Lookahead Exploration with Neural Radiance Representation for Continuous Vision-Language Navigation
2404.01943
0
0

Abstract
Vision-and-language navigation (VLN) enables the agent to navigate to a remote location following the natural language instruction in 3D environments. At each navigation step, the agent selects from possible candidate locations and then makes the move. For better navigation planning, the lookahead exploration strategy aims to effectively evaluate the agent's next action by accurately anticipating the future environment of candidate locations. To this end, some existing works predict RGB images for future environments, while this strategy suffers from image distortion and high computational cost. To address these issues, we propose the pre-trained hierarchical neural radiance representation model (HNR) to produce multi-level semantic features for future environments, which are more robust and efficient than pixel-wise RGB reconstruction. Furthermore, with the predicted future environmental representations, our lookahead VLN model is able to construct the navigable future path tree and select the optimal path via efficient parallel evaluation. Extensive experiments on the VLN-CE datasets confirm the effectiveness of our method.
Create account to get full access
Overview
- This paper proposes a new method for continuous vision-language navigation tasks, where an agent must navigate through an environment while following natural language instructions.
- The key innovations are the use of a neural radiance representation to model the environment, and a lookahead exploration strategy to plan optimal navigation paths.
- The authors demonstrate the effectiveness of their approach on several benchmark datasets, achieving state-of-the-art performance.
Plain English Explanation
The paper focuses on a type of AI task called continuous vision-language navigation. Imagine you're a robot, and someone gives you instructions like "Go to the kitchen, then turn left and go to the living room." Your goal is to navigate through the environment by following those verbal directions.
The new method in this paper has two main parts. First, it uses a neural network to create a detailed 3D model of the environment, capturing things like the shape and appearance of objects. This allows the robot to "imagine" what's around the next corner before actually going there.
Second, the robot uses this model to plan out the best path to take, exploring different possible routes and choosing the one that seems most likely to reach the goal. It looks several steps ahead, rather than just reacting to the immediate surroundings.
By combining these two innovations - the detailed environment model and the lookahead planning - the robot is able to navigate more efficiently and accurately than previous approaches. This could be useful for applications like home robots, self-driving cars, or virtual assistants that need to understand and follow natural language instructions.
Technical Explanation
The core of the proposed approach is a neural radiance representation that models the environment as a continuous 3D scene. This representation captures the appearance and geometry of the environment in a compact neural network, allowing the agent to "imagine" what lies ahead without directly observing it.
To navigate efficiently, the agent uses a lookahead exploration strategy that plans multiple steps into the future. It leverages the neural radiance representation to simulate different paths and choose the one that is most likely to reach the goal location while following the natural language instructions.
The authors evaluate their method on several standard continuous vision-language navigation benchmarks, including Room-to-Room, Room-Across-Room, and REVERIE. They show that their approach significantly outperforms previous state-of-the-art methods, demonstrating the benefits of the neural radiance representation and lookahead exploration.
Critical Analysis
The authors acknowledge that their method is limited to static environments, and does not account for dynamic or changing elements. Additionally, the neural radiance representation may struggle with highly complex or detailed environments that exceed the capacity of the underlying neural network.
While the results on benchmark datasets are impressive, it would be valuable to see the method evaluated in more diverse and realistic environments to better understand its practical applicability. Additionally, the computational and memory requirements of the neural radiance representation and lookahead exploration may limit its deployment in resource-constrained settings.
Overall, the paper presents a compelling approach that advances the state-of-the-art in continuous vision-language navigation. The combination of a powerful environment representation and a strategic planning algorithm is a promising direction for further research in this area.
Conclusion
This paper introduces a novel method for continuous vision-language navigation that leverages a neural radiance representation to model the environment and a lookahead exploration strategy to plan efficient navigation paths. The authors demonstrate the effectiveness of their approach on several benchmark datasets, achieving state-of-the-art performance.
The key innovations of this work - the neural radiance representation and the lookahead exploration strategy - have the potential to significantly improve the capabilities of AI systems that need to understand and follow natural language instructions in complex, 3D environments. While the method has some limitations, it represents an important step forward in the field of continuous vision-language navigation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Vision-and-Language Navigation Generative Pretrained Transformer
Wen Hanlin
0
0
In the Vision-and-Language Navigation (VLN) field, agents are tasked with navigating real-world scenes guided by linguistic instructions. Enabling the agent to adhere to instructions throughout the process of navigation represents a significant challenge within the domain of VLN. To address this challenge, common approaches often rely on encoders to explicitly record past locations and actions, increasing model complexity and resource consumption. Our proposal, the Vision-and-Language Navigation Generative Pretrained Transformer (VLN-GPT), adopts a transformer decoder model (GPT2) to model trajectory sequence dependencies, bypassing the need for historical encoding modules. This method allows for direct historical information access through trajectory sequence, enhancing efficiency. Furthermore, our model separates the training process into offline pre-training with imitation learning and online fine-tuning with reinforcement learning. This distinction allows for more focused training objectives and improved performance. Performance assessments on the VLN dataset reveal that VLN-GPT surpasses complex state-of-the-art encoder-based models.
5/28/2024
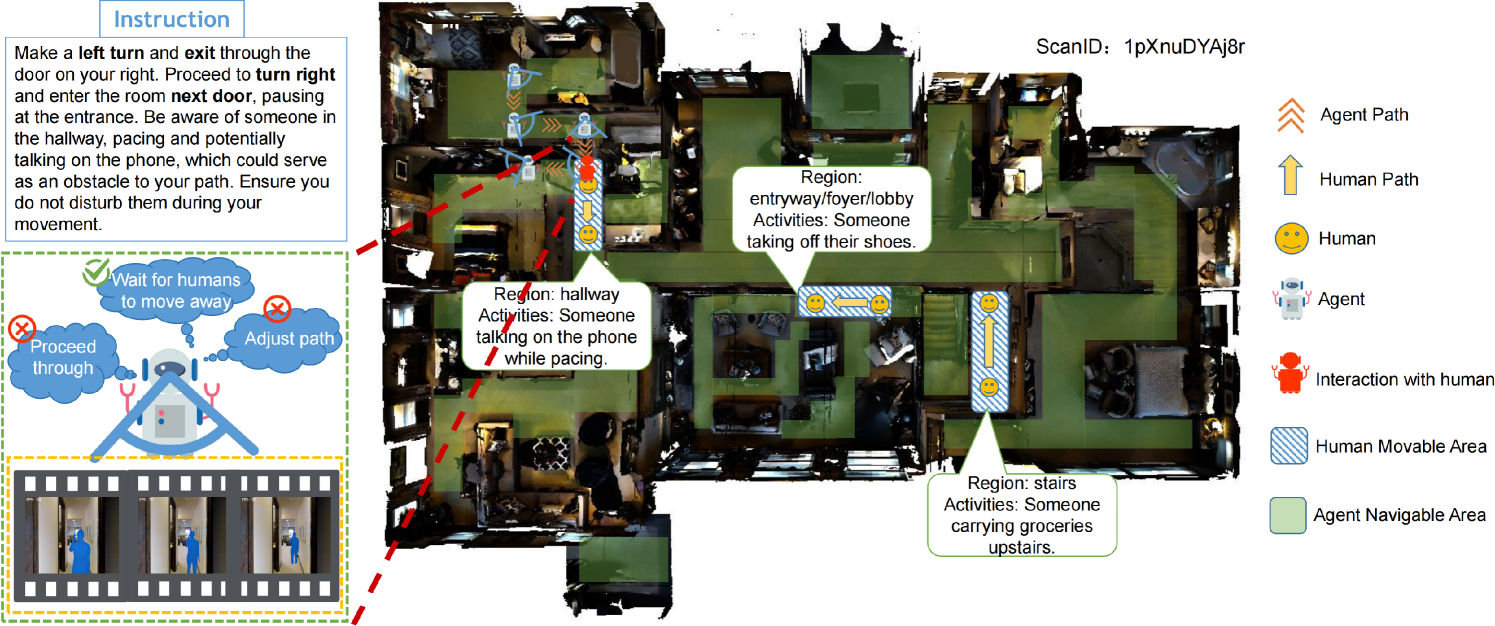
Human-Aware Vision-and-Language Navigation: Bridging Simulation to Reality with Dynamic Human Interactions
Minghan Li, Heng Li, Zhi-Qi Cheng, Yifei Dong, Yuxuan Zhou, Jun-Yan He, Qi Dai, Teruko Mitamura, Alexander G. Hauptmann
0
0
Vision-and-Language Navigation (VLN) aims to develop embodied agents that navigate based on human instructions. However, current VLN frameworks often rely on static environments and optimal expert supervision, limiting their real-world applicability. To address this, we introduce Human-Aware Vision-and-Language Navigation (HA-VLN), extending traditional VLN by incorporating dynamic human activities and relaxing key assumptions. We propose the Human-Aware 3D (HA3D) simulator, which combines dynamic human activities with the Matterport3D dataset, and the Human-Aware Room-to-Room (HA-R2R) dataset, extending R2R with human activity descriptions. To tackle HA-VLN challenges, we present the Expert-Supervised Cross-Modal (VLN-CM) and Non-Expert-Supervised Decision Transformer (VLN-DT) agents, utilizing cross-modal fusion and diverse training strategies for effective navigation in dynamic human environments. A comprehensive evaluation, including metrics considering human activities, and systematic analysis of HA-VLN's unique challenges, underscores the need for further research to enhance HA-VLN agents' real-world robustness and adaptability. Ultimately, this work provides benchmarks and insights for future research on embodied AI and Sim2Real transfer, paving the way for more realistic and applicable VLN systems in human-populated environments.
6/28/2024

NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, He Wang
0
0
Vision-and-language navigation (VLN) stands as a key research problem of Embodied AI, aiming at enabling agents to navigate in unseen environments following linguistic instructions. In this field, generalization is a long-standing challenge, either to out-of-distribution scenes or from Sim to Real. In this paper, we propose NaVid, a video-based large vision language model (VLM), to mitigate such a generalization gap. NaVid makes the first endeavor to showcase the capability of VLMs to achieve state-of-the-art level navigation performance without any maps, odometers, or depth inputs. Following human instruction, NaVid only requires an on-the-fly video stream from a monocular RGB camera equipped on the robot to output the next-step action. Our formulation mimics how humans navigate and naturally gets rid of the problems introduced by odometer noises, and the Sim2Real gaps from map or depth inputs. Moreover, our video-based approach can effectively encode the historical observations of robots as spatio-temporal contexts for decision making and instruction following. We train NaVid with 510k navigation samples collected from continuous environments, including action-planning and instruction-reasoning samples, along with 763k large-scale web data. Extensive experiments show that NaVid achieves state-of-the-art performance in simulation environments and the real world, demonstrating superior cross-dataset and Sim2Real transfer. We thus believe our proposed VLM approach plans the next step for not only the navigation agents but also this research field.
5/28/2024
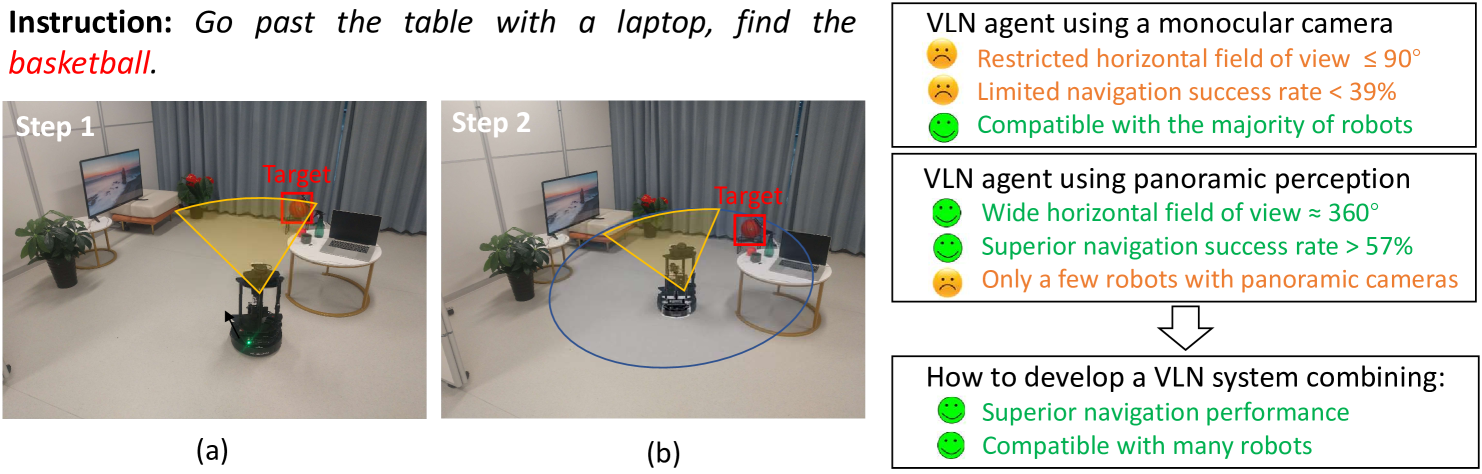
Sim-to-Real Transfer via 3D Feature Fields for Vision-and-Language Navigation
Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, Shuqiang Jiang
0
0
Vision-and-language navigation (VLN) enables the agent to navigate to a remote location in 3D environments following the natural language instruction. In this field, the agent is usually trained and evaluated in the navigation simulators, lacking effective approaches for sim-to-real transfer. The VLN agents with only a monocular camera exhibit extremely limited performance, while the mainstream VLN models trained with panoramic observation, perform better but are difficult to deploy on most monocular robots. For this case, we propose a sim-to-real transfer approach to endow the monocular robots with panoramic traversability perception and panoramic semantic understanding, thus smoothly transferring the high-performance panoramic VLN models to the common monocular robots. In this work, the semantic traversable map is proposed to predict agent-centric navigable waypoints, and the novel view representations of these navigable waypoints are predicted through the 3D feature fields. These methods broaden the limited field of view of the monocular robots and significantly improve navigation performance in the real world. Our VLN system outperforms previous SOTA monocular VLN methods in R2R-CE and RxR-CE benchmarks within the simulation environments and is also validated in real-world environments, providing a practical and high-performance solution for real-world VLN.
6/21/2024