Look, Listen, and Answer: Overcoming Biases for Audio-Visual Question Answering
2404.12020
0
0

Abstract
Audio-Visual Question Answering (AVQA) is a complex multi-modal reasoning task, demanding intelligent systems to accurately respond to natural language queries based on audio-video input pairs. Nevertheless, prevalent AVQA approaches are prone to overlearning dataset biases, resulting in poor robustness. Furthermore, current datasets may not provide a precise diagnostic for these methods. To tackle these challenges, firstly, we propose a novel dataset, textit{MUSIC-AVQA-R}, crafted in two steps: rephrasing questions within the test split of a public dataset (textit{MUSIC-AVQA}) and subsequently introducing distribution shifts to split questions. The former leads to a large, diverse test space, while the latter results in a comprehensive robustness evaluation on rare, frequent, and overall questions. Secondly, we propose a robust architecture that utilizes a multifaceted cycle collaborative debiasing strategy to overcome bias learning. Experimental results show that this architecture achieves state-of-the-art performance on both datasets, especially obtaining a significant improvement of 9.32% on the proposed dataset. Extensive ablation experiments are conducted on these two datasets to validate the effectiveness of the debiasing strategy. Additionally, we highlight the limited robustness of existing multi-modal QA methods through the evaluation on our dataset.
Create account to get full access
Overview
- This paper investigates biases in audio-visual question answering (AVQA) models and proposes techniques to overcome them.
- AVQA models aim to answer questions about images and audio, but can be prone to biases that lead to suboptimal performance.
- The researchers explore methods to quantify and mitigate these biases, with the goal of improving the robustness and reliability of AVQA systems.
Plain English Explanation
The paper looks at a type of artificial intelligence (AI) system called an audio-visual question answering (AVQA) model. These models are designed to answer questions about images and audio clips. However, the researchers found that these models can sometimes be biased, meaning they may not perform as well as they should.
To fix this, the researchers developed ways to measure and reduce the biases in AVQA models. By understanding the biases, they can improve the models so they are more reliable and accurate when answering questions about images and audio. This is important because these AVQA models could be used in real-world applications, like helping people with disabilities or analyzing medical images and sounds. Reducing biases makes the models more trustworthy and useful.
Technical Explanation
The paper focuses on the problem of biases in audio-visual question answering (AVQA) models. AVQA is a task where models must answer questions about both the visual and audio content of a given input. The researchers found that these models can be prone to biases, meaning they may perform better on certain types of questions or inputs due to shortcuts or flaws in their training.
To address this, the authors propose methods to quantify and mitigate these biases. They introduce new evaluation datasets and metrics to measure biases in AVQA models, and then develop techniques to reduce these biases, such as encouraging the models to rely on both visual and audio cues rather than just one modality.
The paper also explores using auxiliary tasks to improve the models' general audio-visual understanding, which can help overcome biases. Overall, the goal is to make AVQA systems more robust and reliable for real-world applications.
Critical Analysis
The paper provides a comprehensive analysis of biases in AVQA models and proposes several effective techniques to mitigate these issues. However, the authors acknowledge that their work is limited to a specific dataset and model architecture, and further research is needed to generalize the findings.
Additionally, the paper does not deeply explore the underlying causes of the observed biases, which could provide valuable insights for developing more robust AVQA systems. Investigating the model architecture, training data, or other factors that contribute to these biases could lead to more fundamental solutions.
Another potential concern is the reliance on auxiliary tasks to improve general audio-visual understanding. While this approach shows promise, the authors do not fully address the potential tradeoffs or challenges in effectively integrating these auxiliary tasks into the primary AVQA objective.
Conclusion
This paper makes important contributions to the field of audio-visual question answering by identifying and addressing biases in AVQA models. The proposed methods for quantifying and mitigating these biases are a significant step forward in improving the robustness and reliability of these systems.
The insights gained from this research could have broad implications for other multimodal AI applications, particularly those involving complex inputs and outputs. Continued efforts to understand and overcome biases in these systems will be crucial as they become more widely deployed in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
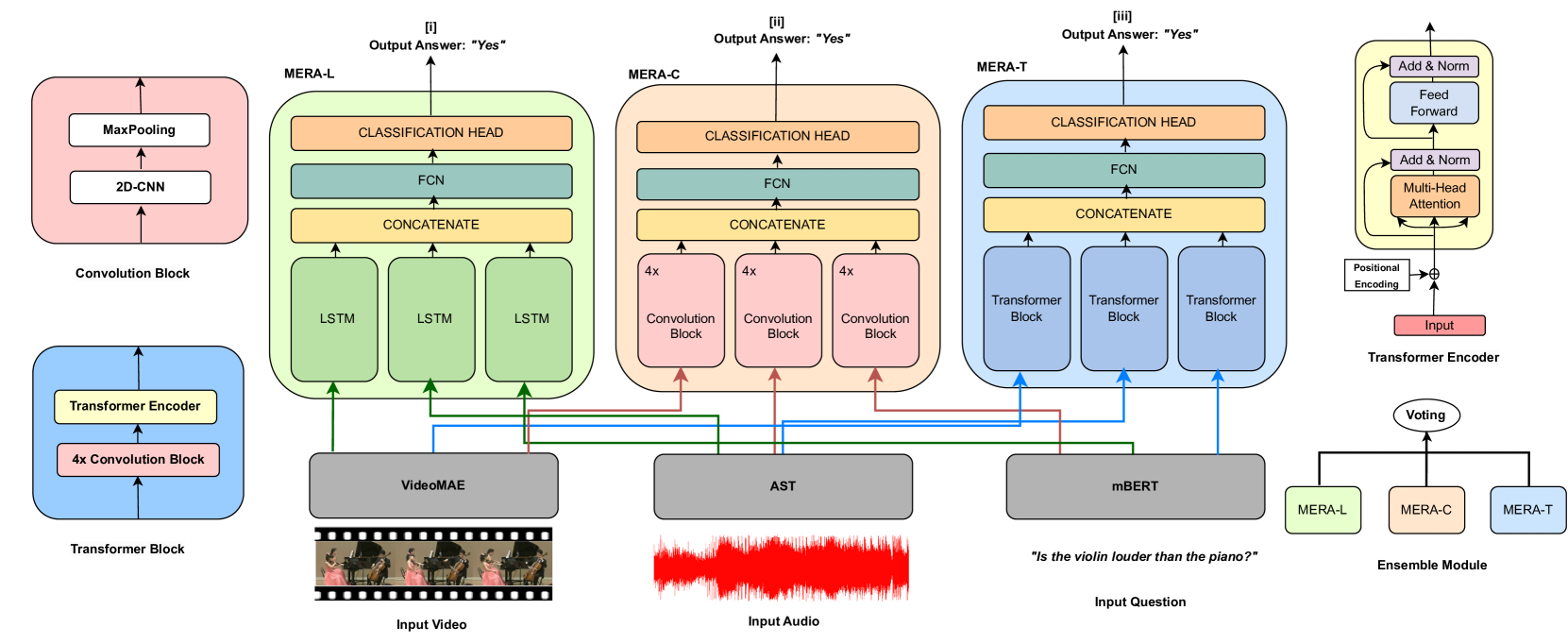
Towards Multilingual Audio-Visual Question Answering
Orchid Chetia Phukan, Priyabrata Mallick, Swarup Ranjan Behera, Aalekhya Satya Narayani, Arun Balaji Buduru, Rajesh Sharma
0
0
In this paper, we work towards extending Audio-Visual Question Answering (AVQA) to multilingual settings. Existing AVQA research has predominantly revolved around English and replicating it for addressing AVQA in other languages requires a substantial allocation of resources. As a scalable solution, we leverage machine translation and present two multilingual AVQA datasets for eight languages created from existing benchmark AVQA datasets. This prevents extra human annotation efforts of collecting questions and answers manually. To this end, we propose, MERA framework, by leveraging state-of-the-art (SOTA) video, audio, and textual foundation models for AVQA in multiple languages. We introduce a suite of models namely MERA-L, MERA-C, MERA-T with varied model architectures to benchmark the proposed datasets. We believe our work will open new research directions and act as a reference benchmark for future works in multilingual AVQA.
6/14/2024

Selectively Answering Visual Questions
Julian Martin Eisenschlos, Hern'an Maina, Guido Ivetta, Luciana Benotti
0
0
Recently, large multi-modal models (LMMs) have emerged with the capacity to perform vision tasks such as captioning and visual question answering (VQA) with unprecedented accuracy. Applications such as helping the blind or visually impaired have a critical need for precise answers. It is specially important for models to be well calibrated and be able to quantify their uncertainty in order to selectively decide when to answer and when to abstain or ask for clarifications. We perform the first in-depth analysis of calibration methods and metrics for VQA with in-context learning LMMs. Studying VQA on two answerability benchmarks, we show that the likelihood score of visually grounded models is better calibrated than in their text-only counterparts for in-context learning, where sampling based methods are generally superior, but no clear winner arises. We propose Avg BLEU, a calibration score combining the benefits of both sampling and likelihood methods across modalities.
6/4/2024

CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
David Romero, Chenyang Lyu, Haryo Akbarianto Wibowo, Teresa Lynn, Injy Hamed, Aditya Nanda Kishore, Aishik Mandal, Alina Dragonetti, Artem Abzaliev, Atnafu Lambebo Tonja, Bontu Fufa Balcha, Chenxi Whitehouse, Christian Salamea, Dan John Velasco, David Ifeoluwa Adelani, David Le Meur, Emilio Villa-Cueva, Fajri Koto, Fauzan Farooqui, Frederico Belcavello, Ganzorig Batnasan, Gisela Vallejo, Grainne Caulfield, Guido Ivetta, Haiyue Song, Henok Biadglign Ademtew, Hern'an Maina, Holy Lovenia, Israel Abebe Azime, Jan Christian Blaise Cruz, Jay Gala, Jiahui Geng, Jesus-German Ortiz-Barajas, Jinheon Baek, Jocelyn Dunstan, Laura Alonso Alemany, Kumaranage Ravindu Yasas Nagasinghe, Luciana Benotti, Luis Fernando D'Haro, Marcelo Viridiano, Marcos Estecha-Garitagoitia, Maria Camila Buitrago Cabrera, Mario Rodr'iguez-Cantelar, M'elanie Jouitteau, Mihail Mihaylov, Mohamed Fazli Mohamed Imam, Muhammad Farid Adilazuarda, Munkhjargal Gochoo, Munkh-Erdene Otgonbold, Naome Etori, Olivier Niyomugisha, Paula M'onica Silva, Pranjal Chitale, Raj Dabre, Rendi Chevi, Ruochen Zhang, Ryandito Diandaru, Samuel Cahyawijaya, Santiago G'ongora, Soyeong Jeong, Sukannya Purkayastha, Tatsuki Kuribayashi, Thanmay Jayakumar, Tiago Timponi Torrent, Toqeer Ehsan, Vladimir Araujo, Yova Kementchedjhieva, Zara Burzo, Zheng Wei Lim, Zheng Xin Yong, Oana Ignat, Joan Nwatu, Rada Mihalcea, Thamar Solorio, Alham Fikri Aji
0
0
Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
6/11/2024

Precision Empowers, Excess Distracts: Visual Question Answering With Dynamically Infused Knowledge In Language Models
Manas Jhalani, Annervaz K M, Pushpak Bhattacharyya
0
0
In the realm of multimodal tasks, Visual Question Answering (VQA) plays a crucial role by addressing natural language questions grounded in visual content. Knowledge-Based Visual Question Answering (KBVQA) advances this concept by adding external knowledge along with images to respond to questions. We introduce an approach for KBVQA, augmenting the existing vision-language transformer encoder-decoder (OFA) model. Our main contribution involves enhancing questions by incorporating relevant external knowledge extracted from knowledge graphs, using a dynamic triple extraction method. We supply a flexible number of triples from the knowledge graph as context, tailored to meet the requirements for answering the question. Our model, enriched with knowledge, demonstrates an average improvement of 4.75% in Exact Match Score over the state-of-the-art on three different KBVQA datasets. Through experiments and analysis, we demonstrate that furnishing variable triples for each question improves the reasoning capabilities of the language model in contrast to supplying a fixed number of triples. This is illustrated even for recent large language models. Additionally, we highlight the model's generalization capability by showcasing its SOTA-beating performance on a small dataset, achieved through straightforward fine-tuning.
6/17/2024