Twin-Merging: Dynamic Integration of Modular Expertise in Model Merging
2406.15479
0
0

Abstract
In the era of large language models, model merging is a promising way to combine multiple task-specific models into a single multitask model without extra training. However, two challenges remain: (a) interference between different models and (b) heterogeneous data during testing. Traditional model merging methods often show significant performance gaps compared to fine-tuned models due to these issues. Additionally, a one-size-fits-all model lacks flexibility for diverse test data, leading to performance degradation. We show that both shared and exclusive task-specific knowledge are crucial for merging performance, but directly merging exclusive knowledge hinders overall performance. In view of this, we propose Twin-Merging, a method that encompasses two principal stages: (1) modularizing knowledge into shared and exclusive components, with compression to reduce redundancy and enhance efficiency; (2) dynamically merging shared and task-specific knowledge based on the input. This approach narrows the performance gap between merged and fine-tuned models and improves adaptability to heterogeneous data. Extensive experiments on $12$ datasets for both discriminative and generative tasks demonstrate the effectiveness of our method, showing an average improvement of $28.34%$ in absolute normalized score for discriminative tasks and even surpassing the fine-tuned upper bound on the generative tasks. (Our implementation is available in https://github.com/LZY-the-boys/Twin-Mergin.)
Create account to get full access
Overview
- This paper introduces a novel model merging technique called "Twin-Merging" that dynamically integrates modular expertise from multiple models.
- The key idea is to create "twin" models that can learn from each other during the merging process, allowing the merged model to benefit from the specialized knowledge of its component models.
- The authors demonstrate the effectiveness of Twin-Merging on several benchmark tasks, showing improvements over existing model merging approaches.
Plain English Explanation
When you have multiple machine learning models, each trained on a different task or dataset, it can be useful to combine them into a single, more powerful model. This process is called "model merging."
The Twin-Merging technique introduced in this paper aims to make the merging process more effective. Instead of simply averaging or concatenating the models, the authors create "twin" versions of each model that can learn from each other during the merging process.
This allows the merged model to benefit from the specialized knowledge and expertise of its component models, rather than just blending them together. The authors show that this approach outperforms other model merging methods on several benchmark tasks, leading to a more capable and well-rounded final model.
The key insight is that by having the models interact and learn from each other, the merged model can acquire a richer and more integrated understanding of the different tasks and datasets it was trained on. This can lead to better performance and more robust behavior compared to more simplistic model merging techniques.
Technical Explanation
The Twin-Merging approach works by creating "twin" versions of each input model, which are then merged together in a dynamic and iterative fashion.
During the merging process, the twin models are trained to learn from each other, with the goal of integrating the specialized knowledge and expertise of the individual models into the final merged model. This is achieved through a series of cross-attention and knowledge distillation mechanisms, which allow the models to selectively exchange and absorb relevant information.
The authors demonstrate the effectiveness of Twin-Merging on several benchmark tasks, including image classification, natural language processing, and reinforcement learning. They show that the merged models consistently outperform both the individual input models and other model merging techniques, such as AdaMerging and MergeNet.
One key advantage of Twin-Merging is its ability to handle models with different architectural characteristics and task specializations. By dynamically integrating the modular expertise of the input models, the technique can create a merged model that is more capable and well-rounded than a simple ensemble or averaging of the original models.
Critical Analysis
The Twin-Merging paper presents a compelling approach to model merging, but it's important to consider some potential limitations and areas for further research.
One potential concern is the computational and memory overhead of the merging process, as creating and training the twin models may be resource-intensive, especially for large and complex models. The authors acknowledge this issue and suggest that future work could explore ways to optimize the merging process.
Additionally, the paper does not address the potential safety and alignment challenges that can arise when merging models, as discussed in Model Merging: Safety and Alignment. It would be valuable to investigate how the Twin-Merging approach could be adapted to mitigate these concerns.
Another area for further research could be the application of Ensemble Merging and Refinement (EMR) techniques to the Twin-Merging framework, which could potentially lead to even higher-performing and more efficient merged models.
Overall, the Twin-Merging paper presents a promising and novel approach to model merging that could have significant implications for the field of multi-task and transfer learning. By dynamically integrating modular expertise, this technique holds the potential to create more capable and versatile AI models.
Conclusion
The Twin-Merging paper introduces a novel model merging technique that dynamically integrates the modular expertise of multiple input models. By creating "twin" versions of the models that can learn from each other during the merging process, the authors demonstrate significant performance improvements over traditional model merging approaches.
This work highlights the potential benefits of leveraging the specialized knowledge and capabilities of individual models, rather than simply blending or averaging them together. As AI systems continue to grow in complexity and sophistication, techniques like Twin-Merging may become increasingly important for building more capable and well-rounded models that can tackle a diverse range of tasks and challenges.
While the paper presents some exciting results, it also identifies areas for further research, such as optimizing the merging process and addressing safety and alignment concerns. By addressing these challenges, the Twin-Merging approach could pave the way for more efficient and robust model merging techniques that can unlock new frontiers in artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
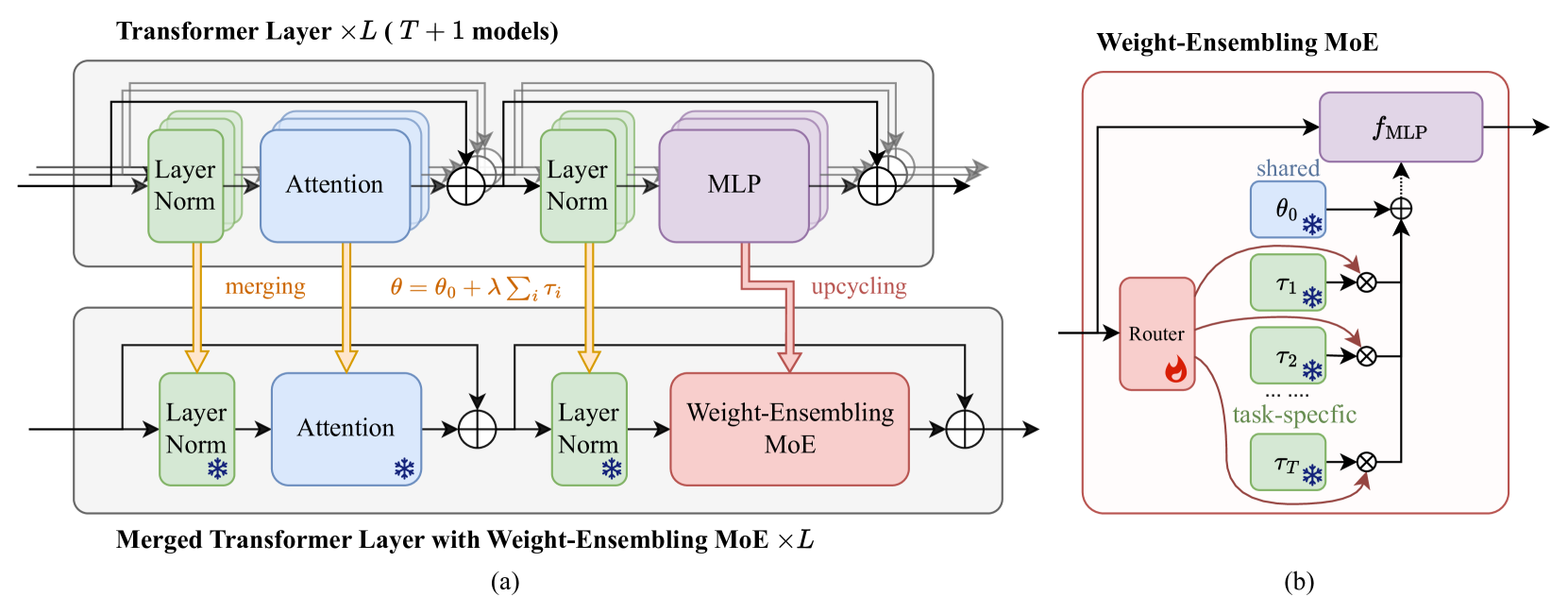
Merging Multi-Task Models via Weight-Ensembling Mixture of Experts
Anke Tang, Li Shen, Yong Luo, Nan Yin, Lefei Zhang, Dacheng Tao
0
0
Merging various task-specific Transformer-based models trained on different tasks into a single unified model can execute all the tasks concurrently. Previous methods, exemplified by task arithmetic, have been proven to be both effective and scalable. Existing methods have primarily focused on seeking a static optimal solution within the original model parameter space. A notable challenge is mitigating the interference between parameters of different models, which can substantially deteriorate performance. In this paper, we propose to merge most of the parameters while upscaling the MLP of the Transformer layers to a weight-ensembling mixture of experts (MoE) module, which can dynamically integrate shared and task-specific knowledge based on the input, thereby providing a more flexible solution that can adapt to the specific needs of each instance. Our key insight is that by identifying and separating shared knowledge and task-specific knowledge, and then dynamically integrating them, we can mitigate the parameter interference problem to a great extent. We conduct the conventional multi-task model merging experiments and evaluate the generalization and robustness of our method. The results demonstrate the effectiveness of our method and provide a comprehensive understanding of our method. The code is available at https://github.com/tanganke/weight-ensembling_MoE
6/10/2024
📈
AdaMerging: Adaptive Model Merging for Multi-Task Learning
Enneng Yang, Zhenyi Wang, Li Shen, Shiwei Liu, Guibing Guo, Xingwei Wang, Dacheng Tao
0
0
Multi-task learning (MTL) aims to empower a model to tackle multiple tasks simultaneously. A recent development known as task arithmetic has revealed that several models, each fine-tuned for distinct tasks, can be directly merged into a single model to execute MTL without necessitating a retraining process using the initial training data. Nevertheless, this direct addition of models often leads to a significant deterioration in the overall performance of the merged model. This decline occurs due to potential conflicts and intricate correlations among the multiple tasks. Consequently, the challenge emerges of how to merge pre-trained models more effectively without using their original training data. This paper introduces an innovative technique called Adaptive Model Merging (AdaMerging). This approach aims to autonomously learn the coefficients for model merging, either in a task-wise or layer-wise manner, without relying on the original training data. Specifically, our AdaMerging method operates as an automatic, unsupervised task arithmetic scheme. It leverages entropy minimization on unlabeled test samples from the multi-task setup as a surrogate objective function to iteratively refine the merging coefficients of the multiple models. Our experimental findings across eight tasks demonstrate the efficacy of the AdaMerging scheme we put forth. Compared to the current state-of-the-art task arithmetic merging scheme, AdaMerging showcases a remarkable 11% improvement in performance. Notably, AdaMerging also exhibits superior generalization capabilities when applied to unseen downstream tasks. Furthermore, it displays a significantly enhanced robustness to data distribution shifts that may occur during the testing phase.
5/29/2024

New!It's Morphing Time: Unleashing the Potential of Multiple LLMs via Multi-objective Optimization
Bingdong Li, Zixiang Di, Yanting Yang, Hong Qian, Peng Yang, Hao Hao, Ke Tang, Aimin Zhou
0
0
In this paper, we introduce a novel approach for large language model merging via black-box multi-objective optimization algorithms. The goal of model merging is to combine multiple models, each excelling in different tasks, into a single model that outperforms any of the individual source models. However, model merging faces two significant challenges: First, existing methods rely heavily on human intuition and customized strategies. Second, parameter conflicts often arise during merging, and while methods like DARE [1] can alleviate this issue, they tend to stochastically drop parameters, risking the loss of important delta parameters. To address these challenges, we propose the MM-MO method, which automates the search for optimal merging configurations using multi-objective optimization algorithms, eliminating the need for human intuition. During the configuration searching process, we use estimated performance across multiple diverse tasks as optimization objectives in order to alleviate the parameter conflicting between different source models without losing crucial delta parameters. We conducted comparative experiments with other mainstream model merging methods, demonstrating that our method consistently outperforms them. Moreover, our experiments reveal that even task types not explicitly targeted as optimization objectives show performance improvements, indicating that our method enhances the overall potential of the model rather than merely overfitting to specific task types. This approach provides a significant advancement in model merging techniques, offering a robust and plug-and-play solution for integrating diverse models into a unified, high-performing model.
7/2/2024

MergeNet: Knowledge Migration across Heterogeneous Models, Tasks, and Modalities
Kunxi Li, Tianyu Zhan, Kairui Fu, Shengyu Zhang, Kun Kuang, Jiwei Li, Zhou Zhao, Fei Wu
0
0
In this study, we focus on heterogeneous knowledge transfer across entirely different model architectures, tasks, and modalities. Existing knowledge transfer methods (e.g., backbone sharing, knowledge distillation) often hinge on shared elements within model structures or task-specific features/labels, limiting transfers to complex model types or tasks. To overcome these challenges, we present MergeNet, which learns to bridge the gap of parameter spaces of heterogeneous models, facilitating the direct interaction, extraction, and application of knowledge within these parameter spaces. The core mechanism of MergeNet lies in the parameter adapter, which operates by querying the source model's low-rank parameters and adeptly learning to identify and map parameters into the target model. MergeNet is learned alongside both models, allowing our framework to dynamically transfer and adapt knowledge relevant to the current stage, including the training trajectory knowledge of the source model. Extensive experiments on heterogeneous knowledge transfer demonstrate significant improvements in challenging settings, where representative approaches may falter or prove less applicable.
6/18/2024