Self-Selected Attention Span for Accelerating Large Language Model Inference
2404.09336
0
0
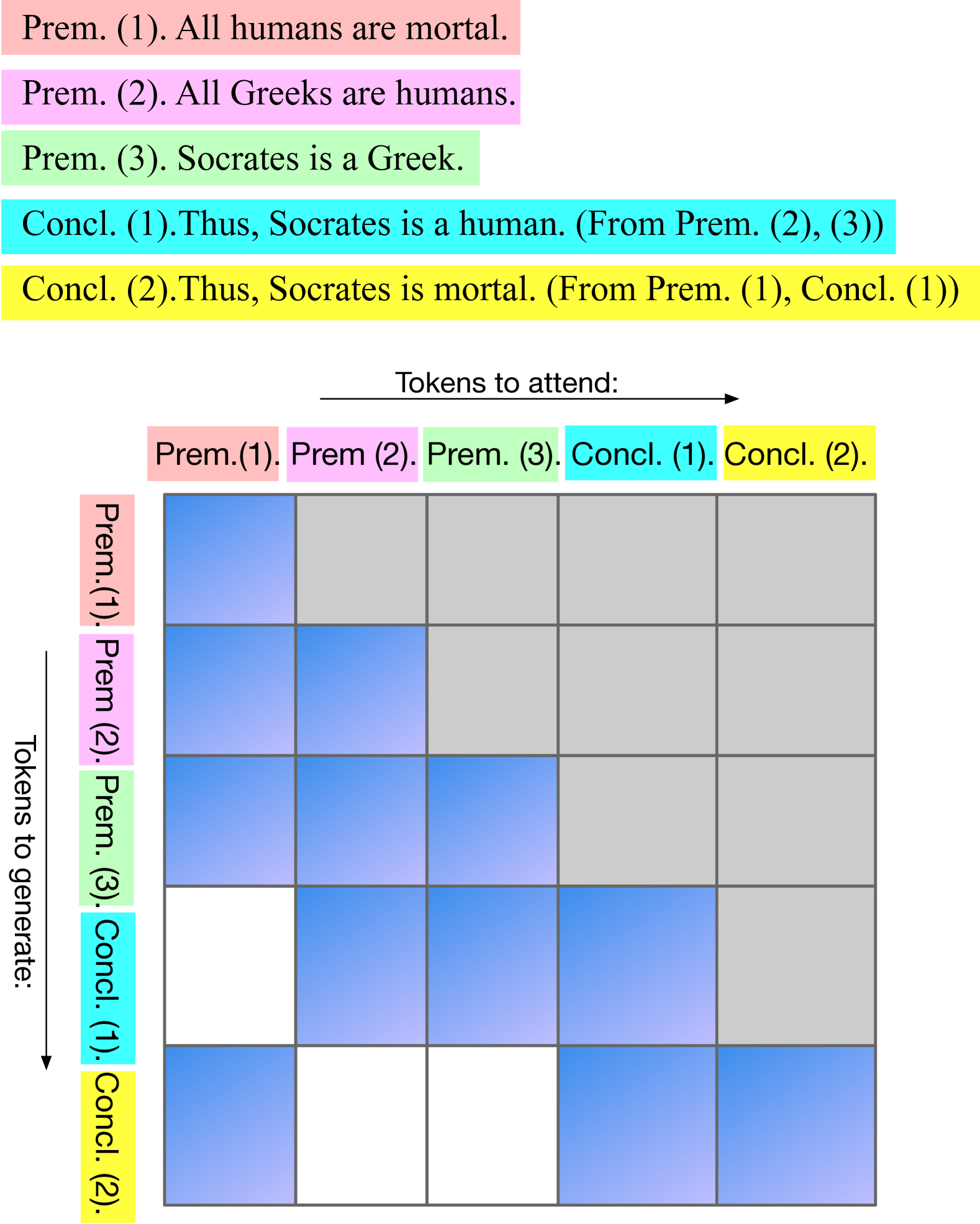
Abstract
Large language models (LLMs) can solve challenging tasks. However, their inference computation on modern GPUs is highly inefficient due to the increasing number of tokens they must attend to as they generate new ones. To address this inefficiency, we capitalize on LLMs' problem-solving capabilities to optimize their own inference-time efficiency. We demonstrate with two specific tasks: (a) evaluating complex arithmetic expressions and (b) summarizing news articles. For both tasks, we create custom datasets to fine-tune an LLM. The goal of fine-tuning is twofold: first, to make the LLM learn to solve the evaluation or summarization task, and second, to train it to identify the minimal attention spans required for each step of the task. As a result, the fine-tuned model is able to convert these self-identified minimal attention spans into sparse attention masks on-the-fly during inference. We develop a custom CUDA kernel to take advantage of the reduced context to attend to. We demonstrate that using this custom CUDA kernel improves the throughput of LLM inference by 28%. Our work presents an end-to-end demonstration showing that training LLMs to self-select their attention spans speeds up autoregressive inference in solving real-world tasks.
Create account to get full access
Overview
- This paper explores new techniques to improve the efficiency and effectiveness of large language models (LLMs).
- Key contributions include attention-driven reasoning, efficient infinite context, and attention sinks.
- The research aims to enhance inference efficiency and leverage supervised knowledge to improve LLM performance.
Plain English Explanation
This paper focuses on making large language models (LLMs) more efficient and effective. LLMs are powerful AI systems that can understand and generate human language, but they can be computationally intensive and resource-heavy.
The researchers propose several new techniques to address this. One is "attention-driven reasoning," which allows the model to focus on the most relevant parts of its input when generating output, rather than having to consider everything equally. This can make the model more efficient.
Another technique is "efficient infinite context," which enables the model to remember and use information from much longer sequences of text, without needing to store and process all of that data at once. This can help the model maintain coherence and context over longer interactions.
The researchers also introduce "attention sinks," which are a way to selectively discard less important information as the model processes text, further improving efficiency.
Overall, the goal of this research is to enhance the inference efficiency of LLMs and leverage supervised knowledge to make them more powerful and useful, while also reducing their computational demands.
Technical Explanation
The paper proposes several novel techniques to improve the efficiency and effectiveness of large language models (LLMs):
Attention-driven reasoning allows the model to focus its "attention" on the most relevant parts of its input when generating output, rather than treating all parts of the input equally. This selective attention mechanism can make the model more computationally efficient.
Efficient infinite context enables the model to maintain coherence and context over much longer sequences of text, without needing to store and process all of that data at once. This helps the model better understand the full context of a given input.
The researchers also introduce attention sinks, which are a way to selectively discard less important information as the model processes text, further improving efficiency.
Additionally, the paper explores ways to enhance the inference efficiency of LLMs and leverage supervised knowledge to improve their performance.
Critical Analysis
The paper presents a thoughtful and comprehensive set of techniques to address some of the key challenges facing large language models, such as computational efficiency and maintaining contextual awareness.
One potential limitation is that the evaluation of these techniques is primarily done on synthetic or controlled tasks, rather than real-world applications. It would be valuable to see how well these approaches translate to more complex, open-ended language understanding and generation tasks.
Additionally, the paper does not delve deeply into potential ethical or societal implications of these efficiency improvements. As LLMs become more powerful and widely deployed, it will be important to consider how these models can be developed and used responsibly.
Overall, this research represents a valuable contribution to the field of language model optimization. The proposed techniques have the potential to significantly improve the practicality and impact of large language models, though further investigation and real-world testing would be beneficial.
Conclusion
This paper introduces several innovative techniques to enhance the efficiency and effectiveness of large language models (LLMs). By leveraging attention-driven reasoning, efficient infinite context, and attention sinks, the researchers demonstrate ways to make LLMs more computationally efficient while maintaining their powerful language understanding and generation capabilities.
These advancements have the potential to unlock new applications and use cases for LLMs, as they become more practical to deploy in a wider range of settings. The research also highlights the importance of continuing to optimize the performance of these complex AI systems, in order to maximize their positive impact while addressing potential concerns around ethics and responsible development.
Overall, this paper represents an important step forward in the ongoing effort to make large language models more versatile, efficient, and beneficial for society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
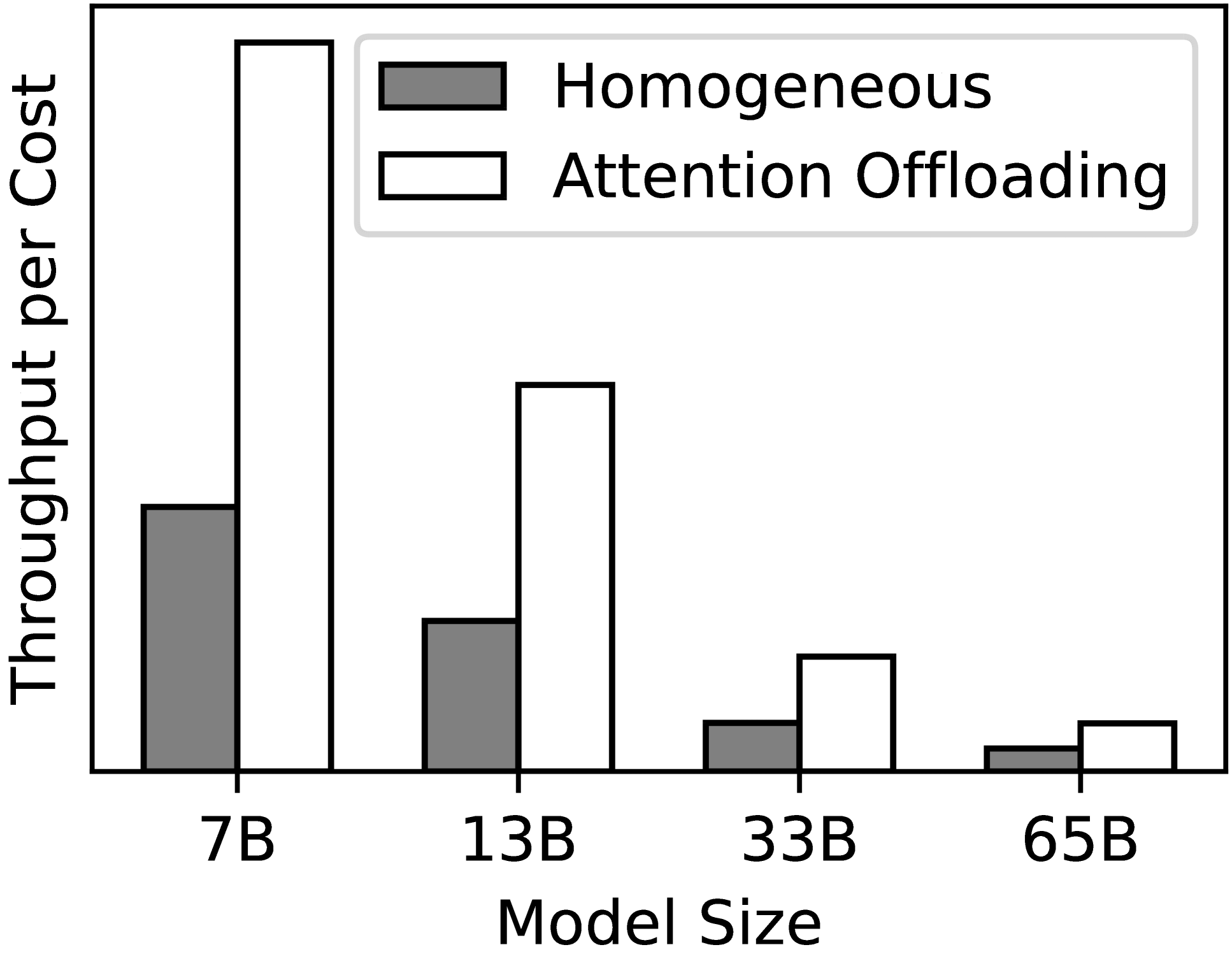
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
0
0
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
5/6/2024
Attention-Driven Reasoning: Unlocking the Potential of Large Language Models
Bingli Liao, Danilo Vasconcellos Vargas
0
0
Large Language Models (LLMs) are pivotal in advancing natural language processing but often struggle with complex reasoning tasks due to inefficient attention distributions. In this paper, we explore the effect of increased computed tokens on LLM performance and introduce a novel method for extending computed tokens in the Chain-of-Thought (CoT) process, utilizing attention mechanism optimization. By fine-tuning an LLM on a domain-specific, highly structured dataset, we analyze attention patterns across layers, identifying inefficiencies caused by non-semantic tokens with outlier high attention scores. To address this, we propose an algorithm that emulates early layer attention patterns across downstream layers to re-balance skewed attention distributions and enhance knowledge abstraction. Our findings demonstrate that our approach not only facilitates a deeper understanding of the internal dynamics of LLMs but also significantly improves their reasoning capabilities, particularly in non-STEM domains. Our study lays the groundwork for further innovations in LLM design, aiming to create more powerful, versatile, and responsible models capable of tackling a broad range of real-world applications.
6/26/2024
🤯
Efficient LLM inference solution on Intel GPU
Hui Wu, Yi Gan, Feng Yuan, Jing Ma, Wei Zhu, Yutao Xu, Hong Zhu, Yuhua Zhu, Xiaoli Liu, Jinghui Gu, Peng Zhao
0
0
Transformer based Large Language Models (LLMs) have been widely used in many fields, and the efficiency of LLM inference becomes hot topic in real applications. However, LLMs are usually complicatedly designed in model structure with massive operations and perform inference in the auto-regressive mode, making it a challenging task to design a system with high efficiency. In this paper, we propose an efficient LLM inference solution with low latency and high throughput. Firstly, we simplify the LLM decoder layer by fusing data movement and element-wise operations to reduce the memory access frequency and lower system latency. We also propose a segment KV cache policy to keep key/value of the request and response tokens in separate physical memory for effective device memory management, helping enlarge the runtime batch size and improve system throughput. A customized Scaled-Dot-Product-Attention kernel is designed to match our fusion policy based on the segment KV cache solution. We implement our LLM inference solution on Intel GPU and publish it publicly. Compared with the standard HuggingFace implementation, the proposed solution achieves up to 7x lower token latency and 27x higher throughput for some popular LLMs on Intel GPU.
6/26/2024

Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention
Qianchao Zhu, Jiangfei Duan, Chang Chen, Siran Liu, Xiuhong Li, Guanyu Feng, Xin Lv, Huanqi Cao, Xiao Chuanfu, Xingcheng Zhang, Dahua Lin, Chao Yang
0
0
Large language models (LLMs) now support extremely long context windows, but the quadratic complexity of vanilla attention results in significantly long Time-to-First-Token (TTFT) latency. Existing approaches to address this complexity require additional pretraining or finetuning, and often sacrifice model accuracy. In this paper, we first provide both theoretical and empirical foundations for near-lossless sparse attention. We find dynamically capturing head-specific sparse patterns at runtime with low overhead is crucial. To address this, we propose SampleAttention, an adaptive structured and near-lossless sparse attention. Leveraging observed significant sparse patterns, SampleAttention attends to a fixed percentage of adjacent tokens to capture local window patterns, and employs a two-stage query-guided key-value filtering approach, which adaptively select a minimum set of key-values with low overhead, to capture column stripe patterns. Comprehensive evaluations show that SampleAttention can seamlessly replace vanilla attention in off-the-shelf LLMs with nearly no accuracy loss, and reduces TTFT by up to $2.42times$ compared with FlashAttention.
7/1/2024