Long Context Transfer from Language to Vision
2406.16852
0
0

Abstract
Video sequences offer valuable temporal information, but existing large multimodal models (LMMs) fall short in understanding extremely long videos. Many works address this by reducing the number of visual tokens using visual resamplers. Alternatively, in this paper, we approach this problem from the perspective of the language model. By simply extrapolating the context length of the language backbone, we enable LMMs to comprehend orders of magnitude more visual tokens without any video training. We call this phenomenon long context transfer and carefully ablate its properties. To effectively measure LMMs' ability to generalize to long contexts in the vision modality, we develop V-NIAH (Visual Needle-In-A-Haystack), a purely synthetic long vision benchmark inspired by the language model's NIAH test. Our proposed Long Video Assistant (LongVA) can process 2000 frames or over 200K visual tokens without additional complexities. With its extended context length, LongVA achieves state-of-the-art performance on Video-MME among 7B-scale models by densely sampling more input frames. Our work is open-sourced at https://github.com/EvolvingLMMs-Lab/LongVA.
Create account to get full access
Overview
- This paper explores the concept of "long context transfer" from language to vision, which aims to enable vision models to leverage the rich contextual information present in large language models.
- The researchers propose a novel architecture called Long-VLM that efficiently transfers long-range contextual knowledge from language to vision tasks.
- The model is evaluated on various vision-language benchmarks, demonstrating significant performance improvements over existing approaches, especially in tasks that require understanding long-range visual-linguistic relationships.
Plain English Explanation
The paper focuses on a way to help vision models (such as those used for image recognition) take advantage of the extensive knowledge and context that is present in large language models. Language models are trained on vast amounts of text data and can understand the meaning and relationships between words in a very sophisticated way.
The researchers developed a new model architecture called Long-VLM that is able to efficiently transfer this rich contextual knowledge from language to vision tasks. This allows vision models to better understand the broader context and meaning behind what they are seeing, rather than just recognizing individual objects or features.
For example, a vision model enhanced with this long-context transfer could look at an image of a kitchen and not just identify the stove, cabinets, and other objects, but also understand the overall function and purpose of the kitchen space. This deeper understanding can then be applied to improve performance on various vision-language tasks, such as image captioning, visual question answering, and video understanding.
The paper demonstrates that this Long-VLM approach significantly outperforms existing methods, especially on tasks that require comprehending long-range visual-linguistic relationships. This represents an important advance in bridging the gap between language and vision models, with potential applications in areas like robotics, autonomous driving, and multimedia analysis.
Technical Explanation
The paper introduces a novel architecture called Long-VLM that enables efficient transfer of long-range contextual knowledge from large language models to vision tasks. The key components of the architecture include:
- A Vision Transformer that encodes visual inputs into a sequence of visual tokens.
- A Language Transformer that encodes textual inputs into a sequence of language tokens.
- A Cross-Modal Transformer that learns to fuse and propagate information between the visual and language tokens, allowing the vision model to leverage the rich contextual knowledge from the language model.
- An Efficient Memory Bank that selectively stores and retrieves relevant contextual information to further enhance the cross-modal interaction.
The researchers evaluate Long-VLM on various vision-language benchmarks, including Image-Text Retrieval, Visual Question Answering, and Video Understanding. The results demonstrate significant performance improvements over existing state-of-the-art methods, especially on tasks that require understanding long-range visual-linguistic relationships, such as Leveraging Visual Tokens for Extended Text Contexts.
Critical Analysis
The paper provides a comprehensive and well-designed study on the potential of leveraging large language models to enhance vision tasks. The Long-VLM architecture is novel and demonstrates the ability to effectively transfer contextual knowledge from language to vision in an efficient manner.
One potential limitation of the research is the reliance on relatively narrow benchmarks to evaluate performance. While the results are impressive, it would be valuable to see how the model generalizes to a broader range of real-world vision-language applications, particularly in dynamic and complex environments.
Additionally, the paper does not deeply explore the specific mechanisms by which the Long-VLM architecture is able to extract and transfer contextual knowledge. A more detailed analysis of the inner workings of the model could provide valuable insights for future research in this area.
Overall, this paper represents an important step forward in bridging the gap between language and vision models, and the Long-VLM architecture demonstrates the potential for significant performance improvements in a variety of vision-language tasks.
Conclusion
The paper introduces a novel architecture called Long-VLM that enables efficient transfer of long-range contextual knowledge from large language models to vision tasks. The researchers demonstrate that this approach leads to significant performance improvements on various vision-language benchmarks, particularly in tasks that require understanding of long-range visual-linguistic relationships.
This work represents an important advancement in the field of multimodal learning, as it bridges the gap between language and vision models and allows vision models to leverage the rich contextual information present in large language models. The potential applications of this technology span a wide range of domains, from robotics and autonomous driving to multimedia analysis and beyond.
Overall, the Long-VLM architecture provides a promising direction for future research in multimodal learning and has the potential to drive significant progress in the field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LongVLM: Efficient Long Video Understanding via Large Language Models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, Bohan Zhuang
0
0
Empowered by Large Language Models (LLMs), recent advancements in VideoLLMs have driven progress in various video understanding tasks. These models encode video representations through pooling or query aggregation over a vast number of visual tokens, making computational and memory costs affordable. Despite successfully providing an overall comprehension of video content, existing VideoLLMs still face challenges in achieving detailed understanding in videos due to overlooking local information in long-term videos. To tackle this challenge, we introduce LongVLM, a straightforward yet powerful VideoLLM for long video understanding, building upon the observation that long videos often consist of sequential key events, complex actions, and camera movements. Our approach proposes to decompose long videos into multiple short-term segments and encode local features for each local segment via a hierarchical token merging module. These features are concatenated in temporal order to maintain the storyline across sequential short-term segments. Additionally, we propose to integrate global semantics into each local feature to enhance context understanding. In this way, we encode video representations that incorporate both local and global information, enabling the LLM to generate comprehensive responses for long-term videos. Experimental results on the VideoChatGPT benchmark and zero-shot video question-answering datasets demonstrate the superior capabilities of our model over the previous state-of-the-art methods. Qualitative examples demonstrate that our model produces more precise responses for long videos understanding. Code will be available at https://github.com/ziplab/LongVLM.
4/11/2024

Losing Visual Needles in Image Haystacks: Vision Language Models are Easily Distracted in Short and Long Contexts
Aditya Sharma, Michael Saxon, William Yang Wang
0
0
We present LoCoVQA, a dynamic benchmark generator for evaluating long-context extractive reasoning in vision language models (VLMs). LoCoVQA augments test examples for mathematical reasoning, VQA, and character recognition tasks with increasingly long visual contexts composed of both in-distribution and out-of-distribution distractor images. Across these tasks, a diverse set of VLMs rapidly lose performance as the visual context length grows, often exhibiting a striking logarithmic decay trend. This test assesses how well VLMs can ignore irrelevant information when answering queries -- a task that is quite easy for language models (LMs) in the text domain -- demonstrating that current state-of-the-art VLMs lack this essential capability for many long-context applications.
7/4/2024
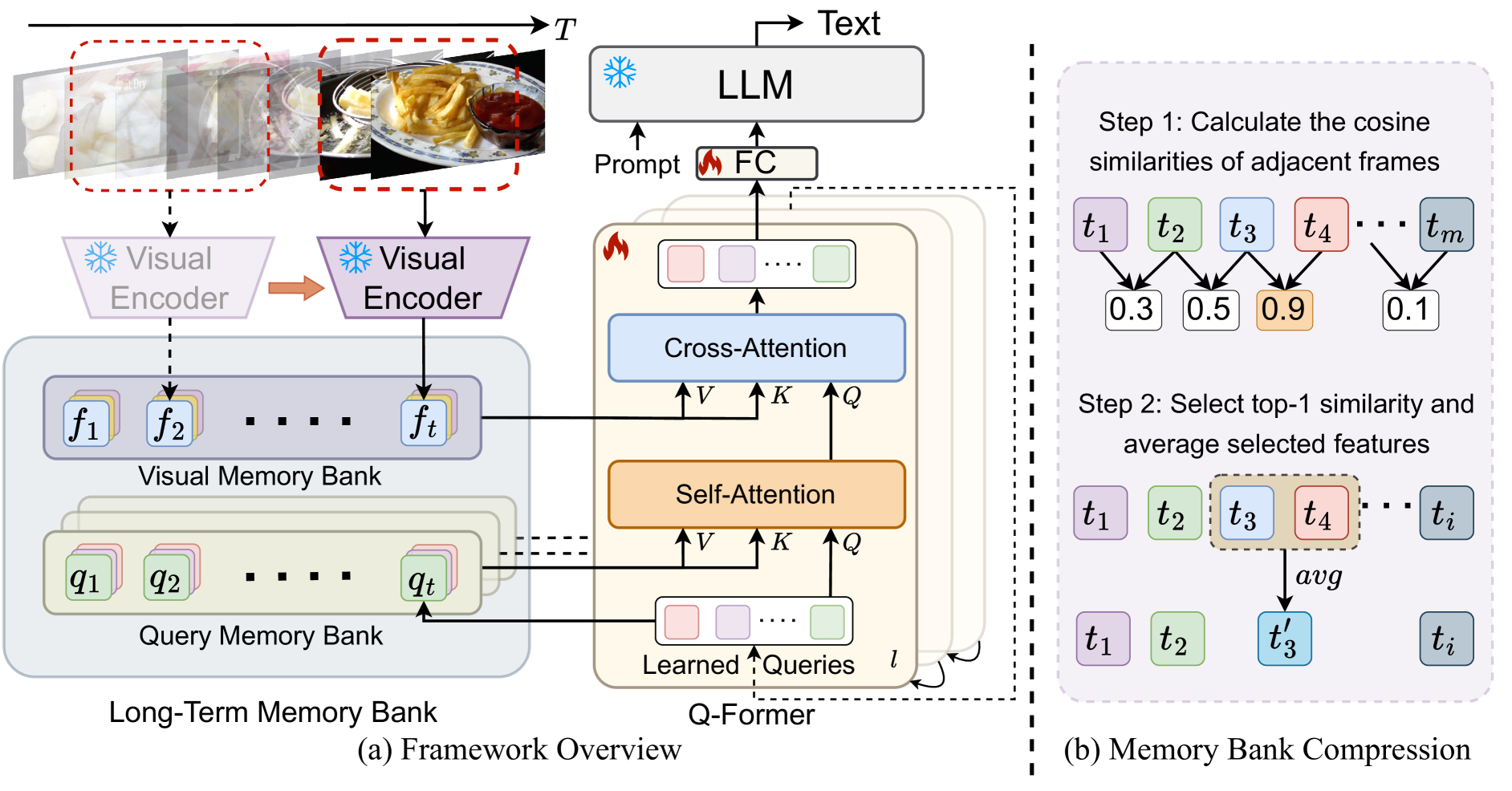
MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, Ser-Nam Lim
0
0
With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
4/9/2024

Streaming Long Video Understanding with Large Language Models
Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Shuangrui Ding, Dahua Lin, Jiaqi Wang
0
0
This paper presents VideoStreaming, an advanced vision-language large model (VLLM) for video understanding, that capably understands arbitrary-length video with a constant number of video tokens streamingly encoded and adaptively selected. The challenge of video understanding in the vision language area mainly lies in the significant computational burden caused by the great number of tokens extracted from long videos. Previous works rely on sparse sampling or frame compression to reduce tokens. However, such approaches either disregard temporal information in a long time span or sacrifice spatial details, resulting in flawed compression. To address these limitations, our VideoStreaming has two core designs: Memory-Propagated Streaming Encoding and Adaptive Memory Selection. The Memory-Propagated Streaming Encoding architecture segments long videos into short clips and sequentially encodes each clip with a propagated memory. In each iteration, we utilize the encoded results of the preceding clip as historical memory, which is integrated with the current clip to distill a condensed representation that encapsulates the video content up to the current timestamp. After the encoding process, the Adaptive Memory Selection strategy selects a constant number of question-related memories from all the historical memories and feeds them into the LLM to generate informative responses. The question-related selection reduces redundancy within the memories, enabling efficient and precise video understanding. Meanwhile, the disentangled video extraction and reasoning design allows the LLM to answer different questions about a video by directly selecting corresponding memories, without the need to encode the whole video for each question. Our model achieves superior performance and higher efficiency on long video benchmarks, showcasing precise temporal comprehension for detailed question answering.
5/28/2024