Merging by Matching Models in Task Parameter Subspaces
2312.04339
0
0

Abstract
Model merging aims to cheaply combine individual task-specific models into a single multitask model. In this work, we view past merging methods as leveraging different notions of a ''task parameter subspace'' in which models are matched before being merged. We connect the task parameter subspace of a given model to its loss landscape and formalize how this approach to model merging can be seen as solving a linear system of equations. While past work has generally been limited to linear systems that have a closed-form solution, we consider using the conjugate gradient method to find a solution. We show that using the conjugate gradient method can outperform closed-form solutions, enables merging via linear systems that are otherwise intractable to solve, and flexibly allows choosing from a wide variety of initializations and estimates for the ''task parameter subspace''. We ultimately demonstrate that our merging framework called ''Matching Models in their Task Parameter Subspace'' (MaTS) achieves state-of-the-art results in multitask and intermediate-task model merging. We release all of the code and checkpoints used in our work at https://github.com/r-three/mats.
Create account to get full access
Overview
- This paper proposes a method for merging machine learning models trained on different tasks or datasets by matching them in a shared task subspace.
- The approach aims to combine the strengths of multiple models to improve overall performance, while avoiding the challenges of training a single model on diverse tasks.
- The authors evaluate their method on several benchmark datasets and show it can outperform standard model averaging techniques.
Plain English Explanation
Machine learning models are often trained on specific tasks or datasets, which can make it difficult to apply them more broadly. Merging by Matching Models in Task Subspaces presents a way to combine the knowledge of multiple specialized models to create a more general, high-performing model.
The key idea is to find a shared "task subspace" that captures the essential features common to the different tasks. By aligning the models in this subspace, their strengths can be merged without the challenges of training a single model on diverse data. This allows the combined model to leverage the specialized knowledge of the individual models while avoiding the pitfalls of trying to learn everything at once.
The authors demonstrate their approach on several benchmarks and show it can outperform simpler model averaging techniques. This suggests the method may be a useful tool for building more capable and versatile machine learning systems by intelligently combining the knowledge from multiple specialized models.
Technical Explanation
The paper introduces a model merging technique called "Merging by Matching Models in Task Subspaces". The core idea is to find a shared "task subspace" that captures the essential features common to the different tasks the models were trained on.
By aligning the models in this subspace, their strengths can be combined while avoiding the challenges of training a single model on diverse data. This is done by:
- Learning a linear projection from the original model parameters to the task subspace.
- Matching the models in the task subspace using a loss function that encourages the models to produce similar outputs for the same inputs.
- Updating the models using gradient descent on this loss to bring them into alignment.
The authors evaluate this approach on several benchmark datasets, including one-step late fusion multi-view clustering, parametric task map elites, and how does multi-task training affect transformer. They show the merged model can outperform simpler averaging techniques, suggesting the method is a promising way to combine the specialized knowledge of multiple models.
Critical Analysis
The paper presents a thoughtful approach to the challenge of merging specialized machine learning models. By focusing on aligning the models in a shared task subspace, the method avoids some of the difficulties of training a single model on diverse data.
However, the paper does not fully address potential limitations of the approach. For example, the linear projection used to map the models to the task subspace may not be expressive enough to capture all the relevant interactions between features. Exploration Search Space Gaussian Graphical Models Paired suggests more flexible non-linear mappings may be beneficial in some cases.
Additionally, the paper does not explore how the method would scale to merging a large number of models, or how it would perform on Transforming LLMs Into Cross-Modal Cross-Lingual tasks that require more complex reasoning. Further research would be needed to understand the full capabilities and limitations of this approach.
Overall, the paper presents a promising technique for model merging, but there are still open questions and areas for potential improvement. Readers should consider these caveats when evaluating the significance and applicability of the research.
Conclusion
Merging by Matching Models in Task Subspaces introduces an innovative approach to combining the strengths of multiple specialized machine learning models. By aligning the models in a shared task subspace, the method can leverage their specialized knowledge without the challenges of training a single model on diverse data.
The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing it can outperform simpler averaging techniques. This suggests the method may be a useful tool for building more capable and versatile machine learning systems by intelligently merging the knowledge from multiple specialized models.
While the paper presents a thoughtful solution, there are still open questions and potential limitations that warrant further research. Nonetheless, the core idea of merging models by aligning them in a shared task subspace is a promising direction that could have significant implications for the field of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Localizing Task Information for Improved Model Merging and Compression
Ke Wang, Nikolaos Dimitriadis, Guillermo Ortiz-Jimenez, Franc{c}ois Fleuret, Pascal Frossard
0
0
Model merging and task arithmetic have emerged as promising scalable approaches to merge multiple single-task checkpoints to one multi-task model, but their applicability is reduced by significant performance loss. Previous works have linked these drops to interference in the weight space and erasure of important task-specific features. Instead, in this work we show that the information required to solve each task is still preserved after merging as different tasks mostly use non-overlapping sets of weights. We propose TALL-masks, a method to identify these task supports given a collection of task vectors and show that one can retrieve >99% of the single task accuracy by applying our masks to the multi-task vector, effectively compressing the individual checkpoints. We study the statistics of intersections among constructed masks and reveal the existence of selfish and catastrophic weights, i.e., parameters that are important exclusively to one task and irrelevant to all tasks but detrimental to multi-task fusion. For this reason, we propose Consensus Merging, an algorithm that eliminates such weights and improves the general performance of existing model merging approaches. Our experiments in vision and NLP benchmarks with up to 20 tasks, show that Consensus Merging consistently improves existing approaches. Furthermore, our proposed compression scheme reduces storage from 57Gb to 8.2Gb while retaining 99.7% of original performance.
5/14/2024
📈
AdaMerging: Adaptive Model Merging for Multi-Task Learning
Enneng Yang, Zhenyi Wang, Li Shen, Shiwei Liu, Guibing Guo, Xingwei Wang, Dacheng Tao
0
0
Multi-task learning (MTL) aims to empower a model to tackle multiple tasks simultaneously. A recent development known as task arithmetic has revealed that several models, each fine-tuned for distinct tasks, can be directly merged into a single model to execute MTL without necessitating a retraining process using the initial training data. Nevertheless, this direct addition of models often leads to a significant deterioration in the overall performance of the merged model. This decline occurs due to potential conflicts and intricate correlations among the multiple tasks. Consequently, the challenge emerges of how to merge pre-trained models more effectively without using their original training data. This paper introduces an innovative technique called Adaptive Model Merging (AdaMerging). This approach aims to autonomously learn the coefficients for model merging, either in a task-wise or layer-wise manner, without relying on the original training data. Specifically, our AdaMerging method operates as an automatic, unsupervised task arithmetic scheme. It leverages entropy minimization on unlabeled test samples from the multi-task setup as a surrogate objective function to iteratively refine the merging coefficients of the multiple models. Our experimental findings across eight tasks demonstrate the efficacy of the AdaMerging scheme we put forth. Compared to the current state-of-the-art task arithmetic merging scheme, AdaMerging showcases a remarkable 11% improvement in performance. Notably, AdaMerging also exhibits superior generalization capabilities when applied to unseen downstream tasks. Furthermore, it displays a significantly enhanced robustness to data distribution shifts that may occur during the testing phase.
5/29/2024

It's Morphing Time: Unleashing the Potential of Multiple LLMs via Multi-objective Optimization
Bingdong Li, Zixiang Di, Yanting Yang, Hong Qian, Peng Yang, Hao Hao, Ke Tang, Aimin Zhou
0
0
In this paper, we introduce a novel approach for large language model merging via black-box multi-objective optimization algorithms. The goal of model merging is to combine multiple models, each excelling in different tasks, into a single model that outperforms any of the individual source models. However, model merging faces two significant challenges: First, existing methods rely heavily on human intuition and customized strategies. Second, parameter conflicts often arise during merging, and while methods like DARE [1] can alleviate this issue, they tend to stochastically drop parameters, risking the loss of important delta parameters. To address these challenges, we propose the MM-MO method, which automates the search for optimal merging configurations using multi-objective optimization algorithms, eliminating the need for human intuition. During the configuration searching process, we use estimated performance across multiple diverse tasks as optimization objectives in order to alleviate the parameter conflicting between different source models without losing crucial delta parameters. We conducted comparative experiments with other mainstream model merging methods, demonstrating that our method consistently outperforms them. Moreover, our experiments reveal that even task types not explicitly targeted as optimization objectives show performance improvements, indicating that our method enhances the overall potential of the model rather than merely overfitting to specific task types. This approach provides a significant advancement in model merging techniques, offering a robust and plug-and-play solution for integrating diverse models into a unified, high-performing model.
7/2/2024
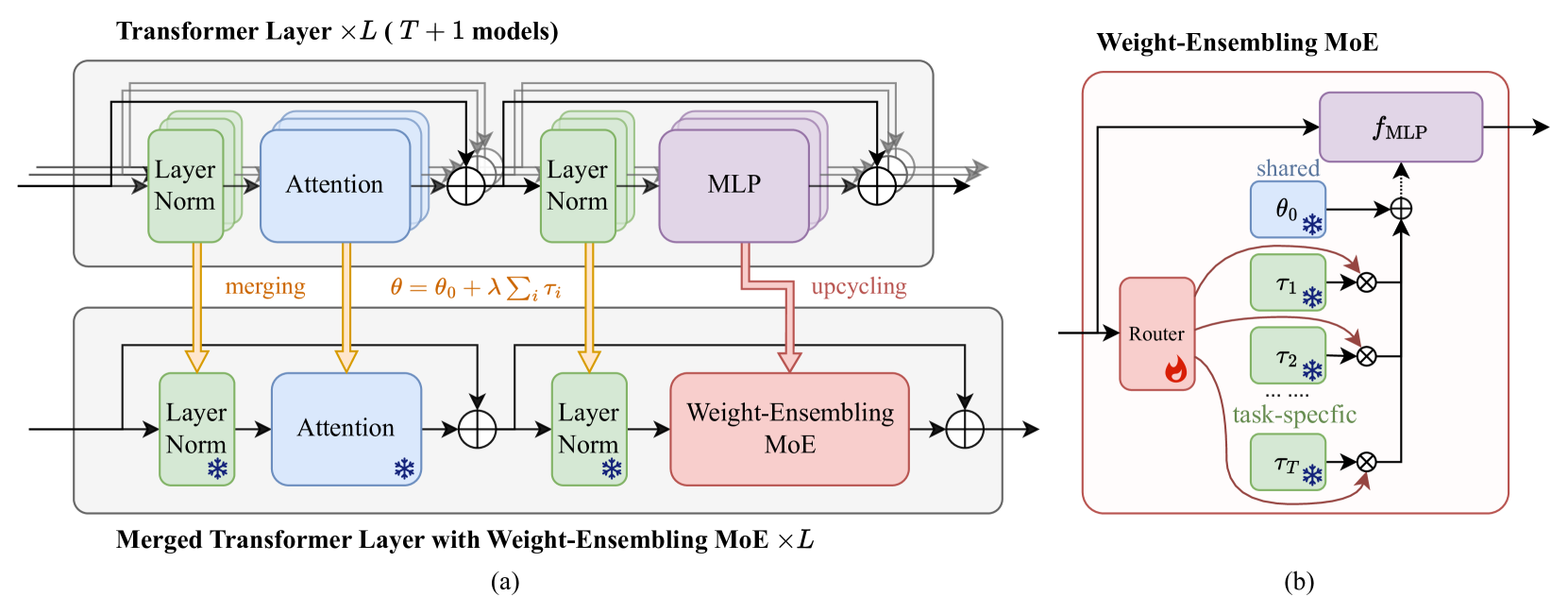
Merging Multi-Task Models via Weight-Ensembling Mixture of Experts
Anke Tang, Li Shen, Yong Luo, Nan Yin, Lefei Zhang, Dacheng Tao
0
0
Merging various task-specific Transformer-based models trained on different tasks into a single unified model can execute all the tasks concurrently. Previous methods, exemplified by task arithmetic, have been proven to be both effective and scalable. Existing methods have primarily focused on seeking a static optimal solution within the original model parameter space. A notable challenge is mitigating the interference between parameters of different models, which can substantially deteriorate performance. In this paper, we propose to merge most of the parameters while upscaling the MLP of the Transformer layers to a weight-ensembling mixture of experts (MoE) module, which can dynamically integrate shared and task-specific knowledge based on the input, thereby providing a more flexible solution that can adapt to the specific needs of each instance. Our key insight is that by identifying and separating shared knowledge and task-specific knowledge, and then dynamically integrating them, we can mitigate the parameter interference problem to a great extent. We conduct the conventional multi-task model merging experiments and evaluate the generalization and robustness of our method. The results demonstrate the effectiveness of our method and provide a comprehensive understanding of our method. The code is available at https://github.com/tanganke/weight-ensembling_MoE
6/10/2024