Localizing Task Information for Improved Model Merging and Compression
2405.07813
0
0
📈
Abstract
Model merging and task arithmetic have emerged as promising scalable approaches to merge multiple single-task checkpoints to one multi-task model, but their applicability is reduced by significant performance loss. Previous works have linked these drops to interference in the weight space and erasure of important task-specific features. Instead, in this work we show that the information required to solve each task is still preserved after merging as different tasks mostly use non-overlapping sets of weights. We propose TALL-masks, a method to identify these task supports given a collection of task vectors and show that one can retrieve >99% of the single task accuracy by applying our masks to the multi-task vector, effectively compressing the individual checkpoints. We study the statistics of intersections among constructed masks and reveal the existence of selfish and catastrophic weights, i.e., parameters that are important exclusively to one task and irrelevant to all tasks but detrimental to multi-task fusion. For this reason, we propose Consensus Merging, an algorithm that eliminates such weights and improves the general performance of existing model merging approaches. Our experiments in vision and NLP benchmarks with up to 20 tasks, show that Consensus Merging consistently improves existing approaches. Furthermore, our proposed compression scheme reduces storage from 57Gb to 8.2Gb while retaining 99.7% of original performance.
Create account to get full access
Overview
- This paper presents a novel approach called "Consensus Merging" to address the performance loss that occurs when merging multiple single-task AI models into a single multi-task model.
- The authors show that the key information required to solve each task is still preserved after merging, as different tasks mostly use non-overlapping sets of model weights.
- They propose "TALL-masks" to identify these task-specific weight sets and use them to retrieve over 99% of the original single-task accuracy in a compressed multi-task model.
- The paper also reveals the existence of "selfish" and "catastrophic" weights that are important to only one task but detrimental to the overall multi-task performance, which their Consensus Merging algorithm aims to eliminate.
Plain English Explanation
Imagine you have a bunch of AI models, each trained to do a specific task really well, like classifying images, answering questions, or translating languages. Wouldn't it be great if you could take all those models and merge them into one super-model that can do all those tasks? This work explores ways to do that.
The authors show that even after merging, the key information needed to solve each individual task is still preserved in the combined model. They developed a method called "TALL-masks" that can identify the specific set of model weights (parameters) that are important for each task. By applying these task-specific masks, they can retrieve over 99% of the original single-task performance in the merged multi-task model.
However, the authors also found that there are some model weights that are important for only one task but actually harmful for the overall multi-task performance. They call these "selfish" and "catastrophic" weights. To address this, they propose an algorithm called "Consensus Merging" that can eliminate these problematic weights and improve the general performance of the merged model.
In their experiments, the Consensus Merging approach consistently outperformed other existing model merging methods, while also reducing the total storage required for the multi-task model by over 85% without sacrificing much performance.
Technical Explanation
This paper introduces a novel approach called "Consensus Merging" to address the significant performance loss that often occurs when merging multiple single-task AI model checkpoints into a single multi-task model.
Previous works, such as Model Merging and Task Arithmetic, have explored scalable techniques for model merging. However, these methods have been limited by substantial drops in performance. The authors link these performance issues to interference in the weight space and the erasure of important task-specific features.
In contrast, this work shows that the key information required to solve each task is actually still preserved after merging, as different tasks mostly use non-overlapping sets of model weights. The authors propose a method called "TALL-masks" to identify these task-specific weight supports, and demonstrate that one can retrieve over 99% of the single-task accuracy by applying these masks to the merged multi-task model, effectively compressing the individual checkpoints.
Furthermore, the paper reveals the existence of "selfish" and "catastrophic" weights - parameters that are important exclusively to one task but irrelevant or even detrimental to the overall multi-task performance. To address this, the authors introduce "Consensus Merging," an algorithm that eliminates such problematic weights and improves the general performance of existing model merging approaches.
Experiments on vision and natural language processing benchmarks with up to 20 tasks show that Consensus Merging consistently outperforms other merging methods. Additionally, the proposed compression scheme using TALL-masks reduces the total storage requirement from 57GB to just 8.2GB while retaining 99.7% of the original performance.
Critical Analysis
The authors provide a compelling approach to address the performance degradation issues that have limited the practical applicability of model merging techniques. By identifying and leveraging the task-specific weight supports, they are able to achieve impressive compression rates while maintaining near-original single-task performance.
However, the paper does not delve into the potential limitations or caveats of their methods. For example, it's unclear how the Consensus Merging algorithm would scale or perform when dealing with an even larger number of tasks or more complex models. Additionally, the reliance on task-specific weight masks may introduce new challenges, such as the need for a priori knowledge of the task relationships or the ability to accurately identify the task-specific weight supports.
Further research could explore the robustness of these techniques in more diverse and realistic scenarios, such as when tasks are added or removed over time, or when the tasks exhibit stronger interdependencies. Investigating the computational and memory efficiency of the proposed methods would also be valuable, as model size and inference latency are critical considerations for many real-world applications.
Overall, this work presents a promising direction for improving the scalability and performance of multi-task learning, and the authors' insights into the nature of task-specific weight supports and the existence of "selfish" and "catastrophic" weights offer valuable contributions to the field. Continued exploration and refinement of these ideas could lead to even more powerful and practical multi-task AI systems.
Conclusion
This paper introduces a novel approach called "Consensus Merging" to address the significant performance loss that often occurs when merging multiple single-task AI models into a single multi-task model. The key insights are:
- The information required to solve each task is largely preserved after merging, as different tasks mostly use non-overlapping sets of model weights.
- The authors' proposed "TALL-masks" method can identify these task-specific weight supports, enabling the retrieval of over 99% of single-task accuracy in a compressed multi-task model.
- The paper also reveals the existence of "selfish" and "catastrophic" weights - parameters that are important to only one task but detrimental to the overall multi-task performance. The Consensus Merging algorithm aims to eliminate these problematic weights.
Experiments show that Consensus Merging consistently outperforms other merging approaches, while also dramatically reducing the storage requirements of the multi-task model. This work represents a significant step forward in enabling more scalable and efficient multi-task learning, with potential applications in a wide range of AI-powered systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
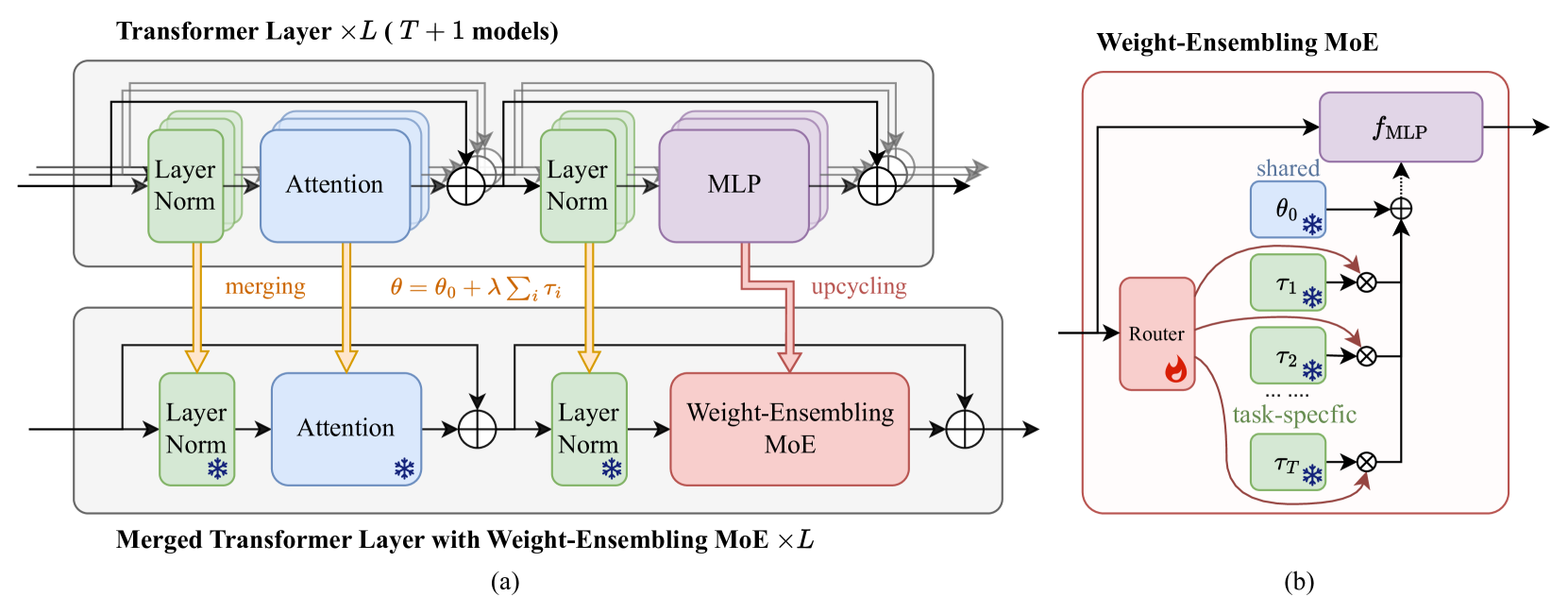
Merging Multi-Task Models via Weight-Ensembling Mixture of Experts
Anke Tang, Li Shen, Yong Luo, Nan Yin, Lefei Zhang, Dacheng Tao
0
0
Merging various task-specific Transformer-based models trained on different tasks into a single unified model can execute all the tasks concurrently. Previous methods, exemplified by task arithmetic, have been proven to be both effective and scalable. Existing methods have primarily focused on seeking a static optimal solution within the original model parameter space. A notable challenge is mitigating the interference between parameters of different models, which can substantially deteriorate performance. In this paper, we propose to merge most of the parameters while upscaling the MLP of the Transformer layers to a weight-ensembling mixture of experts (MoE) module, which can dynamically integrate shared and task-specific knowledge based on the input, thereby providing a more flexible solution that can adapt to the specific needs of each instance. Our key insight is that by identifying and separating shared knowledge and task-specific knowledge, and then dynamically integrating them, we can mitigate the parameter interference problem to a great extent. We conduct the conventional multi-task model merging experiments and evaluate the generalization and robustness of our method. The results demonstrate the effectiveness of our method and provide a comprehensive understanding of our method. The code is available at https://github.com/tanganke/weight-ensembling_MoE
6/10/2024
📈
EMR-Merging: Tuning-Free High-Performance Model Merging
Chenyu Huang, Peng Ye, Tao Chen, Tong He, Xiangyu Yue, Wanli Ouyang
0
0
The success of pretrain-finetune paradigm brings about the release of numerous model weights. In this case, merging models finetuned on different tasks to enable a single model with multi-task capabilities is gaining increasing attention for its practicability. Existing model merging methods usually suffer from (1) significant performance degradation or (2) requiring tuning by additional data or training. In this paper, we rethink and analyze the existing model merging paradigm. We discover that using a single model's weights can hardly simulate all the models' performance. To tackle this issue, we propose Elect, Mask & Rescale-Merging (EMR-Merging). We first (a) elect a unified model from all the model weights and then (b) generate extremely lightweight task-specific modulators, including masks and rescalers, to align the direction and magnitude between the unified model and each specific model, respectively. EMR-Merging is tuning-free, thus requiring no data availability or any additional training while showing impressive performance. We find that EMR-Merging shows outstanding performance compared to existing merging methods under different classical and newly-established settings, including merging different numbers of vision models (up to 30), NLP models, PEFT models, and multi-modal models.
5/29/2024

Merging by Matching Models in Task Parameter Subspaces
Derek Tam, Mohit Bansal, Colin Raffel
0
0
Model merging aims to cheaply combine individual task-specific models into a single multitask model. In this work, we view past merging methods as leveraging different notions of a ''task parameter subspace'' in which models are matched before being merged. We connect the task parameter subspace of a given model to its loss landscape and formalize how this approach to model merging can be seen as solving a linear system of equations. While past work has generally been limited to linear systems that have a closed-form solution, we consider using the conjugate gradient method to find a solution. We show that using the conjugate gradient method can outperform closed-form solutions, enables merging via linear systems that are otherwise intractable to solve, and flexibly allows choosing from a wide variety of initializations and estimates for the ''task parameter subspace''. We ultimately demonstrate that our merging framework called ''Matching Models in their Task Parameter Subspace'' (MaTS) achieves state-of-the-art results in multitask and intermediate-task model merging. We release all of the code and checkpoints used in our work at https://github.com/r-three/mats.
4/16/2024

Twin-Merging: Dynamic Integration of Modular Expertise in Model Merging
Zhenyi Lu, Chenghao Fan, Wei Wei, Xiaoye Qu, Dangyang Chen, Yu Cheng
0
0
In the era of large language models, model merging is a promising way to combine multiple task-specific models into a single multitask model without extra training. However, two challenges remain: (a) interference between different models and (b) heterogeneous data during testing. Traditional model merging methods often show significant performance gaps compared to fine-tuned models due to these issues. Additionally, a one-size-fits-all model lacks flexibility for diverse test data, leading to performance degradation. We show that both shared and exclusive task-specific knowledge are crucial for merging performance, but directly merging exclusive knowledge hinders overall performance. In view of this, we propose Twin-Merging, a method that encompasses two principal stages: (1) modularizing knowledge into shared and exclusive components, with compression to reduce redundancy and enhance efficiency; (2) dynamically merging shared and task-specific knowledge based on the input. This approach narrows the performance gap between merged and fine-tuned models and improves adaptability to heterogeneous data. Extensive experiments on $12$ datasets for both discriminative and generative tasks demonstrate the effectiveness of our method, showing an average improvement of $28.34%$ in absolute normalized score for discriminative tasks and even surpassing the fine-tuned upper bound on the generative tasks. (Our implementation is available in https://github.com/LZY-the-boys/Twin-Mergin.)
6/26/2024