Long Context is Not Long at All: A Prospector of Long-Dependency Data for Large Language Models
2405.17915
0
0

Abstract
Long-context modeling capabilities are important for large language models (LLMs) in various applications. However, directly training LLMs with long context windows is insufficient to enhance this capability since some training samples do not exhibit strong semantic dependencies across long contexts. In this study, we propose a data mining framework textbf{ProLong} that can assign each training sample with a long dependency score, which can be used to rank and filter samples that are more advantageous for enhancing long-context modeling abilities in LLM training. Specifically, we first use delta perplexity scores to measure the textit{Dependency Strength} between text segments in a given document. Then we refine this metric based on the textit{Dependency Distance} of these segments to incorporate spatial relationships across long-contexts. Final results are calibrated with a textit{Dependency Specificity} metric to prevent trivial dependencies introduced by repetitive patterns. Moreover, a random sampling approach is proposed to optimize the computational efficiency of ProLong. Comprehensive experiments on multiple benchmarks indicate that ProLong effectively identifies documents that carry long dependencies and LLMs trained on these documents exhibit significantly enhanced long-context modeling capabilities.
Create account to get full access
Overview
- This paper explores the challenges that large language models (LLMs) face in learning long-range dependencies, which are important for understanding and generating coherent long-form text.
- The authors introduce a new dataset called XLDollar2DollarBench that tests LLMs' ability to understand and reason about extremely long contexts.
- The paper also presents InfLLM, a training-free technique to improve LLMs' long-context understanding, and Context Learning, a framework to explore long-context modeling in depth.
Plain English Explanation
The paper focuses on a key challenge for large language models (LLMs): their ability to understand and reason about long stretches of text. LLMs are very good at processing and generating short pieces of text, but they can struggle when faced with longer, more complex contexts.
To explore this issue, the researchers created a new dataset called XLDollar2DollarBench, which contains very long passages of text that LLMs must try to understand and reason about. This helps expose the limitations of current LLMs when it comes to long-range dependencies.
The paper also introduces two new techniques to help LLMs handle long contexts better. The first, called InfLLM, is a training-free approach that can improve an LLM's ability to extrapolate from short contexts to longer ones. The second, called Context Learning, provides a framework for exploring long-context modeling in more depth.
By developing new datasets and techniques, the researchers aim to push the boundaries of what LLMs are capable of when it comes to understanding and generating coherent long-form text. This could have important implications for applications like summarization, question answering, and creative writing, where the ability to maintain context over long stretches of text is crucial.
Technical Explanation
The paper begins by highlighting the limitations of current large language models (LLMs) when it comes to learning long-range dependencies, which are essential for understanding and generating coherent long-form text. To address this, the authors introduce a new dataset called XLDollar2DollarBench that tests LLMs' ability to reason about extremely long contexts.
The paper then presents InfLLM, a training-free technique that can improve an LLM's ability to extrapolate from short contexts to longer ones. This is a novel approach that does not require retraining the model, making it more efficient and accessible.
Additionally, the authors introduce Context Learning, a framework for exploring long-context modeling in depth. This framework provides a structured way to investigate different aspects of long-range dependency learning, such as the impact of context length, the role of attention mechanisms, and the potential benefits of using external knowledge.
The paper also discusses related work, including efforts to extend the context capacity of LLMs and to benchmark long-context understanding.
Critical Analysis
The paper makes a valuable contribution by highlighting the limitations of current LLMs when it comes to long-range dependencies and providing new tools to address this challenge. The XLDollar2DollarBench dataset, in particular, seems like a useful benchmark for testing the boundaries of LLM capabilities.
However, the paper does not address the potential computational and memory constraints that may make it difficult to scale long-context modeling approaches. Additionally, the authors do not discuss the broader implications of their work, such as how improved long-context understanding could benefit real-world applications like summarization, question answering, and creative writing.
Furthermore, the paper could have provided more details on the specific architectural and training choices made for the InfLLM technique, as well as a more thorough evaluation of its performance compared to other approaches.
Overall, the paper presents an interesting and timely exploration of an important challenge in the field of natural language processing, but there are opportunities for further research and analysis to fully understand the implications and limitations of the proposed solutions.
Conclusion
This paper tackles a crucial challenge for large language models: their difficulty in understanding and reasoning about long-range dependencies in text. By introducing new datasets and techniques, the authors aim to push the boundaries of what LLMs can do when it comes to processing and generating coherent long-form text.
The XLDollar2DollarBench dataset, InfLLM method, and Context Learning framework provide valuable tools for researchers and practitioners to explore this important area. While the paper does not address all the potential limitations and implications of this work, it represents a significant step forward in addressing a fundamental constraint of current LLM technology.
As the field of natural language processing continues to evolve, the insights and approaches presented in this paper will likely inform future efforts to develop LLMs that can better handle long-range dependencies and unlock new possibilities for applications that rely on understanding and generating coherent long-form text.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Long-context LLMs Struggle with Long In-context Learning
Tianle Li, Ge Zhang, Quy Duc Do, Xiang Yue, Wenhu Chen
0
0
Large Language Models (LLMs) have made significant strides in handling long sequences. Some models like Gemini could even to be capable of dealing with millions of tokens. However, their performance evaluation has largely been confined to metrics like perplexity and synthetic tasks, which may not fully capture their true abilities in more challenging, real-world scenarios. We introduce a benchmark (LongICLBench) for long in-context learning in extreme-label classification using six datasets with 28 to 174 classes and input lengths from 2K to 50K tokens. Our benchmark requires LLMs to comprehend the entire input to recognize the massive label spaces to make correct predictions. We evaluate on 15 long-context LLMs and find that they perform well on less challenging classification tasks with smaller label space and shorter demonstrations. However, they struggle with more challenging task like Discovery with 174 labels, suggesting a gap in their ability to process long, context-rich sequences. Further analysis reveals a bias towards labels presented later in the sequence and a need for improved reasoning over multiple pieces of information. Our study reveals that long context understanding and reasoning is still a challenging task for the existing LLMs. We believe LongICLBench could serve as a more realistic evaluation for the future long-context LLMs.
6/13/2024
🤔
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, Juanzi Li
0
0
Although large language models (LLMs) demonstrate impressive performance for many language tasks, most of them can only handle texts a few thousand tokens long, limiting their applications on longer sequence inputs, such as books, reports, and codebases. Recent works have proposed methods to improve LLMs' long context capabilities by extending context windows and more sophisticated memory mechanisms. However, comprehensive benchmarks tailored for evaluating long context understanding are lacking. In this paper, we introduce LongBench, the first bilingual, multi-task benchmark for long context understanding, enabling a more rigorous evaluation of long context understanding. LongBench comprises 21 datasets across 6 task categories in both English and Chinese, with an average length of 6,711 words (English) and 13,386 characters (Chinese). These tasks cover key long-text application areas including single-doc QA, multi-doc QA, summarization, few-shot learning, synthetic tasks, and code completion. All datasets in LongBench are standardized into a unified format, allowing for effortless automatic evaluation of LLMs. Upon comprehensive evaluation of 8 LLMs on LongBench, we find that: (1) Commercial model (GPT-3.5-Turbo-16k) outperforms other open-sourced models, but still struggles on longer contexts. (2) Scaled position embedding and fine-tuning on longer sequences lead to substantial improvement on long context understanding. (3) Context compression technique such as retrieval brings improvement for model with weak ability on long contexts, but the performance still lags behind models that have strong long context understanding capability. The code and datasets are available at https://github.com/THUDM/LongBench.
6/21/2024

XL$^2$Bench: A Benchmark for Extremely Long Context Understanding with Long-range Dependencies
Xuanfan Ni, Hengyi Cai, Xiaochi Wei, Shuaiqiang Wang, Dawei Yin, Piji Li
0
0
Large Language Models (LLMs) have demonstrated remarkable performance across diverse tasks but are constrained by their small context window sizes. Various efforts have been proposed to expand the context window to accommodate even up to 200K input tokens. Meanwhile, building high-quality benchmarks with much longer text lengths and more demanding tasks to provide comprehensive evaluations is of immense practical interest to facilitate long context understanding research of LLMs. However, prior benchmarks create datasets that ostensibly cater to long-text comprehension by expanding the input of traditional tasks, which falls short to exhibit the unique characteristics of long-text understanding, including long dependency tasks and longer text length compatible with modern LLMs' context window size. In this paper, we introduce a benchmark for extremely long context understanding with long-range dependencies, XL$^2$Bench, which includes three scenarios: Fiction Reading, Paper Reading, and Law Reading, and four tasks of increasing complexity: Memory Retrieval, Detailed Understanding, Overall Understanding, and Open-ended Generation, covering 27 subtasks in English and Chinese. It has an average length of 100K+ words (English) and 200K+ characters (Chinese). Evaluating six leading LLMs on XL$^2$Bench, we find that their performance significantly lags behind human levels. Moreover, the observed decline in performance across both the original and enhanced datasets underscores the efficacy of our approach to mitigating data contamination.
4/9/2024
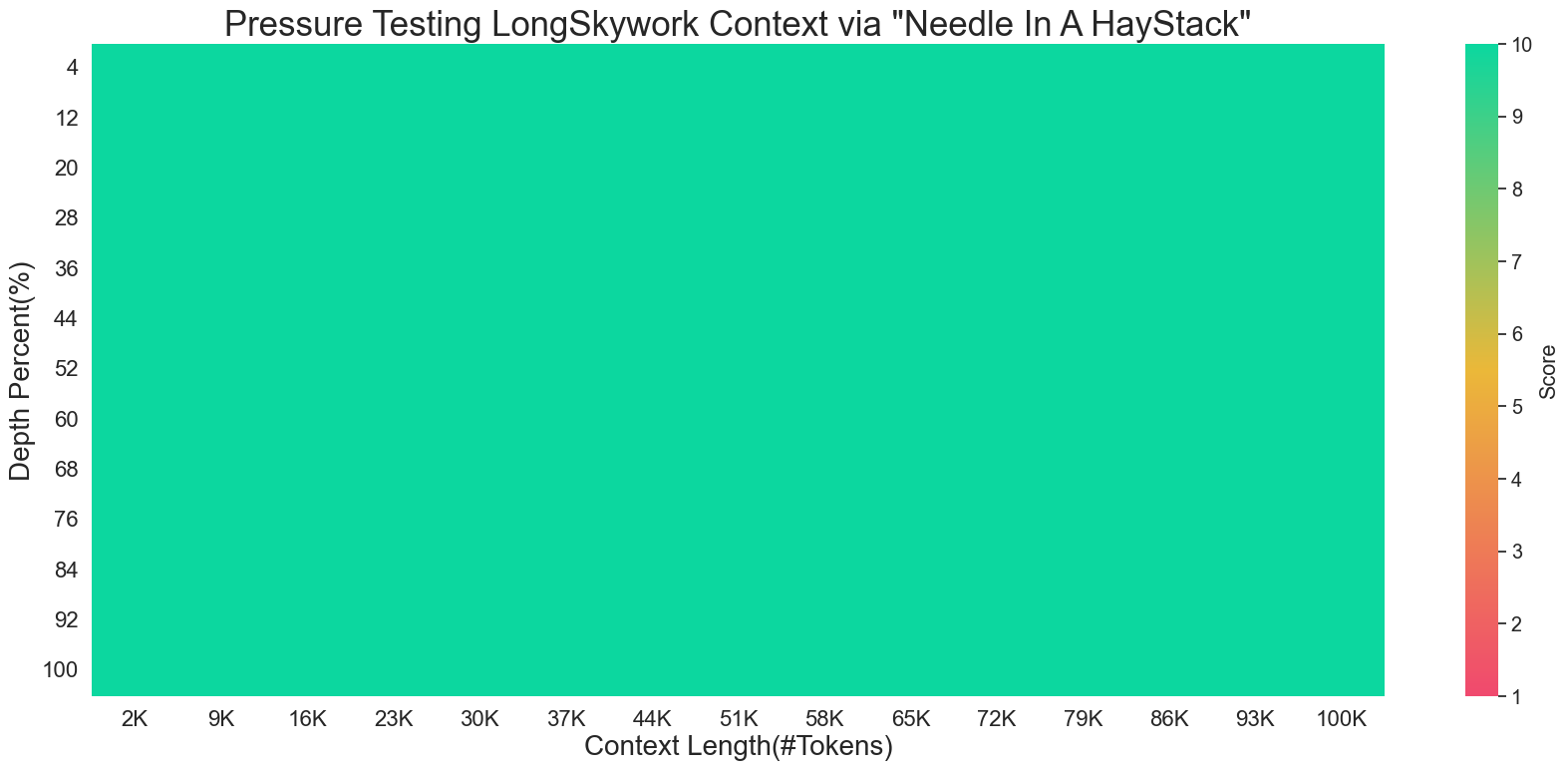
LongSkywork: A Training Recipe for Efficiently Extending Context Length in Large Language Models
Liang Zhao, Tianwen Wei, Liang Zeng, Cheng Cheng, Liu Yang, Peng Cheng, Lijie Wang, Chenxia Li, Xuejie Wu, Bo Zhu, Yimeng Gan, Rui Hu, Shuicheng Yan, Han Fang, Yahui Zhou
0
0
We introduce LongSkywork, a long-context Large Language Model (LLM) capable of processing up to 200,000 tokens. We provide a training recipe for efficiently extending context length of LLMs. We identify that the critical element in enhancing long-context processing capability is to incorporate a long-context SFT stage following the standard SFT stage. A mere 200 iterations can convert the standard SFT model into a long-context model. To reduce the effort in collecting and annotating data for long-context language modeling, we develop two novel methods for creating synthetic data. These methods are applied during the continual pretraining phase as well as the Supervised Fine-Tuning (SFT) phase, greatly enhancing the training efficiency of our long-context LLMs. Our findings suggest that synthetic long-context SFT data can surpass the performance of data curated by humans to some extent. LongSkywork achieves outstanding performance on a variety of long-context benchmarks. In the Needle test, a benchmark for long-context information retrieval, our models achieved perfect accuracy across multiple context spans. Moreover, in realistic application scenarios, LongSkywork-13B demonstrates performance on par with Claude2.1, the leading long-context model, underscoring the effectiveness of our proposed methods.
6/4/2024