Localized Observation Abstraction Using Piecewise Linear Spatial Decay for Reinforcement Learning in Combat Simulations

0
🏅
Sign in to get full access
Overview
- Combat simulations present significant challenges for training deep reinforcement learning (RL) agents due to their dynamic and complex nature.
- As the complexity of scenarios and available information increases, the training time required to achieve a certain performance threshold can increase exponentially.
- This paper introduces a novel approach to address the limitations of traditional RL methods in high-dimensional, dynamic environments.
Plain English Explanation
The paper focuses on a problem in the field of combat simulations, where training artificial intelligence (AI) agents using reinforcement learning (RL) is particularly challenging. These simulations are highly complex and dynamic, meaning that the environment is constantly changing. As the complexity of the scenarios and the available information increases, the time required to train the RL agents to reach a certain level of performance can grow exponentially.
To address this issue, the researchers propose a new method that simplifies the way the agents perceive their environment, a process known as observation abstraction. Instead of having the agents observe the entire environment, the method focuses on the local area around the agent, using a technique called "piecewise linear spatial decay." This approach reduces the computational demands on the training process while still preserving the essential information the agents need to make decisions.
Technical Explanation
The paper introduces a novel observation abstraction method that addresses the limitations of traditional RL approaches in high-dimensional, dynamic environments. The proposed technique uses a "localized observation" approach, where the agents focus on the areas immediately surrounding them rather than observing the entire environment.
This localized observation is implemented using a piecewise linear spatial decay function, which gradually reduces the agents' awareness of objects and entities as they move further away. This simplifies the state space that the agents need to process, reducing the computational demands while still preserving the essential spatial relationships that are critical in dynamic environments.
The researchers compare the performance of this localized observation approach to a more traditional "global observation" approach, where the agents have a complete view of the environment. Their analysis shows that the localized observation method consistently outperforms the global observation approach as the complexity of the scenarios increases.
Critical Analysis
The paper presents a promising solution to the challenges of training RL agents in complex, dynamic environments. The authors acknowledge that while their approach is effective, there are still areas for further research and improvement.
One potential limitation is that the piecewise linear spatial decay function may not be the optimal way to implement the localized observation approach. There may be other, more sophisticated techniques for selectively focusing the agents' attention that could further improve the training efficiency.
Additionally, the paper only evaluates the approach in the context of combat simulations. It would be interesting to see how the localized observation method might perform in other types of dynamic, high-dimensional environments, such as robotics or autonomous navigation.
Overall, the research described in this paper represents a valuable contribution to the field of RL in dynamic environments. By addressing the fundamental challenge of complexity in training RL agents, the authors have developed a practical solution that could have significant implications for a wide range of applications.
Conclusion
This paper introduces a novel approach to training RL agents in complex, dynamic environments like combat simulations. By using a localized observation method with piecewise linear spatial decay, the researchers have developed a technique that simplifies the state space while preserving essential spatial relationships, leading to improved training efficiency.
The results demonstrate the potential of this approach to overcome the limitations of traditional RL methods in high-dimensional scenarios. While there are still opportunities for further refinement and exploration, this research represents an important step forward in addressing the challenge of complexity in RL agent training.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Localized Observation Abstraction Using Piecewise Linear Spatial Decay for Reinforcement Learning in Combat Simulations
Scotty Black, Christian Darken
In the domain of combat simulations, the training and deployment of deep reinforcement learning (RL) agents still face substantial challenges due to the dynamic and intricate nature of such environments. Unfortunately, as the complexity of the scenarios and available information increases, the training time required to achieve a certain threshold of performance does not just increase, but often does so exponentially. This relationship underscores the profound impact of complexity in training RL agents. This paper introduces a novel approach that addresses this limitation in training artificial intelligence (AI) agents using RL. Traditional RL methods have been shown to struggle in these high-dimensional, dynamic environments due to real-world computational constraints and the known sample inefficiency challenges of RL. To overcome these limitations, we propose a method of localized observation abstraction using piecewise linear spatial decay. This technique simplifies the state space, reducing computational demands while still preserving essential information, thereby enhancing AI training efficiency in dynamic environments where spatial relationships are often critical. Our analysis reveals that this localized observation approach consistently outperforms the more traditional global observation approach across increasing scenario complexity levels. This paper advances the research on observation abstractions for RL, illustrating how localized observation with piecewise linear spatial decay can provide an effective solution to large state representation challenges in dynamic environments.
Read more8/27/2024
🏅
0
Mastering the Digital Art of War: Developing Intelligent Combat Simulation Agents for Wargaming Using Hierarchical Reinforcement Learning
Scotty Black
In today's rapidly evolving military landscape, advancing artificial intelligence (AI) in support of wargaming becomes essential. Despite reinforcement learning (RL) showing promise for developing intelligent agents, conventional RL faces limitations in handling the complexity inherent in combat simulations. This dissertation proposes a comprehensive approach, including targeted observation abstractions, multi-model integration, a hybrid AI framework, and an overarching hierarchical reinforcement learning (HRL) framework. Our localized observation abstraction using piecewise linear spatial decay simplifies the RL problem, enhancing computational efficiency and demonstrating superior efficacy over traditional global observation methods. Our multi-model framework combines various AI methodologies, optimizing performance while still enabling the use of diverse, specialized individual behavior models. Our hybrid AI framework synergizes RL with scripted agents, leveraging RL for high-level decisions and scripted agents for lower-level tasks, enhancing adaptability, reliability, and performance. Our HRL architecture and training framework decomposes complex problems into manageable subproblems, aligning with military decision-making structures. Although initial tests did not show improved performance, insights were gained to improve future iterations. This study underscores AI's potential to revolutionize wargaming, emphasizing the need for continued research in this domain.
Read more8/27/2024
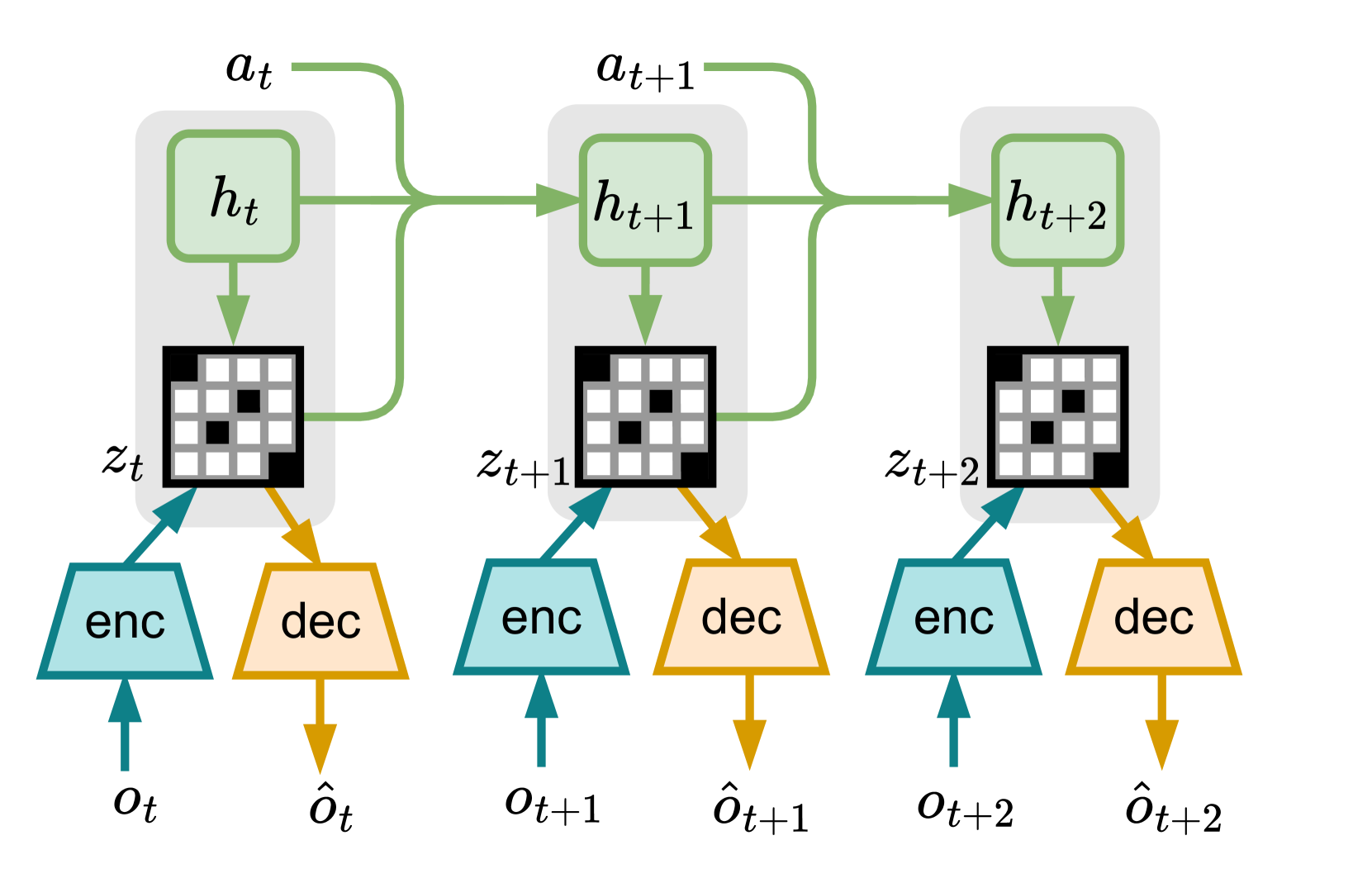
0
Reinforcement Learning from Delayed Observations via World Models
Armin Karamzade, Kyungmin Kim, Montek Kalsi, Roy Fox
In standard reinforcement learning settings, agents typically assume immediate feedback about the effects of their actions after taking them. However, in practice, this assumption may not hold true due to physical constraints and can significantly impact the performance of learning algorithms. In this paper, we address observation delays in partially observable environments. We propose leveraging world models, which have shown success in integrating past observations and learning dynamics, to handle observation delays. By reducing delayed POMDPs to delayed MDPs with world models, our methods can effectively handle partial observability, where existing approaches achieve sub-optimal performance or degrade quickly as observability decreases. Experiments suggest that one of our methods can outperform a naive model-based approach by up to 250%. Moreover, we evaluate our methods on visual delayed environments, for the first time showcasing delay-aware reinforcement learning continuous control with visual observations.
Read more6/27/2024

0
Multi-agent Off-policy Actor-Critic Reinforcement Learning for Partially Observable Environments
Ainur Zhaikhan, Ali H. Sayed
This study proposes the use of a social learning method to estimate a global state within a multi-agent off-policy actor-critic algorithm for reinforcement learning (RL) operating in a partially observable environment. We assume that the network of agents operates in a fully-decentralized manner, possessing the capability to exchange variables with their immediate neighbors. The proposed design methodology is supported by an analysis demonstrating that the difference between final outcomes, obtained when the global state is fully observed versus estimated through the social learning method, is $varepsilon$-bounded when an appropriate number of iterations of social learning updates are implemented. Unlike many existing dec-POMDP-based RL approaches, the proposed algorithm is suitable for model-free multi-agent reinforcement learning as it does not require knowledge of a transition model. Furthermore, experimental results illustrate the efficacy of the algorithm and demonstrate its superiority over the current state-of-the-art methods.
Read more7/9/2024