Dynamic Observation Policies in Observation Cost-Sensitive Reinforcement Learning
2307.02620
0
0

Abstract
Reinforcement learning (RL) has been shown to learn sophisticated control policies for complex tasks including games, robotics, heating and cooling systems and text generation. The action-perception cycle in RL, however, generally assumes that a measurement of the state of the environment is available at each time step without a cost. In applications such as materials design, deep-sea and planetary robot exploration and medicine, however, there can be a high cost associated with measuring, or even approximating, the state of the environment. In this paper, we survey the recently growing literature that adopts the perspective that an RL agent might not need, or even want, a costly measurement at each time step. Within this context, we propose the Deep Dynamic Multi-Step Observationless Agent (DMSOA), contrast it with the literature and empirically evaluate it on OpenAI gym and Atari Pong environments. Our results, show that DMSOA learns a better policy with fewer decision steps and measurements than the considered alternative from the literature.
Create account to get full access
Overview
- This paper explores dynamic observation policies in reinforcement learning, where the agent can choose when to gather observations to balance the cost of observations with the benefit of improved decision-making.
- The authors propose a framework for learning these dynamic observation policies, using a meta-controller that decides when to observe the environment and a base-controller that makes decisions based on the available observations.
- The key idea is to learn the observation policy in a way that optimizes the trade-off between observation cost and task performance, allowing the agent to adaptively choose when to observe.
Plain English Explanation
In reinforcement learning, an agent typically gathers information about its environment through observations, which can help it make better decisions. However, these observations can also be costly, whether in terms of time, energy, or other resources.
The research in this paper explores a way for the agent to learn when it's best to make observations, rather than just observing all the time. The key is to have the agent learn a "meta-controller" that decides when to observe, and a "base-controller" that makes decisions based on the available observations.
By learning this dynamic observation policy, the agent can adaptively choose when to observe, balancing the cost of observations with the benefit of improved decision-making. This could be useful in scenarios where observations are limited or expensive, such as in robotics or autonomous systems.
Technical Explanation
The authors propose a framework for learning dynamic observation policies in reinforcement learning, where the agent can choose when to gather observations to balance the cost of observations with the benefit of improved task performance.
The key components of the framework are:
- Meta-controller: This module decides when to observe the environment, learning a policy that optimizes the trade-off between observation cost and task performance.
- Base-controller: This module makes decisions based on the available observations, using techniques like goal-conditioned policies or smooth guidance.
The authors evaluate their approach on several benchmark tasks, showing that the dynamic observation policies can lead to significant cost savings compared to always observing the environment, while maintaining good task performance.
Critical Analysis
The paper presents a compelling approach to the problem of observation cost-sensitive reinforcement learning, which is an important consideration in many real-world applications. The authors' framework for learning dynamic observation policies is well-designed and the experimental results are promising.
One potential limitation is that the approach may be sensitive to the specific task and environment, and may require careful tuning of the hyperparameters to achieve good performance. Additionally, the authors do not explore the implications of their approach in more complex or partially observable environments, where the trade-off between observation cost and task performance may be even more nuanced.
Further research could explore ways to make the dynamic observation policies more robust and generalizable, as well as investigate the potential for transfer learning or other techniques to improve the sample efficiency of the learning process.
Conclusion
This paper presents an innovative approach to reinforcement learning that allows agents to dynamically choose when to gather observations, balancing the cost of observations with the benefit of improved decision-making. By learning a meta-controller to manage the observation process, the agents can adapt their behavior to the specific task and environment, potentially leading to significant cost savings without sacrificing task performance.
The research has important implications for a wide range of applications, from robotics and autonomous systems to industrial control and beyond. As the field of reinforcement learning continues to advance, techniques like dynamic observation policies will play a crucial role in enabling more efficient and cost-effective AI-powered solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Rich-Observation Reinforcement Learning with Continuous Latent Dynamics
Yuda Song, Lili Wu, Dylan J. Foster, Akshay Krishnamurthy
0
0
Sample-efficiency and reliability remain major bottlenecks toward wide adoption of reinforcement learning algorithms in continuous settings with high-dimensional perceptual inputs. Toward addressing these challenges, we introduce a new theoretical framework, RichCLD (Rich-Observation RL with Continuous Latent Dynamics), in which the agent performs control based on high-dimensional observations, but the environment is governed by low-dimensional latent states and Lipschitz continuous dynamics. Our main contribution is a new algorithm for this setting that is provably statistically and computationally efficient. The core of our algorithm is a new representation learning objective; we show that prior representation learning schemes tailored to discrete dynamics do not naturally extend to the continuous setting. Our new objective is amenable to practical implementation, and empirically, we find that it compares favorably to prior schemes in a standard evaluation protocol. We further provide several insights into the statistical complexity of the RichCLD framework, in particular proving that certain notions of Lipschitzness that admit sample-efficient learning in the absence of rich observations are insufficient in the rich-observation setting.
5/30/2024
🛠️
Variational Delayed Policy Optimization
Qingyuan Wu, Simon Sinong Zhan, Yixuan Wang, Yuhui Wang, Chung-Wei Lin, Chen Lv, Qi Zhu, Chao Huang
0
0
In environments with delayed observation, state augmentation by including actions within the delay window is adopted to retrieve Markovian property to enable reinforcement learning (RL). However, state-of-the-art (SOTA) RL techniques with Temporal-Difference (TD) learning frameworks often suffer from learning inefficiency, due to the significant expansion of the augmented state space with the delay. To improve learning efficiency without sacrificing performance, this work introduces a novel framework called Variational Delayed Policy Optimization (VDPO), which reformulates delayed RL as a variational inference problem. This problem is further modelled as a two-step iterative optimization problem, where the first step is TD learning in the delay-free environment with a small state space, and the second step is behaviour cloning which can be addressed much more efficiently than TD learning. We not only provide a theoretical analysis of VDPO in terms of sample complexity and performance, but also empirically demonstrate that VDPO can achieve consistent performance with SOTA methods, with a significant enhancement of sample efficiency (approximately 50% less amount of samples) in the MuJoCo benchmark.
5/24/2024
📉
A Dual Approach to Imitation Learning from Observations with Offline Datasets
Harshit Sikchi, Caleb Chuck, Amy Zhang, Scott Niekum
0
0
Demonstrations are an effective alternative to task specification for learning agents in settings where designing a reward function is difficult. However, demonstrating expert behavior in the action space of the agent becomes unwieldy when robots have complex, unintuitive morphologies. We consider the practical setting where an agent has a dataset of prior interactions with the environment and is provided with observation-only expert demonstrations. Typical learning from observations approaches have required either learning an inverse dynamics model or a discriminator as intermediate steps of training. Errors in these intermediate one-step models compound during downstream policy learning or deployment. We overcome these limitations by directly learning a multi-step utility function that quantifies how each action impacts the agent's divergence from the expert's visitation distribution. Using the principle of duality, we derive DILO(Dual Imitation Learning from Observations), an algorithm that can leverage arbitrary suboptimal data to learn imitating policies without requiring expert actions. DILO reduces the learning from observations problem to that of simply learning an actor and a critic, bearing similar complexity to vanilla offline RL. This allows DILO to gracefully scale to high dimensional observations, and demonstrate improved performance across the board. Project page (code and videos): $href{https://hari-sikchi.github.io/dilo/}{text{hari-sikchi.github.io/dilo/}}$
6/14/2024
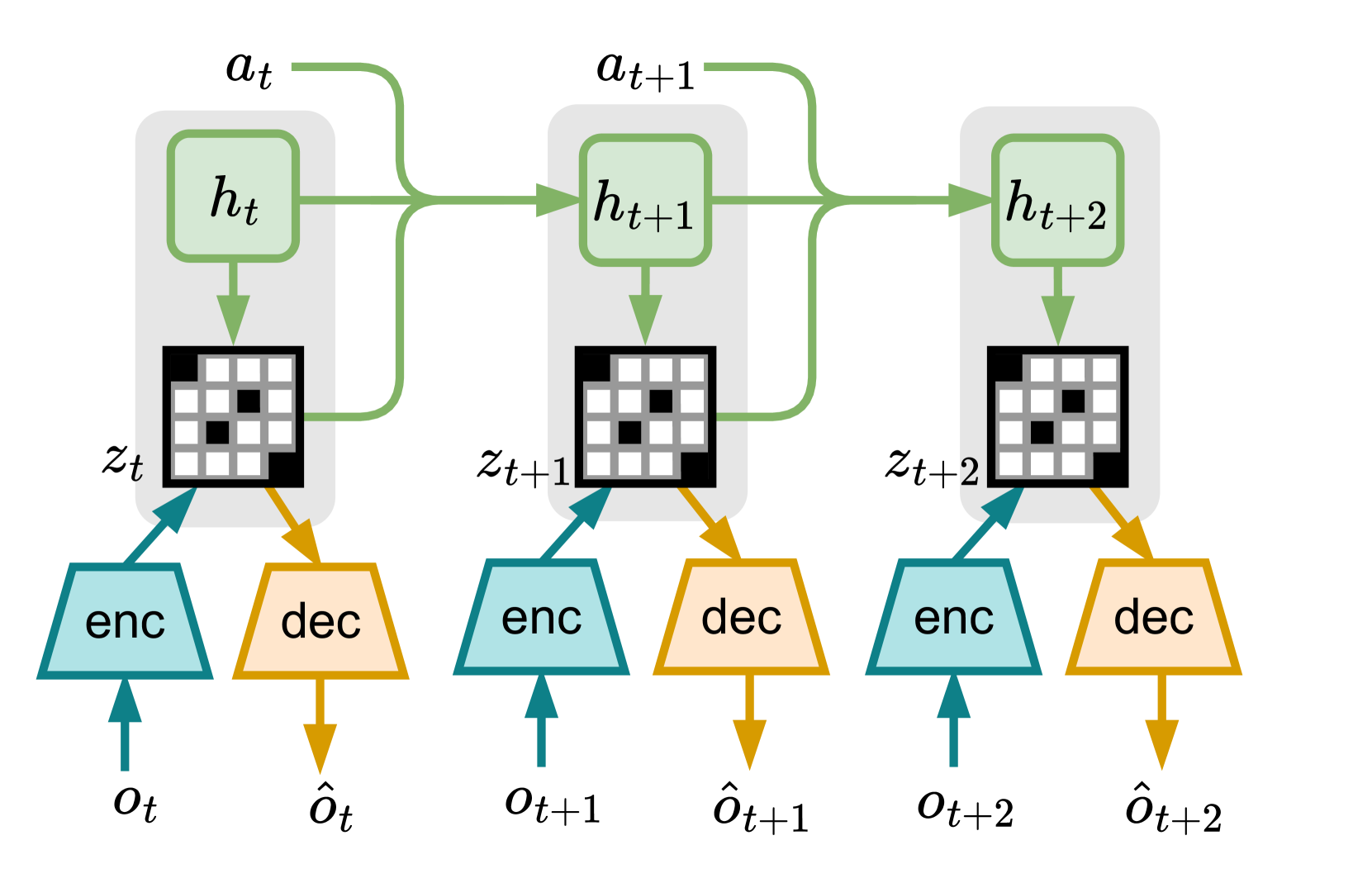
Reinforcement Learning from Delayed Observations via World Models
Armin Karamzade, Kyungmin Kim, Montek Kalsi, Roy Fox
0
0
In standard reinforcement learning settings, agents typically assume immediate feedback about the effects of their actions after taking them. However, in practice, this assumption may not hold true due to physical constraints and can significantly impact the performance of learning algorithms. In this paper, we address observation delays in partially observable environments. We propose leveraging world models, which have shown success in integrating past observations and learning dynamics, to handle observation delays. By reducing delayed POMDPs to delayed MDPs with world models, our methods can effectively handle partial observability, where existing approaches achieve sub-optimal performance or degrade quickly as observability decreases. Experiments suggest that one of our methods can outperform a naive model-based approach by up to 250%. Moreover, we evaluate our methods on visual delayed environments, for the first time showcasing delay-aware reinforcement learning continuous control with visual observations.
6/27/2024