LogicGame: Benchmarking Rule-Based Reasoning Abilities of Large Language Models

0
Sign in to get full access
Overview
- Presents LogicGame, a benchmark to evaluate the rule-based reasoning capabilities of large language models.
- Designed to assess whether LLMs can perform logical inferences and extract insights from textual descriptions of rule-based games.
- Includes a diverse set of game scenarios that require different forms of logical reasoning.
Plain English Explanation
The paper introduces LogicGame, a new benchmark designed to assess the rule-based reasoning abilities of large language models (LLMs). LLMs are AI systems trained on vast amounts of text data, which have shown impressive language understanding and generation capabilities. However, their ability to perform logical reasoning and extract insights from textual descriptions of rule-based scenarios is not well understood.
The LogicGame benchmark includes a variety of game scenarios that require different forms of logical reasoning, such as deductive, inductive, and abductive reasoning. By evaluating LLMs on these tasks, the researchers aim to uncover the strengths and limitations of these models in terms of their strategic and rule-based reasoning abilities. This can help identify areas for improvement and guide the development of more capable AI systems that can engage in complex reasoning and decision-making.
Technical Explanation
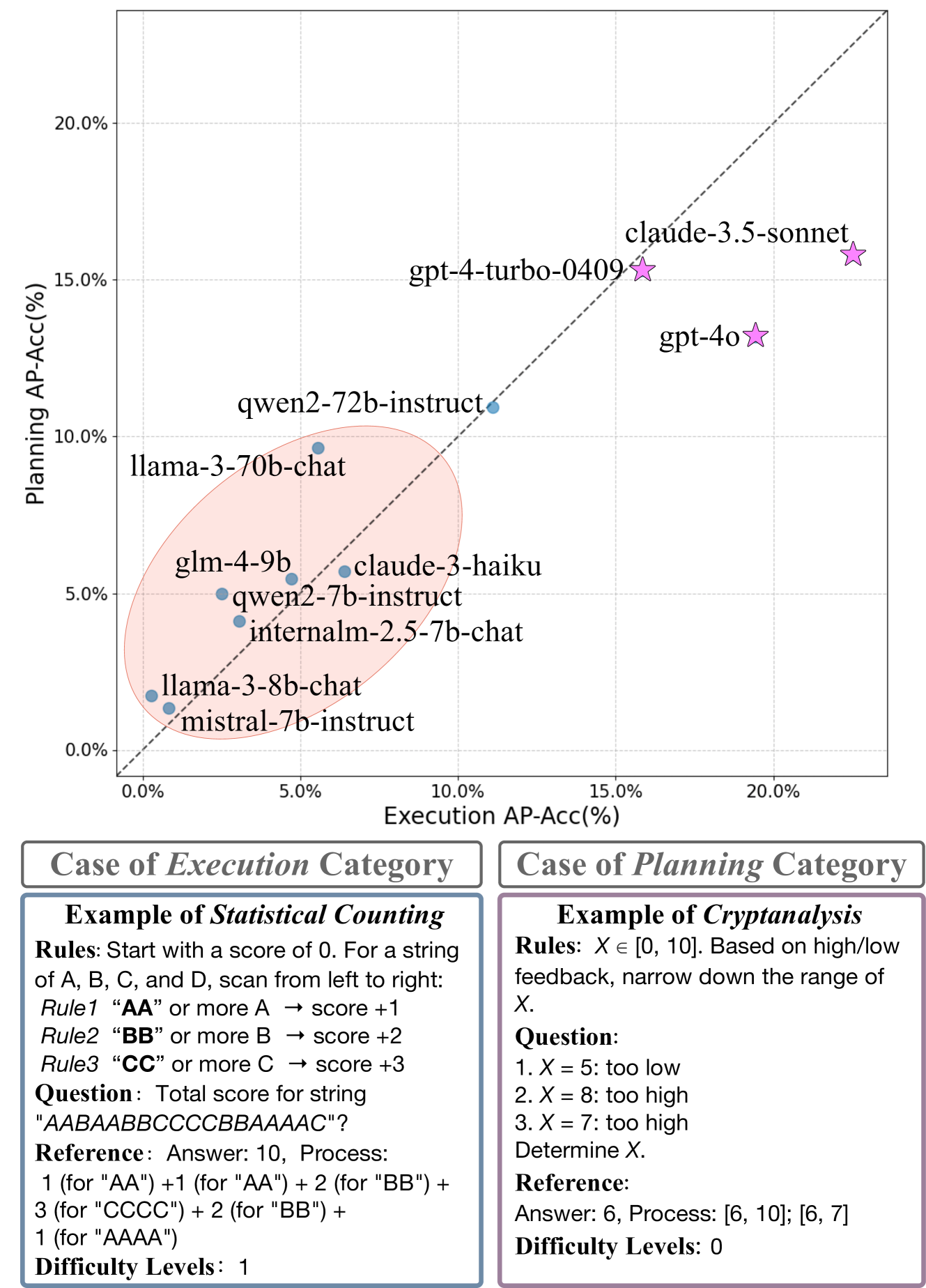
The LogicGame benchmark consists of a diverse set of rule-based game scenarios, each of which is described in natural language. The games cover a range of difficulty levels and reasoning requirements, including deductive logic, spatial reasoning, causal reasoning, and decision-making under uncertainty.
To assess the performance of LLMs on these tasks, the researchers develop a two-stage approach. First, the LLM is presented with the textual description of a game and asked to generate a high-level summary of the rules and objectives. Second, the LLM is asked to answer a series of questions about the game, which require applying the extracted rules and reasoning about the game state.
The researchers evaluate the LLMs' performance on both the summarization and question-answering tasks, using a combination of automated metrics and human evaluation. The results provide insights into the strengths and limitations of different LLM architectures and training approaches in terms of their rule-based reasoning abilities.
Critical Analysis
The LogicGame benchmark represents an important step towards a more comprehensive evaluation of the reasoning capabilities of LLMs. By focusing on rule-based scenarios, the benchmark complements existing language understanding and generation benchmarks, which may not fully capture the models' ability to reason about complex, dynamic systems.
However, the authors acknowledge that LogicGame is not exhaustive and may not capture all aspects of rule-based reasoning. Additionally, the performance of LLMs on these tasks may be influenced by factors such as the quality and quantity of training data, the model architecture, and the specific prompting and fine-tuning approaches used.
Further research is needed to explore the generalizability of the LogicGame results, as well as to investigate the underlying cognitive processes and representations that enable (or limit) the rule-based reasoning capabilities of LLMs. Comparative studies with human reasoning and other AI systems, such as symbolic or hybrid approaches, could provide valuable insights into the strengths and weaknesses of different reasoning paradigms.
Conclusion
The LogicGame benchmark presented in this paper represents an important contribution to the field of AI research. By evaluating the rule-based reasoning abilities of LLMs, it helps uncover the capabilities and limitations of these models in a domain that is crucial for many real-world applications, such as strategic decision-making, planning, and problem-solving.
The insights gained from the LogicGame evaluation can inform the development of more advanced AI systems that can engage in complex reasoning and extract meaningful insights from textual descriptions of rule-based scenarios. This, in turn, could lead to improvements in areas like game AI, automated decision-making, and human-AI collaboration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LogicGame: Benchmarking Rule-Based Reasoning Abilities of Large Language Models
Jiayi Gui, Yiming Liu, Jiale Cheng, Xiaotao Gu, Xiao Liu, Hongning Wang, Yuxiao Dong, Jie Tang, Minlie Huang
Large Language Models (LLMs) have demonstrated notable capabilities across various tasks, showcasing complex problem-solving abilities. Understanding and executing complex rules, along with multi-step planning, are fundamental to logical reasoning and critical for practical LLM agents and decision-making systems. However, evaluating LLMs as effective rule-based executors and planners remains underexplored. In this paper, we introduce LogicGame, a novel benchmark designed to evaluate the comprehensive rule understanding, execution, and planning capabilities of LLMs. Unlike traditional benchmarks, LogicGame provides diverse games that contain a series of rules with an initial state, requiring models to comprehend and apply predefined regulations to solve problems. We create simulated scenarios in which models execute or plan operations to achieve specific outcomes. These game scenarios are specifically designed to distinguish logical reasoning from mere knowledge by relying exclusively on predefined rules. This separation allows for a pure assessment of rule-based reasoning capabilities. The evaluation considers not only final outcomes but also intermediate steps, providing a comprehensive assessment of model performance. Moreover, these intermediate steps are deterministic and can be automatically verified. LogicGame defines game scenarios with varying difficulty levels, from simple rule applications to complex reasoning chains, in order to offer a precise evaluation of model performance on rule understanding and multi-step execution. Utilizing LogicGame, we test various LLMs and identify notable shortcomings in their rule-based logical reasoning abilities.
Read more9/6/2024
0
GTBench: Uncovering the Strategic Reasoning Limitations of LLMs via Game-Theoretic Evaluations
Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, Lichao Sun, Elias Stengel-Eskin, Mohit Bansal, Tianlong Chen, Kaidi Xu
As Large Language Models (LLMs) are integrated into critical real-world applications, their strategic and logical reasoning abilities are increasingly crucial. This paper evaluates LLMs' reasoning abilities in competitive environments through game-theoretic tasks, e.g., board and card games that require pure logic and strategic reasoning to compete with opponents. We first propose GTBench, a language-driven environment composing 10 widely recognized tasks, across a comprehensive game taxonomy: complete versus incomplete information, dynamic versus static, and probabilistic versus deterministic scenarios. Then, we (1) Characterize the game-theoretic reasoning of LLMs; and (2) Perform LLM-vs.-LLM competitions as reasoning evaluation. We observe that (1) LLMs have distinct behaviors regarding various gaming scenarios; for example, LLMs fail in complete and deterministic games yet they are competitive in probabilistic gaming scenarios; (2) Most open-source LLMs, e.g., CodeLlama-34b-Instruct and Llama-2-70b-chat, are less competitive than commercial LLMs, e.g., GPT-4, in complex games, yet the recently released Llama-3-70b-Instruct makes up for this shortcoming. In addition, code-pretraining greatly benefits strategic reasoning, while advanced reasoning methods such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) do not always help. We further characterize the game-theoretic properties of LLMs, such as equilibrium and Pareto Efficiency in repeated games. Detailed error profiles are provided for a better understanding of LLMs' behavior. We hope our research provides standardized protocols and serves as a foundation to spur further explorations in the strategic reasoning of LLMs.
Read more6/11/2024

0
GameBench: Evaluating Strategic Reasoning Abilities of LLM Agents
Anthony Costarelli, Mat Allen, Roman Hauksson, Grace Sodunke, Suhas Hariharan, Carlson Cheng, Wenjie Li, Joshua Clymer, Arjun Yadav
Large language models have demonstrated remarkable few-shot performance on many natural language understanding tasks. Despite several demonstrations of using large language models in complex, strategic scenarios, there lacks a comprehensive framework for evaluating agents' performance across various types of reasoning found in games. To address this gap, we introduce GameBench, a cross-domain benchmark for evaluating strategic reasoning abilities of LLM agents. We focus on 9 different game environments, where each covers at least one axis of key reasoning skill identified in strategy games, and select games for which strategy explanations are unlikely to form a significant portion of models' pretraining corpuses. Our evaluations use GPT-3 and GPT-4 in their base form along with two scaffolding frameworks designed to enhance strategic reasoning ability: Chain-of-Thought (CoT) prompting and Reasoning Via Planning (RAP). Our results show that none of the tested models match human performance, and at worst GPT-4 performs worse than random action. CoT and RAP both improve scores but not comparable to human levels.
Read more7/23/2024
0
LogicBench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
Mihir Parmar, Nisarg Patel, Neeraj Varshney, Mutsumi Nakamura, Man Luo, Santosh Mashetty, Arindam Mitra, Chitta Baral
Recently developed large language models (LLMs) have been shown to perform remarkably well on a wide range of language understanding tasks. But, can they really reason over the natural language? This question has been receiving significant research attention and many reasoning skills such as commonsense, numerical, and qualitative have been studied. However, the crucial skill pertaining to 'logical reasoning' has remained underexplored. Existing work investigating this reasoning ability of LLMs has focused only on a couple of inference rules (such as modus ponens and modus tollens) of propositional and first-order logic. Addressing the above limitation, we comprehensively evaluate the logical reasoning ability of LLMs on 25 different reasoning patterns spanning over propositional, first-order, and non-monotonic logics. To enable systematic evaluation, we introduce LogicBench, a natural language question-answering dataset focusing on the use of a single inference rule. We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well on LogicBench; especially, they struggle with instances involving complex reasoning and negations. Furthermore, they sometimes overlook contextual information necessary for reasoning to arrive at the correct conclusion. We believe that our work and findings facilitate future research for evaluating and enhancing the logical reasoning ability of LLMs. Data and code are available at https://github.com/Mihir3009/LogicBench.
Read more6/7/2024