practical implications in a wide range of applications, from medical diagnosis to economic forecasting, where the costs of different types of errors can vary significantly. The paper lays a solid mathematical foundation for further research in this area, with potential extensions to more complex and realistic scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Theoretical Analysis of Submodular Information Measures for Targeted Data Subset Selection
Nathan Beck, Truong Pham, Rishabh Iyer
0
0
With increasing volume of data being used across machine learning tasks, the capability to target specific subsets of data becomes more important. To aid in this capability, the recently proposed Submodular Mutual Information (SMI) has been effectively applied across numerous tasks in literature to perform targeted subset selection with the aid of a exemplar query set. However, all such works are deficient in providing theoretical guarantees for SMI in terms of its sensitivity to a subset's relevance and coverage of the targeted data. For the first time, we provide such guarantees by deriving similarity-based bounds on quantities related to relevance and coverage of the targeted data. With these bounds, we show that the SMI functions, which have empirically shown success in multiple applications, are theoretically sound in achieving good query relevance and query coverage.
6/13/2024
Localized Distributional Robustness in Submodular Multi-Task Subset Selection
Ege C. Kaya, Abolfazl Hashemi
0
0
In this work, we approach the problem of multi-task submodular optimization with the perspective of local distributional robustness, within the neighborhood of a reference distribution which assigns an importance score to each task. We initially propose to introduce a regularization term which makes use of the relative entropy to the standard multi-task objective. We then demonstrate through duality that this novel formulation itself is equivalent to the maximization of a submodular function, which may be efficiently carried out through standard greedy selection methods. This approach bridges the existing gap in the optimization of performance-robustness trade-offs in multi-task subset selection. To numerically validate our theoretical results, we test the proposed method in two different setting, one involving the selection of satellites in low Earth orbit constellations in the context of a sensor selection problem, and the other involving an image summarization task using neural networks. Our method is compared with two other algorithms focused on optimizing the performance of the worst-case task, and on directly optimizing the performance on the reference distribution itself. We conclude that our novel formulation produces a solution that is locally distributional robust, and computationally inexpensive.
4/8/2024
🧠
Enhancing Neural Subset Selection: Integrating Background Information into Set Representations
Binghui Xie, Yatao Bian, Kaiwen zhou, Yongqiang Chen, Peilin Zhao, Bo Han, Wei Meng, James Cheng
0
0
Learning neural subset selection tasks, such as compound selection in AI-aided drug discovery, have become increasingly pivotal across diverse applications. The existing methodologies in the field primarily concentrate on constructing models that capture the relationship between utility function values and subsets within their respective supersets. However, these approaches tend to overlook the valuable information contained within the superset when utilizing neural networks to model set functions. In this work, we address this oversight by adopting a probabilistic perspective. Our theoretical findings demonstrate that when the target value is conditioned on both the input set and subset, it is essential to incorporate an textit{invariant sufficient statistic} of the superset into the subset of interest for effective learning. This ensures that the output value remains invariant to permutations of the subset and its corresponding superset, enabling identification of the specific superset from which the subset originated. Motivated by these insights, we propose a simple yet effective information aggregation module designed to merge the representations of subsets and supersets from a permutation invariance perspective. Comprehensive empirical evaluations across diverse tasks and datasets validate the enhanced efficacy of our approach over conventional methods, underscoring the practicality and potency of our proposed strategies in real-world contexts.
6/11/2024
🔎
Minimum Cost Adaptive Submodular Cover
Hessa Al-Thani, Yubing Cui, Viswanath Nagarajan
0
0
Adaptive submodularity is a fundamental concept in stochastic optimization, with numerous applications such as sensor placement, hypothesis identification and viral marketing. We consider the problem of minimum cost cover of adaptive-submodular functions, and provide a $4(1+ln Q)$-approximation algorithm, where $Q$ is the goal value. In fact, we consider a significantly more general objective of minimizing the $p^{th}$ moment of the coverage cost, and show that our algorithm simultaneously achieves a $(p+1)^{p+1}cdot (ln Q+1)^p$ approximation guarantee for all $pge 1$. All our approximation ratios are best possible up to constant factors (assuming $Pne NP$). Moreover, our results also extend to the setting where one wants to cover {em multiple} adaptive-submodular functions. Finally, we evaluate the empirical performance of our algorithm on instances of hypothesis identification.
5/24/2024