Sim-to-Real Transfer via 3D Feature Fields for Vision-and-Language Navigation
2406.09798
0
0
Abstract
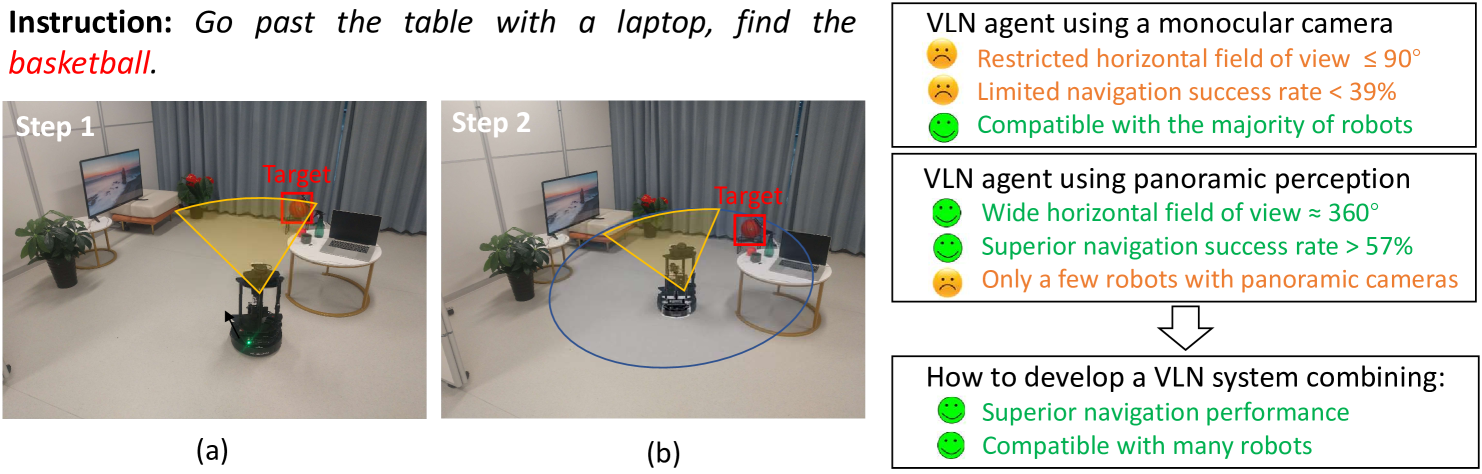
Vision-and-language navigation (VLN) enables the agent to navigate to a remote location in 3D environments following the natural language instruction. In this field, the agent is usually trained and evaluated in the navigation simulators, lacking effective approaches for sim-to-real transfer. The VLN agents with only a monocular camera exhibit extremely limited performance, while the mainstream VLN models trained with panoramic observation, perform better but are difficult to deploy on most monocular robots. For this case, we propose a sim-to-real transfer approach to endow the monocular robots with panoramic traversability perception and panoramic semantic understanding, thus smoothly transferring the high-performance panoramic VLN models to the common monocular robots. In this work, the semantic traversable map is proposed to predict agent-centric navigable waypoints, and the novel view representations of these navigable waypoints are predicted through the 3D feature fields. These methods broaden the limited field of view of the monocular robots and significantly improve navigation performance in the real world. Our VLN system outperforms previous SOTA monocular VLN methods in R2R-CE and RxR-CE benchmarks within the simulation environments and is also validated in real-world environments, providing a practical and high-performance solution for real-world VLN.
Create account to get full access
Overview
- This paper presents a novel approach for transferring learned skills from simulated environments to real-world settings for a task called Vision-and-Language Navigation (VLN).
- The key idea is to use 3D feature fields, which capture spatial and semantic information about the environment, to bridge the gap between simulation and reality.
- The proposed method outperforms previous state-of-the-art approaches on several VLN benchmarks, demonstrating the effectiveness of the 3D feature field-based transfer learning technique.
Plain English Explanation
The paper explores a way to take what an AI system learns in a simulated environment and apply it to the real world. The task they focus on is Vision-and-Language Navigation (VLN), where an AI system needs to navigate through an environment based on instructions given in natural language.
The core of their approach is to use something called "3D feature fields" to bridge the gap between the simulated training environment and the actual real-world setting. These 3D feature fields capture information about the spatial layout and semantic meaning of the environment in a way that can translate across the simulation-to-real world divide.
By using these 3D feature fields, the researchers were able to outperform previous methods that struggled with this "sim-to-real" transfer problem. This suggests that the 3D feature field technique is an effective way to enable AI systems trained in simulation to work well in the real world.
Technical Explanation
The paper proposes a novel approach for sim-to-real transfer in the context of Vision-and-Language Navigation (VLN). The key contribution is the use of 3D feature fields, which encode spatial and semantic information about the environment, to bridge the gap between the simulated training environment and the target real-world setting.
The system first trains on VLN tasks in a simulated environment, learning to navigate based on natural language instructions. Instead of directly transferring the trained model to the real world, the approach extracts 3D feature fields from both the simulation and the real-world data. These feature fields capture low-level visual information, object semantics, and spatial relationships in a consistent 3D format.
The VLN agent is then fine-tuned on the real-world data using the 3D feature fields as input, rather than raw visual observations. This allows the agent to leverage the knowledge gained in simulation while adapting to the nuances of the real-world environment.
The paper evaluates this approach on several VLN benchmarks, including Sim2Real VLN and Room-to-Room, and demonstrates significant improvements over previous state-of-the-art methods that did not utilize the 3D feature field representation.
Critical Analysis
The paper presents a compelling approach to the challenging problem of transferring skills learned in simulation to the real world. The use of 3D feature fields as an intermediate representation is a clever way to capture the relevant spatial and semantic information in a format that can bridge the simulation-to-real gap.
One potential limitation is the reliance on access to 3D data, which may not always be available, especially in the real-world setting. The paper does not explore how the approach would perform if such detailed 3D data were not provided.
Additionally, the experiments are limited to relatively constrained indoor environments. It would be interesting to see how well the 3D feature field-based transfer learning technique generalizes to more complex, unconstrained real-world settings, such as outdoor urban or natural environments.
Further research could also explore the generalizability of the 3D feature field approach to other vision-and-language tasks beyond just navigation, such as grounded language understanding or interactive instruction following.
Conclusion
This paper presents a novel and effective approach for enabling sim-to-real transfer in the context of Vision-and-Language Navigation. By using 3D feature fields to capture the relevant spatial and semantic information about the environment, the proposed method is able to outperform previous state-of-the-art techniques on several VLN benchmarks.
The insights from this research could have significant implications for developing AI systems that can seamlessly operate in the real world after being trained in simulation. This could lead to more efficient and scalable training approaches for a wide range of real-world robotic and navigation tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Human-Aware Vision-and-Language Navigation: Bridging Simulation to Reality with Dynamic Human Interactions
Minghan Li, Heng Li, Zhi-Qi Cheng, Yifei Dong, Yuxuan Zhou, Jun-Yan He, Qi Dai, Teruko Mitamura, Alexander G. Hauptmann
0
0
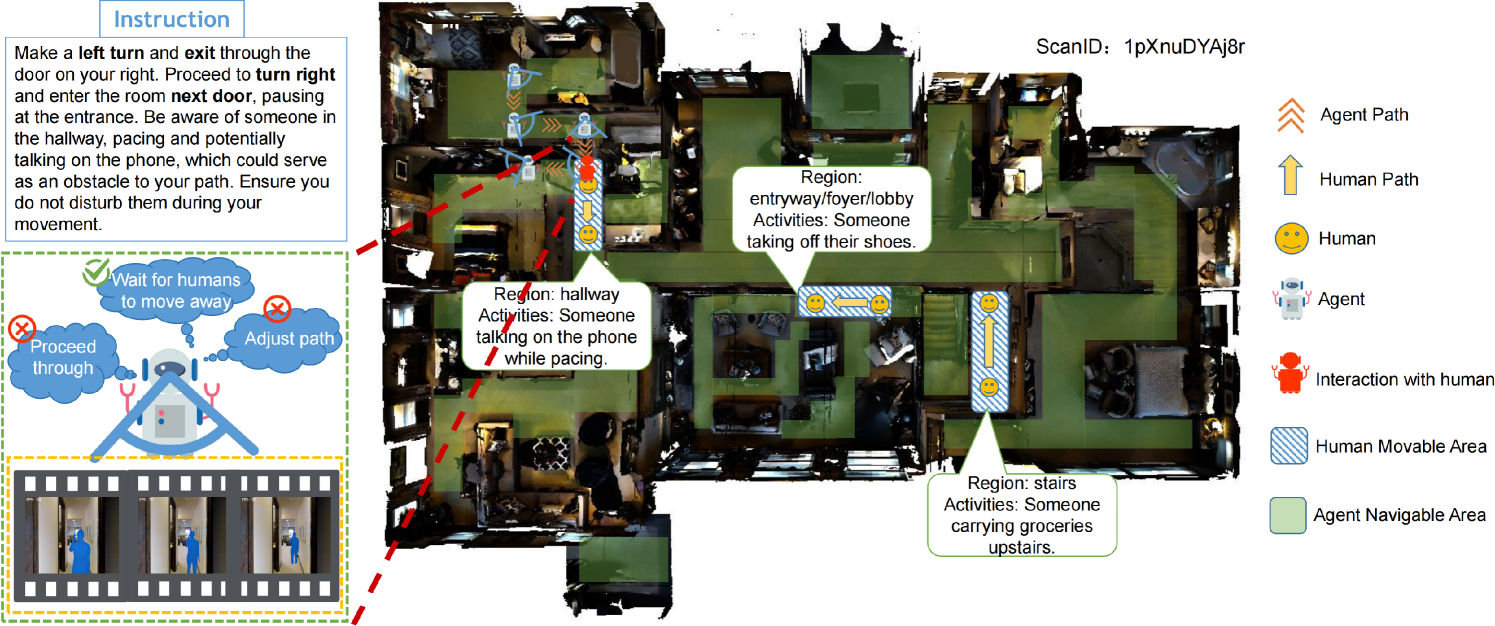
Vision-and-Language Navigation (VLN) aims to develop embodied agents that navigate based on human instructions. However, current VLN frameworks often rely on static environments and optimal expert supervision, limiting their real-world applicability. To address this, we introduce Human-Aware Vision-and-Language Navigation (HA-VLN), extending traditional VLN by incorporating dynamic human activities and relaxing key assumptions. We propose the Human-Aware 3D (HA3D) simulator, which combines dynamic human activities with the Matterport3D dataset, and the Human-Aware Room-to-Room (HA-R2R) dataset, extending R2R with human activity descriptions. To tackle HA-VLN challenges, we present the Expert-Supervised Cross-Modal (VLN-CM) and Non-Expert-Supervised Decision Transformer (VLN-DT) agents, utilizing cross-modal fusion and diverse training strategies for effective navigation in dynamic human environments. A comprehensive evaluation, including metrics considering human activities, and systematic analysis of HA-VLN's unique challenges, underscores the need for further research to enhance HA-VLN agents' real-world robustness and adaptability. Ultimately, this work provides benchmarks and insights for future research on embodied AI and Sim2Real transfer, paving the way for more realistic and applicable VLN systems in human-populated environments.
6/28/2024

NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, He Wang
0
0
Vision-and-language navigation (VLN) stands as a key research problem of Embodied AI, aiming at enabling agents to navigate in unseen environments following linguistic instructions. In this field, generalization is a long-standing challenge, either to out-of-distribution scenes or from Sim to Real. In this paper, we propose NaVid, a video-based large vision language model (VLM), to mitigate such a generalization gap. NaVid makes the first endeavor to showcase the capability of VLMs to achieve state-of-the-art level navigation performance without any maps, odometers, or depth inputs. Following human instruction, NaVid only requires an on-the-fly video stream from a monocular RGB camera equipped on the robot to output the next-step action. Our formulation mimics how humans navigate and naturally gets rid of the problems introduced by odometer noises, and the Sim2Real gaps from map or depth inputs. Moreover, our video-based approach can effectively encode the historical observations of robots as spatio-temporal contexts for decision making and instruction following. We train NaVid with 510k navigation samples collected from continuous environments, including action-planning and instruction-reasoning samples, along with 763k large-scale web data. Extensive experiments show that NaVid achieves state-of-the-art performance in simulation environments and the real world, demonstrating superior cross-dataset and Sim2Real transfer. We thus believe our proposed VLM approach plans the next step for not only the navigation agents but also this research field.
5/28/2024

Vision-and-Language Navigation Generative Pretrained Transformer
Wen Hanlin
0
0
In the Vision-and-Language Navigation (VLN) field, agents are tasked with navigating real-world scenes guided by linguistic instructions. Enabling the agent to adhere to instructions throughout the process of navigation represents a significant challenge within the domain of VLN. To address this challenge, common approaches often rely on encoders to explicitly record past locations and actions, increasing model complexity and resource consumption. Our proposal, the Vision-and-Language Navigation Generative Pretrained Transformer (VLN-GPT), adopts a transformer decoder model (GPT2) to model trajectory sequence dependencies, bypassing the need for historical encoding modules. This method allows for direct historical information access through trajectory sequence, enhancing efficiency. Furthermore, our model separates the training process into offline pre-training with imitation learning and online fine-tuning with reinforcement learning. This distinction allows for more focused training objectives and improved performance. Performance assessments on the VLN dataset reveal that VLN-GPT surpasses complex state-of-the-art encoder-based models.
5/28/2024

Lookahead Exploration with Neural Radiance Representation for Continuous Vision-Language Navigation
Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, Junjie Hu, Ming Jiang, Shuqiang Jiang
0
0
Vision-and-language navigation (VLN) enables the agent to navigate to a remote location following the natural language instruction in 3D environments. At each navigation step, the agent selects from possible candidate locations and then makes the move. For better navigation planning, the lookahead exploration strategy aims to effectively evaluate the agent's next action by accurately anticipating the future environment of candidate locations. To this end, some existing works predict RGB images for future environments, while this strategy suffers from image distortion and high computational cost. To address these issues, we propose the pre-trained hierarchical neural radiance representation model (HNR) to produce multi-level semantic features for future environments, which are more robust and efficient than pixel-wise RGB reconstruction. Furthermore, with the predicted future environmental representations, our lookahead VLN model is able to construct the navigable future path tree and select the optimal path via efficient parallel evaluation. Extensive experiments on the VLN-CE datasets confirm the effectiveness of our method.
4/3/2024